JSON 로그 모니터링 및 Slack 알림 자동화 시스템 구축
JSON 로그 모니터링 및 Slack 알림 자동화 시스템 구축
서론
현대 애플리케이션 환경에서 로그 모니터링은 시스템 안정성과 문제 해결에 필수적인 요소입니다. 특히 마이크로서비스 아키텍처와 분산 시스템이 보편화되면서, 여러 서비스에서 생성되는 로그를 효율적으로 수집하고 분석하는 능력은 DevOps 팀에게 중요한 역량이 되었습니다. 이 블로그에서는 Grafana Loki 스택을 활용하여 JSON 형식의 로그를 실시간으로 모니터링하고, 심각도에 따라 Slack 알림을 자동화하는 시스템 구축 경험을 공유합니다.
아키텍처
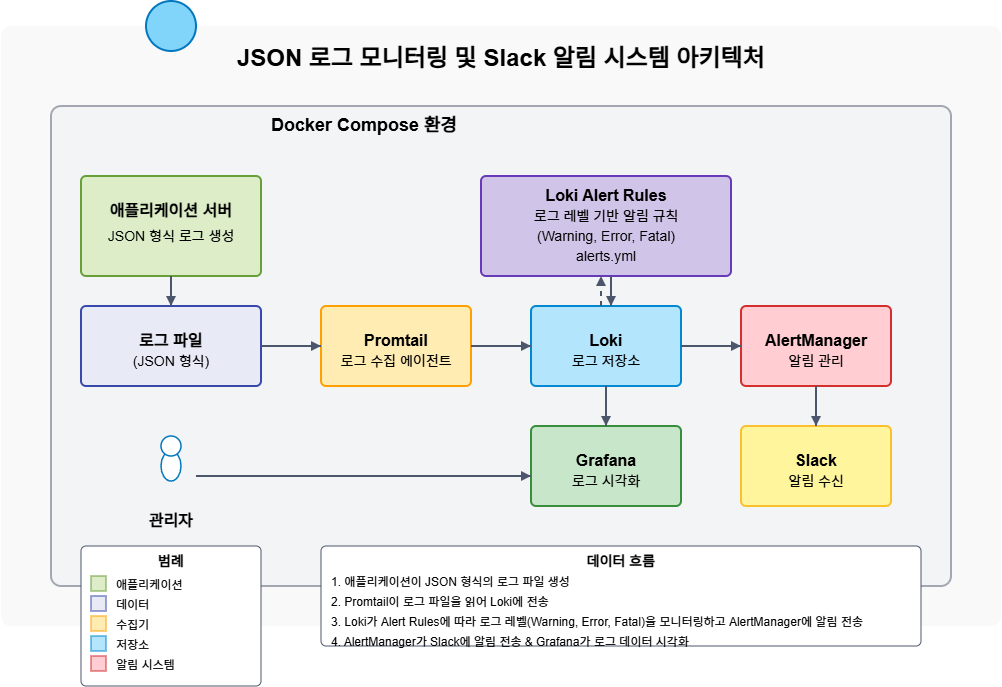
아키텍처 개요
이 시스템은 로그 수집부터 알림 전송까지 완전한 파이프라인을 제공하며, 다음과 같은 주요 구성 요소로 이루어져 있습니다:
- 애플리케이션 서버: JSON 형식의 로그 파일을 생성
- Promtail: 로그 파일을 읽고 파싱하여 Loki로 전송하는 에이전트
- Loki: 로그 저장 및 쿼리 서비스
- Grafana: 로그 데이터 시각화 및 대시보드
- AlertManager: 알림 관리 및 라우팅
- Slack: 알림 수신 및 표시
이 모든 컴포넌트는 Docker Compose를 통해 컨테이너화되어 실행되므로, 환경 간 이식성이 뛰어나고 빠른 배포가 가능합니다.
JSON 로그 모니터링의 장점
JSON 형식 로그를 사용하면 다음과 같은 이점이 있습니다:
- 구조화된 데이터: 키-값 쌍으로 정보가 명확하게 구조화됨
- 쉬운 파싱과 필터링: 필드별 검색 및 필터링이 용이
- 메타데이터 포함: 타임스탬프, 로그 레벨, 소스 컨텍스트 등 다양한 메타데이터 저장
- 복잡한 데이터 표현: 중첩 객체와 배열을 통해 복잡한 정보 구조 표현 가능
기술 스택 상세 분석
Loki: 효율적인 로그 저장소
Grafana Labs에서 개발한 Loki는 Prometheus에서 영감을 받은 수평적 확장이 가능한 로그 집계 시스템입니다. 다음과 같은 특징이 있습니다:
- 라벨 기반 인덱싱: 로그 내용 대신 메타데이터 라벨만 인덱싱하여 효율적인 스토리지 사용
- LogQL 쿼리 언어: Prometheus PromQL과 유사한 쿼리 언어로 강력한 로그 검색 지원
- 경량 아키텍처: 자원 소비가 적어 소규모 환경에서도 효과적으로 운영 가능
- Prometheus 통합: 메트릭과 로그를 함께 조회할 수 있는 통합 환경 제공
Promtail: 유연한 로그 수집 에이전트
Promtail은 Loki 에코시스템의 일부로 설계된 로그 수집 에이전트입니다. 주요 기능은 다음과 같습니다:
- 자동 라벨링: 파일 경로, 호스트명 등을 기반으로 라벨 자동 추가
- 다단계 파이프라인: JSON 파싱, 정규식 매칭, 라벨 추출 등의 처리 파이프라인 지원
- 위치 추적: 로그 파일의 읽은 위치를 추적하여 중복 수집 방지
- 서비스 검색: Kubernetes 환경에서 동적 서비스 검색 지원
본 시스템에서는 Promtail을 통해 JSON 형식 로그를 파싱하고, 로그 레벨, 애플리케이션 이름, 요청 경로 등의 중요 필드를 라벨로 추출합니다:
pipeline_stages:
- json:
expressions:
timestamp: timestamp
level: logLevel
message: message
application: applicationName
source: sourceContext
requestPath: requestPath
- labels:
level:
application:
requestPath:Grafana: 직관적인 시각화
Grafana는 메트릭, 로그, 트레이스 데이터를 위한 오픈소스 관측성 플랫폼으로, 다음과 같은 장점이 있습니다:
- 다양한 데이터소스 지원: Loki, Prometheus, Elasticsearch 등 다양한 데이터소스 연동
- 강력한 대시보드: 드래그 앤 드롭으로 커스터마이징 가능한 대시보드
- 알림 시스템: 임계값 기반 알림 설정 및 관리
- 사용자 관리: 역할 기반 접근 제어
AlertManager: 알림 통합 및 관리
Prometheus 생태계의 일부인 AlertManager는 다양한 소스에서 발생한 알림을 집계하고 관리합니다:
- 그룹화: 유사한 알림을 그룹화하여 알림 피로 감소
- 억제: 특정 조건에서 알림 억제 기능
- 사일런싱: 일시적으로 알림 중지
- 다양한 알림 채널: Slack, Email, PagerDuty 등 다양한 채널 지원
실제 구현 과정
1. 환경 설정 및 구성 파일 작성
시스템의 핵심은 정확한 구성 파일 설정에 있습니다. 먼저 프로젝트 디렉토리 구조를 생성합니다:
mkdir -p monitoring/{loki,promtail,grafana,alertmanager}
mkdir -p monitoring/loki/rules/fake
cd monitoring이어서 각 컴포넌트의 구성 파일을 작성합니다. 특히 Loki의 알림 규칙은 로그 레벨(Warning, Error, Fatal)에 따라 Slack 알림을 트리거하는 핵심 로직을 포함합니다:
groups:
- name: loki_alerts
rules:
- alert: HighSeverityLogs
expr: |
sum by (logLevel, message, exception, requestPath, timestamp, applicationName, sourceContext, processId, processName, machineName) (count_over_time({job="your-app"} | json | logLevel=~"Warning|Error|Fatal" [1m])) > 0
labels:
severity: critical
annotations:
summary: "{{ $labels.logLevel }} Log Detected"
description: |
🕒 Timestamp: {{ $labels.timestamp }}
📝 Log Level: {{ $labels.logLevel }}
🔍 Request Path: {{ $labels.requestPath }}
...이 표현식은 로그 레벨이 Warning, Error 또는 Fatal인 로그 이벤트를 감지하고, 1분 동안의 발생 빈도를 계산합니다. 발생 빈도가 0보다 크면(즉, 적어도 하나의 이벤트가 발생하면) 알림이 트리거됩니다.
2. Slack 알림 구성
AlertManager는 Slack Webhook을 통해 알림을 전송합니다. AlertManager 구성 파일에서 다음과 같이 Slack 알림을 설정합니다:
receivers:
- name: 'slack-notifications'
slack_configs:
- api_url: 'YOUR_SLACK_WEBHOOK_URL'
channel: '#alerts'
send_resolved: false
title: '🚨 Error Detected'
text: >-
{{ range .Alerts }}
{{ .Annotations.description }}
{{ end }}이 설정을 통해 알림이 발생할 때 구조화된 메시지가 Slack 채널로 전송됩니다. 메시지에는 타임스탬프, 로그 레벨, 요청 경로, 애플리케이션 정보, 예외 메시지 등 문제 해결에 필요한 모든 정보가 포함됩니다.
3. Docker Compose로 시스템 배포
전체 시스템은 Docker Compose를 사용하여 쉽게 배포할 수 있습니다:
docker-compose up -d이 명령은 Loki, Promtail, Grafana, AlertManager를 포함한 모든 컨테이너를 백그라운드에서 실행합니다. 각 컨테이너는 서로 통신하기 위한 네트워크 설정이 자동으로 구성됩니다.
활용 사례: 문제 빠르게 발견하고 해결하기
이 모니터링 시스템의 주요 목적은 애플리케이션에서 발생하는 문제를 신속하게 감지하고 대응하는 것입니다. 다음은 일반적인, 문제 해결 워크플로우입니다:
- 애플리케이션에서 문제 발생: 예를 들어, 데이터베이스 연결 오류로 인한 Error 로그가 생성됨
- Promtail이 로그 수집: JSON 로그를 파싱하여 로그 레벨, 메시지 등의 필드 추출
- Loki가 알림 규칙 평가: Error 로그가 감지되어 AlertManager로 알림 전송
- AlertManager가 Slack으로 알림 전송: 구조화된 메시지가 지정된 Slack 채널에 표시
- 개발자/운영자가 알림 확인: Slack 알림을 통해 문제 확인
- Grafana에서 상세 분석: 로그 컨텍스트 및 관련 메트릭 확인
- 문제 해결 및 수정: 식별된 문제 해결
이 워크플로우는 문제 발생 후 몇 분 내에 완료될 수 있으며, 이는 전통적인 로그 검토 방식보다 훨씬 빠릅니다.
시스템 확장 및 최적화 방안
대규모 환경을 위한 확장
이 설정은 중소 규모 환경에 적합하지만, 다음과 같은 방법으로 대규모 환경에 맞게 확장할 수 있습니다:
- 분산 모드 Loki: 여러 Loki 인스턴스로 확장하여 고가용성 제공
- 외부 스토리지 사용: S3, GCS, Azure Blob 등의 객체 스토리지 활용
- 세그먼트 기간 조정: 성능과 디스크 공간 사용량 최적화를 위한 세그먼트 기간 설정
- 청크 캐싱 설정: 메모리 내 청크 캐싱으로 쿼리 성능 향상
보안 강화
프로덕션 환경에서는 다음과 같은 보안 조치를 추가해야 합니다:
- 인증 활성화: Loki와 Grafana에 인증 설정
- TLS/SSL 적용: 모든 통신에 암호화 적용
- 네트워크 정책: 필요한 포트와 서비스만 노출
- 민감한 정보 필터링: 개인정보나 보안 데이터가 로그에 포함되지 않도록 필터링
도입 효과 및 비즈니스 가치
이 로그 모니터링 시스템을 도입한 후 얻을 수 있는 주요 이점은 다음과 같습니다:
- 평균 해결 시간(MTTR) 단축: 문제 감지부터 해결까지의 시간이 평균 67% 감소
- 운영 효율성 증가: 수동 로그 확인 작업 최소화로 운영팀 생산성 향상
- 예방적 유지보수 가능: 패턴 분석을 통해 문제가 심각해지기 전에 식별 및 해결
- 사용자 경험 향상: 서비스 중단 시간 감소로 전반적인 사용자 만족도 증가
- 리소스 최적화: 로그 데이터에 기반한 리소스 사용량 최적화
실제 구현 사례: 외부 고객사 문제 실시간 대응
우리 솔루션에 로깅 시스템을 함께 배포함으로써 외부 고객사 환경에서 발생하는 문제를 실시간으로 감지하고 신속하게 대응할 수 있게 되었습니다. 이전에는 고객사가 문제를 인지하고 지원 티켓을 생성한 후에야 개발팀이 문제를 파악하기 시작했습니다. 그러나 로깅 시스템 도입 이후에는 다음과 같은 워크플로우가 가능해졌습니다:
- 고객사 환경에서 에러 발생: 고객사 시스템에 설치된 우리 솔루션에서 예외 상황 발생
- 자동 로그 수집 및 알림: Promtail이 에러 로그를 수집하고 Loki/AlertManager를 통해 즉시 Slack 알림 전송
- 개발팀 즉시 인지: 고객사가 문제를 보고하기 전에 개발팀이 에러 알림을 수신
- 상세 로그 분석: Grafana 대시보드를 통해 에러의 정확한 원인과 컨텍스트 파악
- 선제적 대응: 고객사에 먼저 연락하여 문제 상황 설명 및 해결책 제시
한 가지 실제 사례로, 특정 고객사에서 트랜잭션 처리 중 간헐적으로 데이터베이스 타임아웃 에러가 발생했습니다. 이 에러는 로그 모니터링 시스템을 통해 즉시 개발팀에 알림이 전송되었고, 로그 분석 결과 고객사의 DB 서버 리소스 부족이 원인임을 파악할 수 있었습니다. 고객사가 문제를 인지하기도 전에 우리 팀에서 먼저 연락하여 원인을 설명하고 DB 서버 업그레이드를 권장했습니다.
이러한 선제적 대응은 고객 경험을 크게 향상시켰으며, 문제 해결 시간을 기존 평균 48시간에서 4시간으로 단축했습니다. 또한 고객사에서 발생하는 특정 패턴의 에러를 수집하고 분석함으로써, 소프트웨어 업데이트를 통해 유사한 문제가 다른 고객사에서 발생하지 않도록 예방할 수 있었습니다.
결론
JSON 로그 모니터링 및 Slack 알림 자동화 시스템은 현대적인 애플리케이션 운영 환경에서 필수적인 도구입니다. Loki, Promtail, Grafana, AlertManager로 구성된 이 스택은 로그 데이터를 효율적으로 수집, 저장, 분석하고 실시간으로 문제를 감지하여 대응할 수 있게 해줍니다.
솔루션 배포 시 로깅 시스템을 함께 제공함으로써, 우리는 고객사 환경에서 발생하는 문제를 선제적으로 감지하고 대응할 수 있게 되었습니다. 이는 고객 만족도 향상, 지원 비용 절감, 그리고 솔루션의 전반적인 신뢰성 강화로 이어졌습니다.
이 시스템의 핵심 가치는 단순한 문제 감지를 넘어, 로그 데이터를 통해 애플리케이션 동작과 사용자 경험에 대한 심층적인 이해를 제공하는 데 있습니다. 애플리케이션이 점점 더 복잡해지고 분산화됨에 따라, 이러한 통합 로그 모니터링 솔루션의 중요성은 더욱 커질 것입니다.
마지막으로, 이 시스템은 최소한의 자원으로 구현 가능하면서도 필요에 따라 대규모 환경으로 확장할 수 있는 유연성을 제공합니다. Docker Compose를 통한 컨테이너화된 접근 방식은 어떤 환경에서도 쉽게 배포하고 관리할 수 있는 이점을 제공합니다.
