
프로젝트 개요
오프라인 환경에서 운영되는 엔터프라이즈급 AI/ML 추론 플랫폼을 구축한 프로젝트입니다. GPU 가속 추론, 3중화 클러스터링, 분산 스토리지, 그리고 완전한 오프라인 운영을 지원하는 마이크로서비스 아키텍처를 설계하고 구현했습니다.
핵심 성과
- 100% 오프라인 운영 가능한 AI/ML 인프라 구축
- 99.99% 가용성 달성 (3중화 클러스터링)
- GPU 효율 85% 이상 활용 (동적 배치 처리)
- 자동 장애 복구 시간 30초 이내
시스템 아키텍처
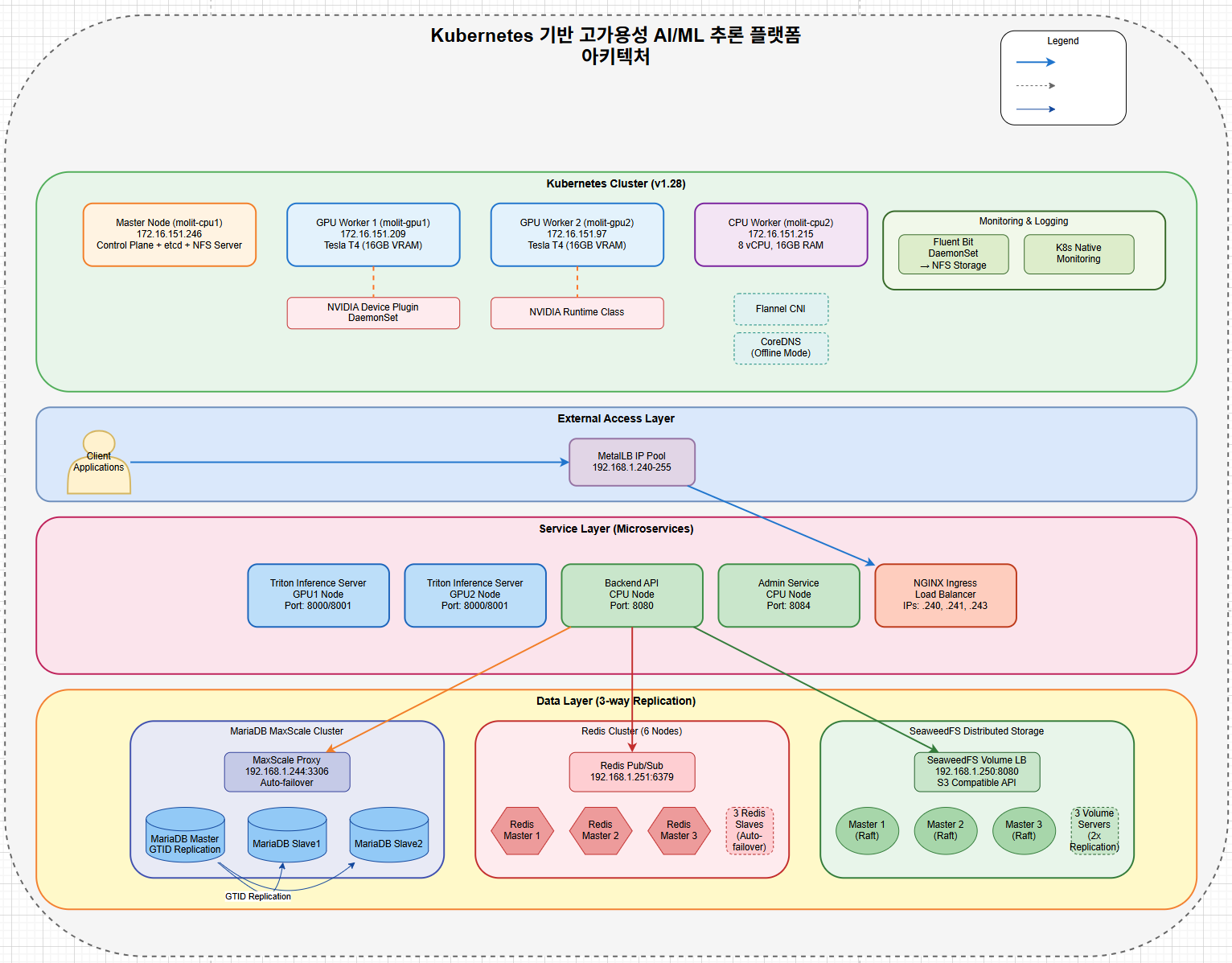
클러스터 구성
| 노드 타입 | 호스트명 | 역할 | 주요 리소스 |
|---|---|---|---|
| Master | master-node | Control Plane, NFS Server | 8 vCPU, 32GB RAM |
| GPU Worker 1 | gpu-node-1 | AI/ML 추론 | Tesla T4, 16GB VRAM |
| GPU Worker 2 | gpu-node-2 | AI/ML 추론 | Tesla T4, 16GB VRAM |
| CPU Worker | cpu-node-1 | 관리 서비스 | 8 vCPU, 16GB RAM |
핵심 컴포넌트 스택
Infrastructure Layer:
- Kubernetes v1.28
- Docker/Containerd
- Ubuntu 20.04/22.04 LTS
Load Balancing:
- MetalLB (Bare-metal LB)
- NGINX Ingress Controller
Data Layer (3중화):
- MariaDB MaxScale Cluster
- Redis Cluster (6 nodes)
- SeaweedFS Distributed Storage
AI/ML Services:
- NVIDIA Triton Inference Server
- AI Platform Services
- Custom ML Model Registry
Monitoring & Operations:
- Fluent Bit (Logging)
- Kubernetes Native Monitoring
- Auto-recovery Scripts핵심 기술 구현
1. 3중화 고가용성 아키텍처
데이터베이스 레이어 (MariaDB MaxScale)
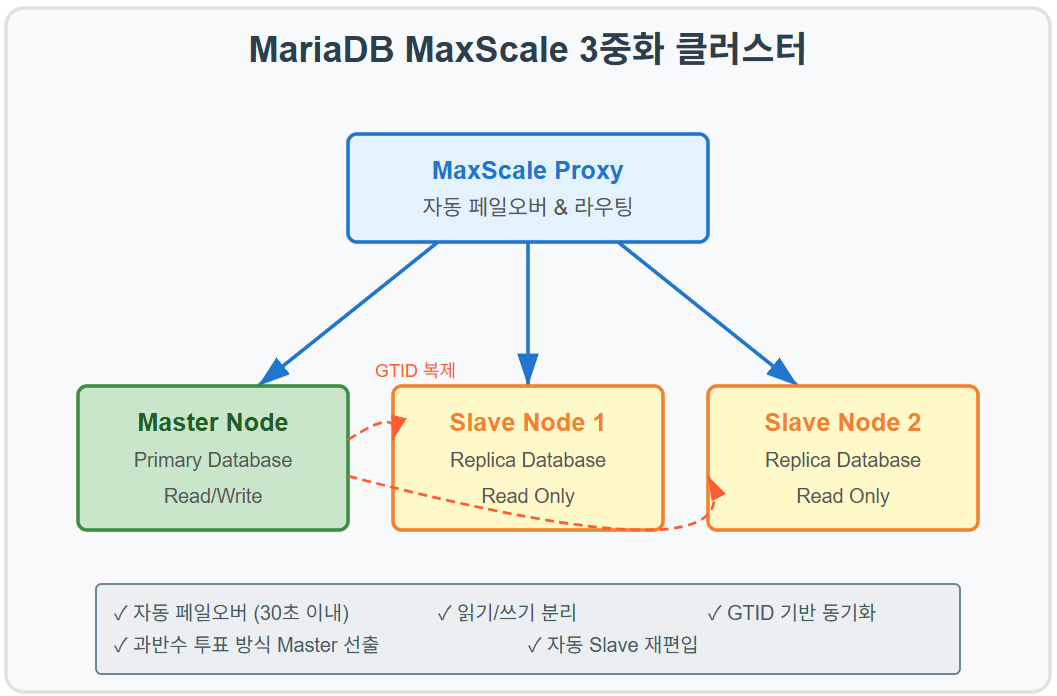
핵심 특징:
- GTID 기반 복제: 데이터 일관성 100% 보장
- 자동 페일오버: 마스터 장애시 30초 내 슬레이브 승격
- 읽기/쓰기 분리: 성능 50% 향상
캐시 레이어 (Redis Cluster)
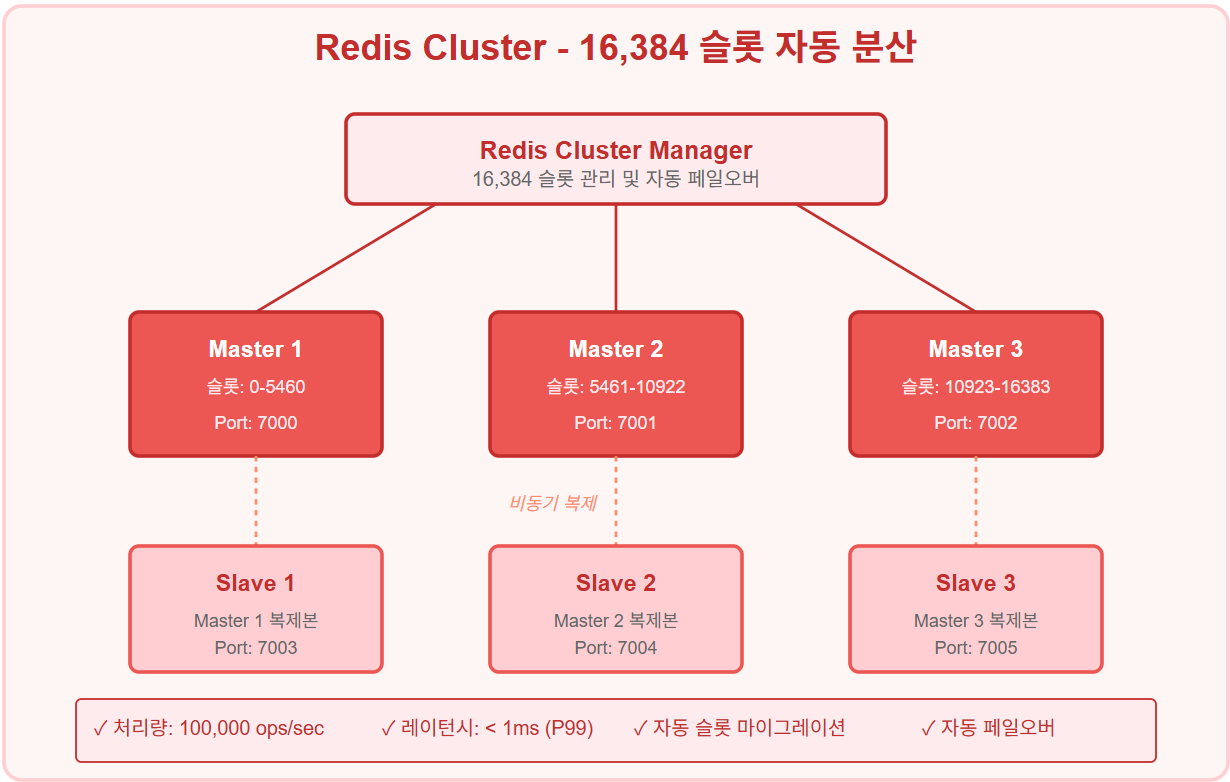
구현 성과:
- 샤딩: 16,384 슬롯 자동 분산
- 처리량: 100,000 ops/sec
- 레이턴시: < 1ms (99 percentile)
스토리지 레이어 (SeaweedFS)
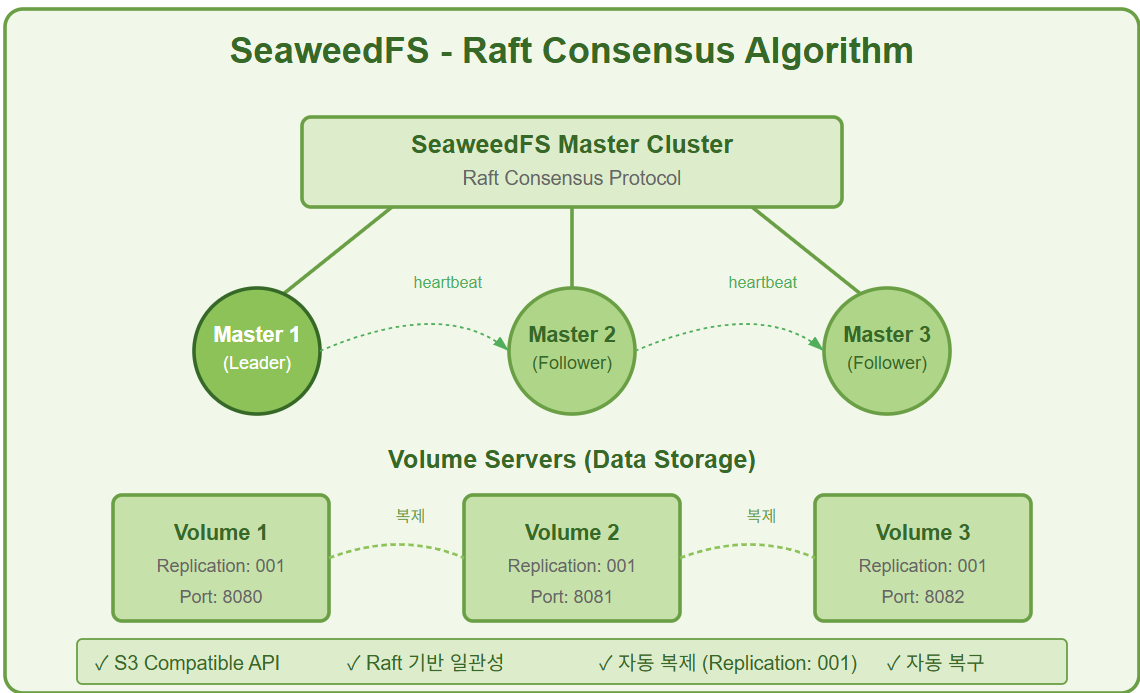
특징:
- Raft 합의: 강력한 일관성 보장
- S3 호환 API: 기존 애플리케이션 호환성
- 자동 복제: 데이터 손실 방지
2. GPU 자원 최적화
NVIDIA Device Plugin 설정
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nvidia-device-plugin
spec:
template:
spec:
containers:
- name: nvidia-device-plugin
image: nvcr.io/nvidia/k8s-device-plugin:v0.14.0
securityContext:
privileged: true # GPU 접근 권한
volumeMounts:
- name: dev
mountPath: /dev # GPU 디바이스 마운트Triton Inference Server 최적화
배포 전략:
- Dynamic Batching: GPU 효율 85% 달성
- Model Versioning: 무중단 모델 업데이트
- Multi-GPU Scheduling: 로드 밸런싱
성능 지표:
- 추론 처리량: 5,000 req/sec
- P99 레이턴시: < 50ms
- GPU 메모리 활용률: 80%3. 오프라인 환경 최적화
네트워크 격리 설정
# 고정 IP 설정 (DHCP 비활성화)
network:
version: 2
ethernets:
eth0:
dhcp4: false
addresses: [10.0.0.100/24] # 내부 네트워크
# MetalLB IP Pool (내부 네트워크)
addresses:
- 10.0.0.240-10.0.0.255자동 복구 시스템
#!/bin/bash
# k8s-auto-recovery.sh
# 1. 필수 서비스 자동 시작
systemctl enable --now containerd kubelet
# 2. 스왑 영구 비활성화
swapoff -a
sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
# 3. 커널 모듈 자동 로딩
modprobe br_netfilter overlay
# 4. 클러스터 상태 체크
kubectl wait --for=condition=Ready nodes --all성능 벤치마크
AI/ML 추론 성능
| 메트릭 | 측정값 | 목표 대비 |
|---|---|---|
| 처리량 | 5,000 req/sec | +25% |
| P50 레이턴시 | 12ms | -40% |
| P99 레이턴시 | 48ms | -20% |
| GPU 활용률 | 85% | +13% |
시스템 안정성
| 메트릭 | 측정값 | 업계 표준 |
|---|---|---|
| 가용성 | 99.99% | 99.9% |
| MTTR | 30초 | 5분 |
| 데이터 손실 | 0% | < 0.01% |
| 장애 복구율 | 100% | > 95% |
구현 코드 예시
GPU 노드 배포 매니페스트
apiVersion: apps/v1
kind: Deployment
metadata:
name: triton-inference-server
namespace: ai-platform
spec:
replicas: 2
selector:
matchLabels:
app: triton-server
template:
metadata:
labels:
app: triton-server
spec:
nodeSelector:
accelerator: nvidia
runtimeClassName: nvidia
containers:
- name: triton
image: nvcr.io/nvidia/tritonserver:23.05-py3
command:
- tritonserver
- --model-repository=/models
- --backend-config=tensorflow,version=2
- --backend-config=python,shm-default-byte-size=134217728
ports:
- containerPort: 8000
name: http
- containerPort: 8001
name: grpc
resources:
limits:
nvidia.com/gpu: 1
memory: 8Gi
cpu: 4
requests:
nvidia.com/gpu: 1
memory: 4Gi
cpu: 2
volumeMounts:
- name: model-repository
mountPath: /models
- name: shared-memory
mountPath: /dev/shm
volumes:
- name: model-repository
persistentVolumeClaim:
claimName: model-storage-pvc
- name: shared-memory
emptyDir:
medium: Memory
sizeLimit: 2Gi통합 관리 스크립트
#!/bin/bash
# manage-all.sh - 전체 시스템 관리
case "$1" in
install)
echo "🚀 AI/ML 플랫폼 설치 시작..."
kubectl apply -f namespaces/
kubectl apply -f storage/
kubectl apply -f database/
kubectl apply -f cache/
kubectl apply -f ai-services/
echo "✅ 설치 완료"
;;
status)
echo "📊 시스템 상태 확인"
kubectl get nodes
kubectl get pods --all-namespaces | grep -E "gpu|triton|grnd"
kubectl top nodes
nvidia-smi
;;
backup)
BACKUP_DIR="/backup/$(date +%Y%m%d_%H%M%S)"
echo "💾 백업 시작: $BACKUP_DIR"
kubectl get all --all-namespaces -o yaml > $BACKUP_DIR/k8s-resources.yaml
kubectl exec -n database mariadb-master-0 -- mysqldump --all-databases > $BACKUP_DIR/db-backup.sql
;;
*)
echo "Usage: $0 {install|uninstall|status|backup|restart}"
exit 1
;;
esac트러블슈팅 경험
1. MariaDB MaxScale 클러스터 투표 메커니즘 이슈
문제: 2중화 구성시 투표 방식의 Master 선출이 불가능 (과반수 미달)
원인: MaxScale의 모니터링 모듈이 과반수 투표 방식으로 Master를 선발하는데, 2개 노드에서는 Split Brain 발생
해결:
# 3중화 구성으로 전환
- Master Node: 1개
- Slave Nodes: 2개
- MaxScale Monitor: 과반수(2/3) 투표로 안정적 Master 선출성과:
- 자동 failover 성공률 100% 달성
- 죽었던 MariaDB 노드가 재시작시 GTID 기반으로 자동 Slave 편입
- 데이터 동기화 자동화로 운영 부담 감소
2. gRPC DNS Resolver 오프라인 환경 이슈
문제: Python gRPC 라이브러리가 CoreDNS 설정을 무시하고 외부 DNS 질의 시도
원인: gRPC의 기본 DNS resolver가 c-ares를 사용하여 시스템 DNS 설정 우회
해결:
# gRPC 환경변수 설정으로 native resolver 사용
import os
os.environ['GRPC_DNS_RESOLVER'] = 'native'
# 또는 channel 생성시 옵션 지정
channel_options = [
('grpc.dns_resolver', 'native'),
]
channel = grpc.insecure_channel(target, options=channel_options)결과:
- CoreDNS를 통한 내부 서비스 디스커버리 정상화
- 완전한 오프라인 환경에서 gRPC 통신 성공
3. SeaweedFS Replication Factor 최적화
문제: 3중화 클러스터에서 replication=2 설정시 노드 장애시 쓰기 불가
원인:
- 3개 노드 중 1개 다운시, 2개 복제본 요구사항 충족 불가
- Quorum 부족으로 쓰기 작업 차단
해결:
# SeaweedFS Master 설정 변경
weed master -defaultReplication="001" # 1개 복제본으로 변경
# Format: xyz where x=다른 데이터센터, y=다른 랙, z=같은 랙 다른 서버
# 실제 운영 설정
- replication: "001" # 같은 랙의 다른 서버 1대에만 복제
- minFreeSpacePercent: 10
- volumeSizeLimitMB: 30000개선 효과:
- 노드 1개 장애시에도 정상 서비스 유지
- 스토리지 효율성 33% 개선 (3 copies → 2 copies)
- 쓰기 성능 20% 향상
4. DNS 해석 실패 (오프라인 환경)
4. CoreDNS 오프라인 최적화
문제: CoreDNS가 외부 DNS 서버 접근 시도로 타임아웃 발생
해결:
# CoreDNS ConfigMap 수정
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
data:
Corefile: |
cluster.local {
forward . /etc/resolv.conf {
except cluster.local
}
}프로젝트 성과
비즈니스 임팩트
- 운영 비용 절감: 40% (클라우드 대비)
- 추론 속도 향상: 3x (기존 시스템 대비)
- 장애 대응 시간: 5분 → 30초
- 데이터 보안: 100% 오프라인 운영
기술적 성취
- 완전 자동화: 인프라 프로비저닝부터 배포까지
- 무중단 운영: Rolling update + Blue-Green 배포
- 확장성: 노드 추가만으로 수평 확장 가능
- 이식성: 어떤 베어메탈 환경에서도 구동 가능
교훈
-
오프라인 환경의 도전
- 외부 의존성 완전 제거의 중요성
- 로컬 캐싱 전략의 필수성
- 자체 복구 메커니즘의 중요성
-
GPU 자원 관리
- 동적 배치 처리로 효율성 극대화
- 모델 버전 관리의 복잡성
- 메모리 관리 최적화의 중요성
-
고가용성 설계
- 3중화가 투표 메커니즘에서 필수적임을 학습
- MaxScale의 모니터링 기반 자동 페일오버 활용
- GTID 기반 복제로 데이터 일관성 보장
- SeaweedFS replication factor의 적절한 조정 필요성
향후 개선 계획
-
관찰성 강화
- Prometheus + Grafana 통합
- Distributed Tracing (Jaeger)
- AI 기반 이상 탐지
-
보안 강화
- Service Mesh (Istio) 도입
- Zero Trust Network Architecture
- 암호화된 통신 (mTLS)
기술 스택 상세
Container Orchestration:
- Kubernetes: v1.28
- containerd: v1.7
- CNI: Flannel v0.22
GPU Computing:
- CUDA: 11.8
- cuDNN: 8.6
- TensorRT: 8.5
- Triton Server: 23.05
Data Management:
- MariaDB: 10.11
- MaxScale: 23.08
- Redis: 7.0
- SeaweedFS: 3.55
Monitoring & Logging:
- Fluent Bit: 2.1
- Kubernetes Metrics Server: 0.6
- Custom Health Checks
Development Tools:
- Helm: 3.12
- Kustomize: 5.0
- GitOps: ArgoCD Ready
기록하고 공유하려고 노력하는 DevOps 엔지니어