
시스템 성능 지표의 주요 메트릭은 단연 Throughput과 Latency입니다. 부하 테스트에서는 이 두 가지 지표를 사용하여 평가합니다.
Throughput
시간당 처리량을 의미합니다. 웹 애플리케이션 성능 지표로서의 throughput의 대표적인 예는 다음과 같습니다.
- 1초에 처리하는 HTTP 요청 수 (rps)
- (동영상 스트리밍 서비스와 같이 대역폭이 중요한 경우) 네트워크로 전송되는 데이터 전송 속도
Latency
처리 시간을 의미합니다.
사용자가 어떤 웹페이지를 보기 위한 Latency는 사용자의 인터넷 환경, 브라우저 등의 개별 환경에 대한 변수가 존재합니다. 즉, "네트워크를 통한 데이터 왕복 시간"도 포함합니다. 그러나 성능 테스트를 진행할 때에는, 사용자 환경에 따른 변인을 통제하거나, 애초에 네트워크 상황을 고려하지 않고 테스트를 진행합니다. 이후 언급하는 Latency는 네트워크 상황을 고려하지 않은 시스템이 요청을 받고 응답을 줄 때까지의 시간만을 의미할 것입니다.
하위 시스템으로 구성된 경우에서의 Throughput과 Latency
다음 고속도로의 비유를 통해 Throughput과 Latency를 이해할 수 있습니다. 여기서 하위 시스템은 서울/대구/부산 각각의 도시를 의미하며, 각 도시 간에는 서로 다른 Throughput과 Latency를 가진 고속도로 두 개가 존재한다고 가정합시다.
- 이때 Latency는 대기 시간을 포함한, 각 하위 시스템 처리 시간의 총합으로 계산합니다.
- 반면 Throughput은 하위 시스템 Throughput 중 최소값을 전체 시스템의 Throughput으로 계산합니다.
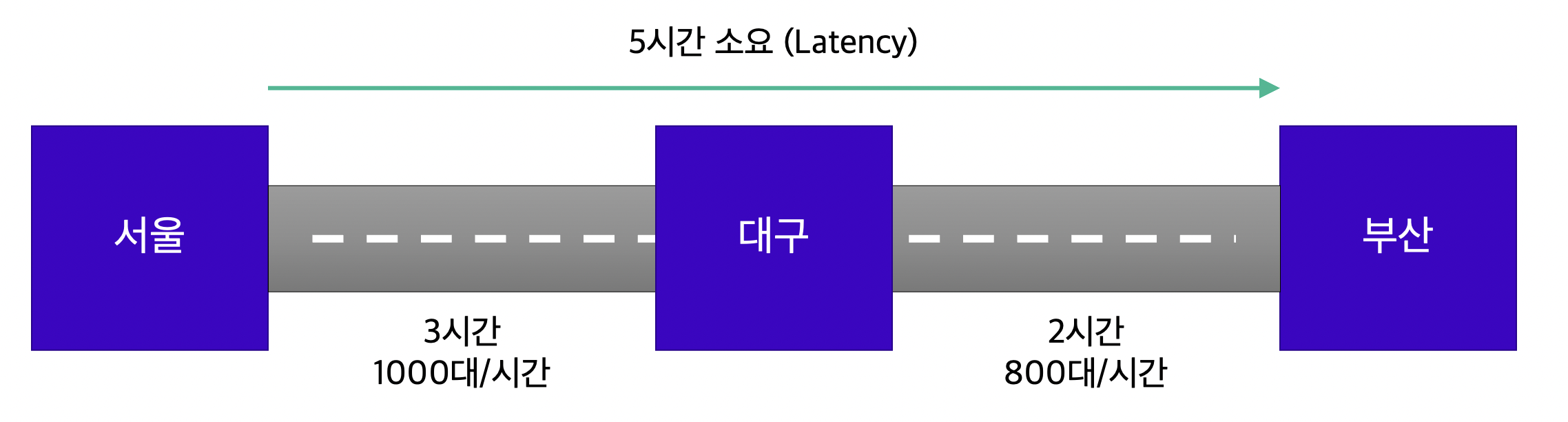
- 서울-부산 간 Latency: 각 구간의 소요 시간 합계인 5시간
- 서울-부산 간 Throughput: 각 구간에 도달하는 차량 대수 중 최소값인 800대/시간
시스템 성능 지표인 Throughut과 Latency를 바탕으로 개선할 경우, 어떤 부분을 먼저 개선해야 하는지 사례를 통해 알아봅니다.
Throughput 개선
고속도로의 예를 다시 빌려, 다음과 같이 세 도시를 연결하는 두 개의 고속도로 중 대구-부산 간 고속도로가 병목을 일으키고 있다고 가정합시다.
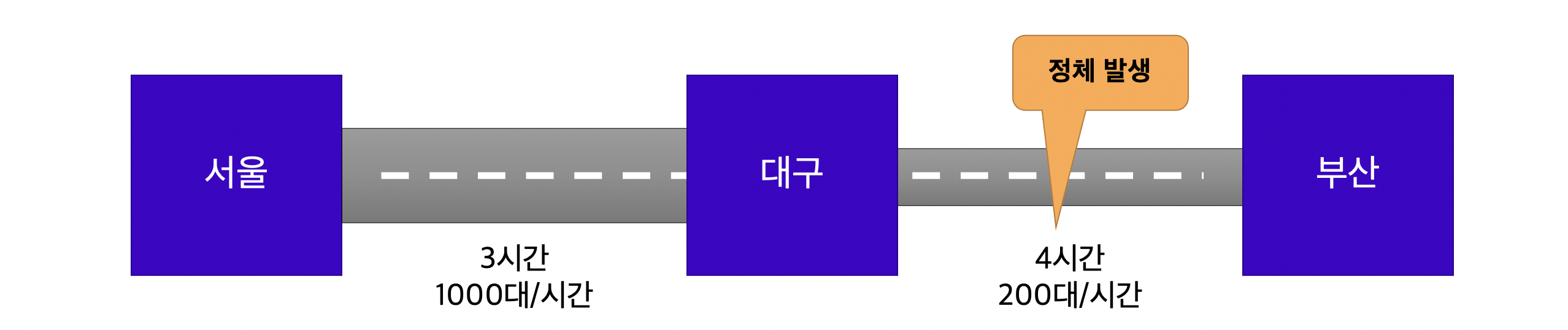
이때, 서울-부산 사이의 Throughput은 최소값인, 200대/시간에 불과합니다. 이런 경우에는 도로 확장 공사를 통해 병목을 해결합니다. 확장 공사를 마친 대구-부산 간 고속도로의 Throughput이 800대/시간으로 개선되었습니다.
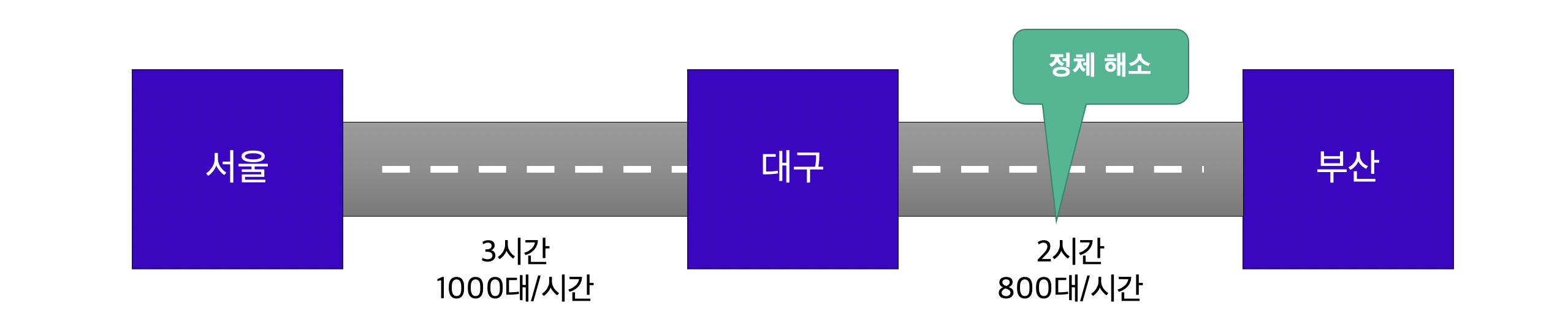
병목이 아닌 구간(서울-대구)을 개선하는 것은, 전체의 Throughput을 개선하는 데에 전혀 도움이 되지 않습니다. 도리어 대구-부산 간의 정체가 늘어나 Throughput이 감소할 수도 있습니다. 따라서, Throughput 개선을 위해서는 병목 구간이 어디인가를 먼저 파악하는 것이 가장 중요합니다.
Latency 개선
애플리케이션 개선
Latency의 개선은 개발된 애플리케이션을 개선하는 것으로 시작합니다. 애플리케이션 성능 최적화는 현상을 파악(APM, Application Performance Monitoring)하는 것으로 시작하며, 알고리즘 개선, I/O 최소화 등의 개선 방안이 뒤따릅니다. DevOps가 이를 모니터링할 수는 있으나, 결국 개발자가 APM 도구와 프로파일러 등을 이용해 이를 개선해야 합니다.
(애플리케이션 성능 향상을 위한) 하위 시스템의 확장
한편 앞서 고속도로의 예를 살펴보면, Throughput의 개선이 Latency의 개선으로 이어진 것을 확인할 수 있습니다. 이는 곧 "대기 시간"에 문제가 있다는 의미입니다. 만일 애플리케이션이 실행 환경(하위 시스템)의 성능을 최대한 활용할 수 있다면, 하위 시스템의 확장에 따라 Throughput도 개선되며, 대기 시간도 줄어듭니다. 즉 많은 경우 Throughput이 개선되면 Latency도 개선됩니다.
응답 성능의 병목 원인과 대책
서비스를 시작한 후 발생할 수 있는 문제 시나리오는 다양합니다. 이러한 문제는 응답 성능의 병목을 가져다줍니다. 아래 제시된 시나리오는 매우 일반적이며, 부하 테스트를 통해 응답 성능을 예측할 수 있습니다. 애플리케이션 수준에서의 대책을 온전히 이해하기는 어렵지만, 주요 키워드를 학습하여 개발자에게 솔루션을 제공할 수는 있어야 합니다.
- 많은 사용자의 서비스 등록
- 많은 데이터의 저장
- 1,2번과 같은 경우 DB에 데이터가 증가합니다. secondary 복제본 등을 이용해 읽기/쓰기를 분리하거나, 검색에 최적화된 인덱스 사용을 고려할 수 있습니다.
- 단기간 동안의 사용자 요청 증가(peak traffic)
- Auto Scaling이 해결책이 될 수 있습니다. 다만 버스트 성능에 대해 이해해야 합니다.
- 배치 작업을 진행하는 데이터베이스
- DB가 주기적으로 스냅샷을 만들거나, 데이터 일관성을 위해 레플리카와의 sync 과정을 진행하는 등의 배치 작업이 이루어질 경우, primary DB는 성능 저하가 발생할 수 있습니다. 이때 사용자들의 요청과 맞물려 서비스 수준을 맞추기 어려울 수 있습니다.
- 많은 양의 로그 수집 처리
- 애플리케이션이 잘 작동할 때에는 로그를 많이 남기지 않지만, 애플리케이션에 문제가 발생하면 추적을 위해 많은 로그를 남깁니다. 다만 이러한 상황이 반복적으로 진행될 경우, 에러 로그 수집 그 자체가 애플리케이션 병목을 일으킬 수 있습니다.
- 시스템 재시작 후의 캐시 초기화
- 큰 문제를 발생시키는 것은 아니지만, 캐시가 초기화되면서 시스템으로 직접적인 요청 횟수가 증가할 수 있습니다.
질문사항
- Q. AWS에서는 버스트 가능한 인스턴스의 경우, CPU 성능을 적게 사용하는 평상시에는 "크레딧"을 누적했다가, 단기간의 사용자 요청 증가와 같이 CPU 사용량이 증가할 경우, 모아둔 크레딧을 성능을 끌어올리는 용도로 사용할 수 있습니다. 이때 잔고에 충분한 크레딧이 있어야 합니다. 그렇지 않을 경우 100%의 CPU 성능을 제공하지 못하여, 파열(burst)에 이르며, 시스템 사용 불능 상태가 됩니다. 어떠한 메커니즘으로 작동하는지 한번 알아보세요.
주요 병목 구간과 부하 테스트 시 고려해야 할 부분
병목 구간을 확인하는 것은 부하 테스트의 주요 목적이면서, 또한 좋은 부하 테스트를 만드는 기본입니다. 시스템에서 문제가 발생할 수 있는 부분을 다이어그램으로 표현하면 다음과 같습니다.


좋은정보 감사합니다