
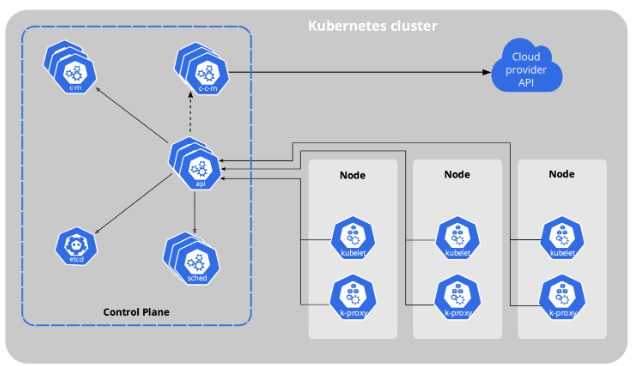
쿠버네티스 아키텍처는 이렇게 생겼습니다.
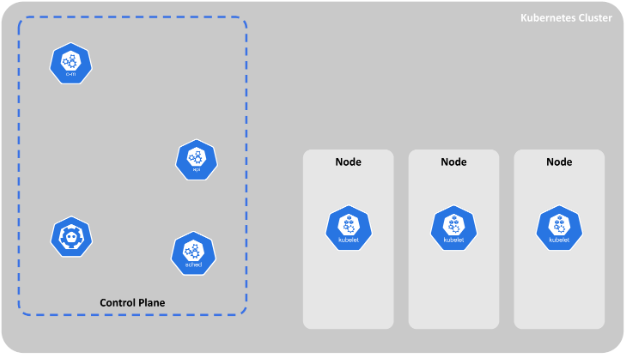
클러스터는 최소 하나 이상의 제어판(Control Plane) 컴포넌트와, 이것과 연결된 몇개의 워커 노드로 구성되어 있습니다.
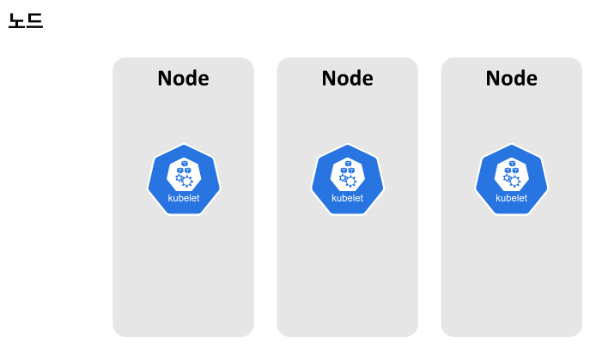
워커 노드는 kubelet이라는 프로세스가 돌아가고 있는데, 이 kublet은 다른 노드와 서로 통신하거나 컨테이너를 실행하는 등의 태스크를 실행할 수 있게 합니다.
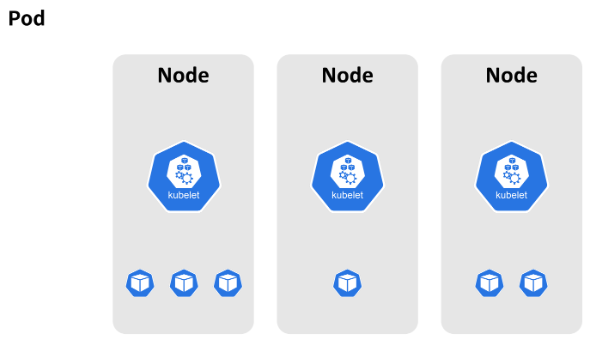
워커 안에는 한개 이상의 컨테이너가 자리잡고 있으며, 즉 워커 노드는 실제로 애플리케이션이 실행되고 있는 곳이라고 할 수 있습니다.
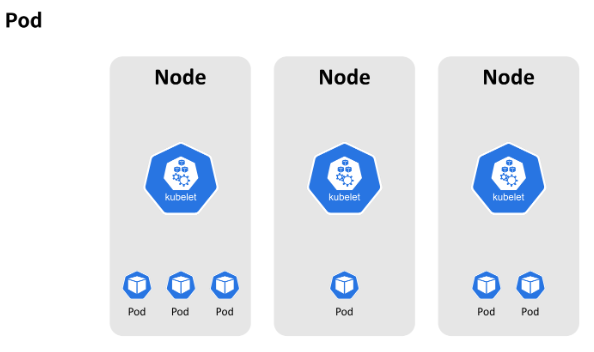
쿠버네티스에서는 이러한 컨테이너(정확히는 컨테이너 그룹)와 컨테이너가 사용하는 볼륨, 그리고 컨테이너의 작동 정보를 특별히 파드(Pod)라는 이름으로 부릅니다. 이에 대해서는 이후에 다시 다룹니다.
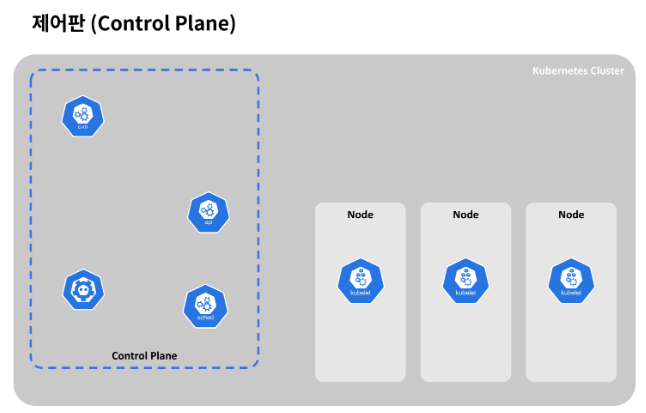
관리를 위해 필요한 프로세스들은 전부 제어판 컴포넌트에 있습니다. 제어판 컴포넌트는 클러스터가 잘 작동할 수 있게 돕습니다.
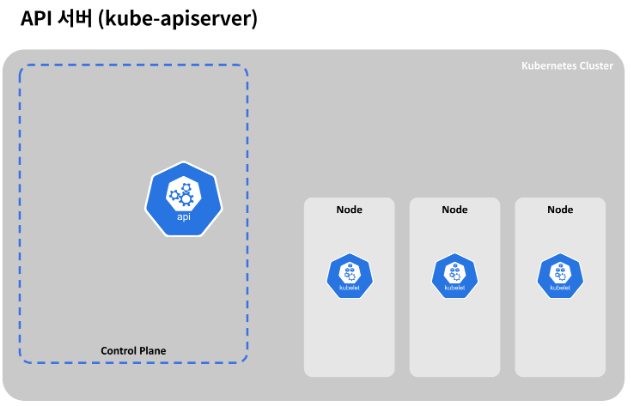
제어판 컴포넌트에 있는 여러가지 프로세스 중 먼저 소개할 것은 바로 API 서버입니다.
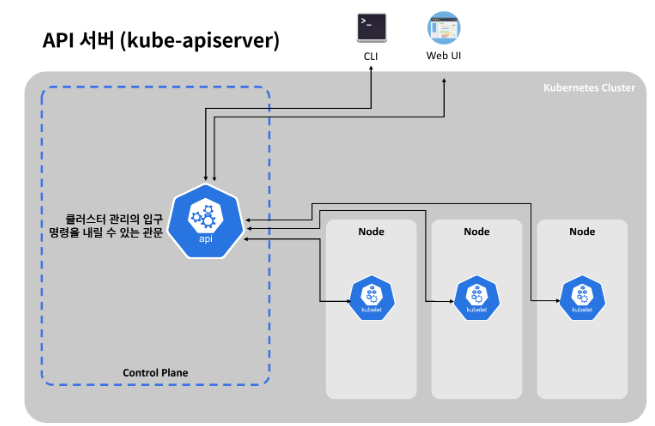
말 그대로 API 서버는 모든 클러스터 관리의 입구로서, 명령을 내릴 수 있는 관문입니다. 실제로 쿠버네티스에서 제공되는 UI나 CLI등에서 클러스터 관리를 위해 뭔가 명령을 내리면 API가 호출됩니다. 당연히 직접 호출할 수도 있습니다.
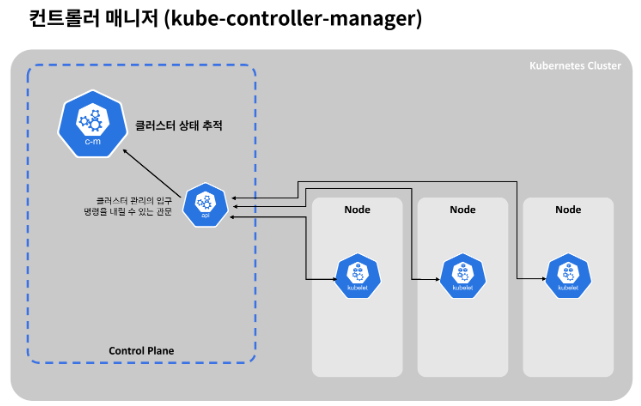
다른 하나는 Controller manager입니다. 클러스터에서 무슨 일이 발생하는지를 추적하는 역할을 합니다. 예를 들어 컨테이너가 죽거나 재시작되었을 경우, 컨트롤러 매니저는 이를 알 수 있습니다.
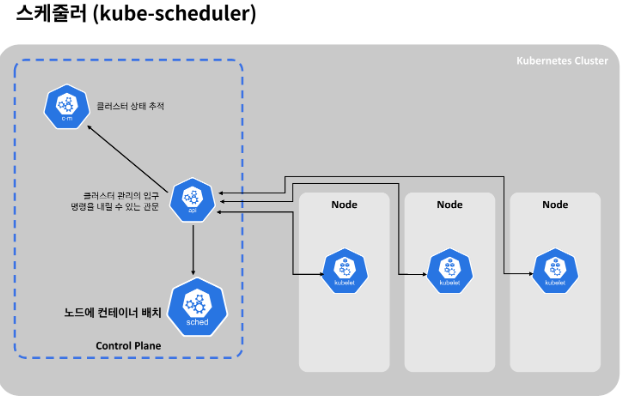
또 스케쥴러가 있습니다. 스케쥴러는 서버(노드) 리소스를 바탕으로 컨테이너(정확히는 pod)가 노드에 배치되게 만드는 역할을 담당합니다. 새로 생성된 컨테이너를 찾아 노드에 할당합니다.
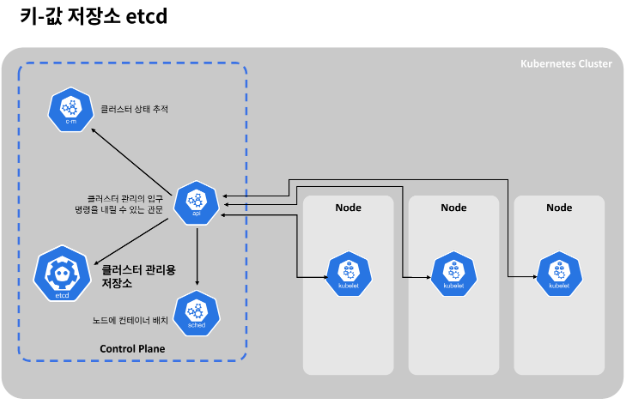
마지막으로 ETCD 데이터베이스가 존재하는데, 이는 Key-value 저장소인데, 클러스터 관리에 필요한 모든 데이터를 저장하는 공간입니다. 인프라를 원하는 상태로 만들기 위해서는, 정상 상태에 대한 snapshot 및 관리에 필요한 메타데이터가 어딘가에 저장되어야 하는데, ETCD는 바로 이를 담당합니다.
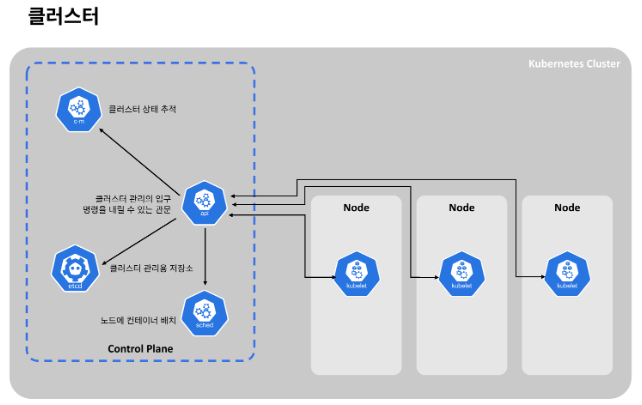
쿠버네티스 클러스터에 대한 간략한 소개 및 작동 원리입니다.
