
인덱스(Index)란?
책의 목차처럼 지정한 칼럼을 정렬하여 데이터를 쉽게 찾을 수 있도록 만든 테이블입니다.
-
책의 목차와 같은 개념
-
추가적인 저장공간을 활용해 데이터베이스 테이블의 검색속도를 향상
-
검색속도 향상
-
인덱스를 설정하지 않은 경우, 기본적으로 PK값이 인덱스로 사용
사용법: CREATE INDEX 인덱스명 ON 테이블명(칼럼명)
Index의 구조
해쉬테이블과 B+ Tree구조가 있습니다.
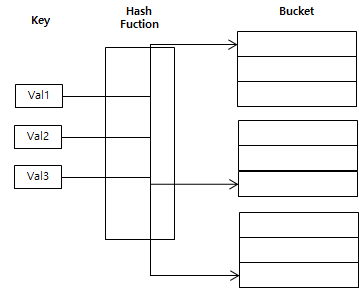
- 해시테이블
- 키 값에 해쉬함수를 적용해 나온 주소값과 매칭하는 기법
- 부등호 연산이 많은 DB에는 효과적이지 않은 방법임
- 해시가 등호(=) 연산에만 특화됐기 때문
- DB의 인덱스 컬럼은 부등호를 이용한 순차 검색 연산이 자주 발생
- B+Tree
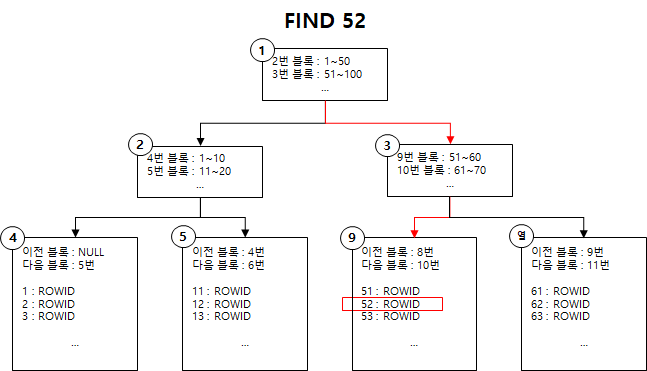
- LinkedList로 연결된 구조
- 연결된 노드를 따라가면서 일치하는 값으로 가서 읽고 일치하지 않는 값이 나오면 즉시 중지
- 부등호 연산에 효율적
- B-Tree의 리프노드들을 LinkedList로 연결해 순차검색을 용이하게 하는 등, B-Tree를 인덱스에 맞게 최적화한 것
Index의 특징
장점
- 테이블을 조회하는 속도와 그에 따른 성능을 향상시킬 수 있다.
- 전반적인 시스템의 부하를 줄일 수 있다.
단점
- 인덱스를 관리하기 위해 DB의 약 10%에 해당하는 저장공간이 필요
- 인덱스를 관리하기 위해 추가 작업이 필요
- 인덱스를 잘못 사용할 경우 오히려 성능이 저하되는 역효과가 발생 가능
※ 인덱스를 모든 속성에 추가하면 성능이 좋아질까?
- 그렇지 않습니다. 데이터베이스에서 조회만 일어난다고 할 때, 모든 속성에 인덱스를 넣게 되면 저장 공간을 많이 차지하게 되며 삽입, 삭제, 갱신이 발생하면 인덱스 테이블은 이 데이터에 대해 재정렬을 다시 수행해야하므로 오히려 성능 저하로 이어지게 된다.
Index를 사용하면 좋은 경우
- 규모가 작지 않은 테이블에 사용하면 조회 속도가 빨라짐
- 연산이 거의 없고 검색을 많이 하는 테이블
- Insert, Update, Delete가 자주 발생하지 않는 컬럼
- where 구문, join문에 자주 사용되는 컬럼
- 데이터의 중복도가 낮은 컬럼
※인덱스 사용만큼 생선된 인덱스 관리도 중요하다. 그래서 사용하지 않는 인덱스는 바로 제거를 해줘야 한다.
클러스터드 인덱스, 넌클러스터드 인덱스
- 클러스터드 인덱스(Clustered Index)
- 데이터를 PK에 따라서 순서대로 저장
- 범위탐색은 빠르지만 테이블 중간에 있는 데이터를 삭제하거나, 삽입할 때 느림
- 넌클러스터드 인덱스(Non-Clustered Index)
- 인덱스와 Hashcode를 이용해 데이터를 저장
- Hashcode 또한 저장해야 하므로 추가 저장공간이 필요
- 데이터를 Insert할 때, 인덱스를 생성해줘야 하는 추가 작업이 필요
[참고]
https://mangkyu.tistory.com/96
https://velog.io/@gillog/SQL-Clustered-Index-Non-Clustered-Index

다음 스텝을 준비하자