elastic 비전공자 교육을 맡게 되면서 나도 elastic stack에 대해 놓치고 있는 부분이 많아 기초부터 다시 한번 다져보려고 한다.
또한 다시 공부하면서 공부 내용을 정리하여 앞으로 꾸준하게 elastic 공부 기록을 남기고자 한다.
우선 처음으로 작성할 게시글은 데이터 수집에 관한 내용이다.
엘라스틱에서 김종민님이 웨비나로 진행하였던 내용에 대해 작성해보고자 한다
https://www.elastic.co/kr/virtual-events/optimizing-the-ingest-pipeline-for-elasticsearch
웨비나의 agenda는 아래와같이 구성되어있다.
agenda
1. Elastic Platform 소개
2. Ingest pipelines 아키텍쳐 소개
3. 데모 - Ingest pipeline 관리도구 (kibana) -> 어떻게 관리하는지
우선 elasti에 대해 간단한게 알아보자.
1. Elastic Platform 소개
Elastic 이란
하나의 플랫폼 위에서 하나의 스택위에서 다양한 기능들을 구현해하도록 만들어진 검색 솔루션이다.
Elastic Platform은 다음과같이 세가지 카테고리로 분류된다.
The Elastic Platform
1. Enterprise Search
2. Observability
3. Security
어떠한 기능이 개발이 되면 이 세가지에 전부 다 적용이 되어 확장이 된다고 보면 된다.
엘라스틱 서치나 키바나가 하나의 UI에서 동일한 사용자 경험으로 모든 것을 활용할 수있기 때문에 조직에서 통합관리하기 편리하다.
또한 엘라스틱 플랫폼의 경우 public cloud, on-premise로 설치도 가능하고 Elastic에서 제공하는 Elastic cloud에서도 사용이 가능하다.
우리가 이번에 알아볼 내용은 데이터 수집에 관한 것이다. 데이터 수집을 하기 위해서 데이터 수집기가 필요하다.
elastic에서 데이터 수집을 할 수 있는 건 logstash, beats, 그리고 elastic agent가 있다.
저장과 분석은 스택 심장인 엘라스틱서치가 담당한다고 볼 수있다. 또한 시각화의 경우 어떤 데이터 시스템들은 시각화도구를 제공하지않고 저장소 도구만 제공하는데, 엘라스틱의 경우 시각화 도구 더 나아가 탐색하고 접근할 수 있는 키바나를 제공한다는 것이 큰 강점이다.
한마디로 수집부터 저장 그리고 시각화까지 모든 것들을 엘라스틱을 통해 할 수 있다.
2.Ingestpipeline 소개
현재 우리가 살고있는 세상은 기하급수적인 데이터량을 보유하고 있으며 복잡성도 증가하고 있다.
데이터 종류들도 구조적 데이터, 비구조적 데이터, 반구조적 데이터로 굉장히 다양하게 데이터들이 생성되고 있다.
이 데이터들이 엔지니어들에게는 다 리소스이기 때문에 다양한 데이터들을 잘 활용해야한다.
그렇기 때문에 통합되지않은 다양한 데이터들을 수집할 때 데이터들을 같은 모양으로 통합시키고 처리시킬 수 있는 파이프라인 공장이 필요하고 굉장히 중요하다.
그래서 엘라스틱에는 이런 데이터 수집 파이프라인을 위해서 다양한 도구들을 제공하고 있다.
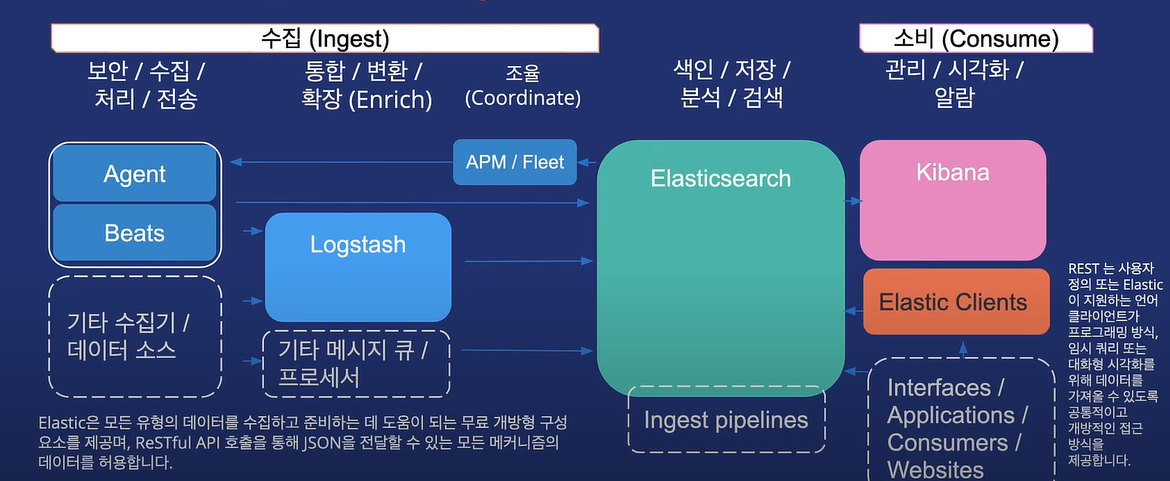
엘라스틱서치는 노드별로 역할을 지정할 수 있다. 데이터를 받아서 인제스트 파이프라인을 실행시키는 노드를 인제스트 파이프라인 노드로 설정하며 된다. 인제스트 파이프라인은 데이터가 색인에 들어가는 바로 전까지 데이터에 필요한 변형을 줄 수 있다. 그리고 인제스트 파이프라인 처리 기능 단위를 프로세서라고 한다.
또한 enrich pipeline 이라는 것도 있는데 이 파이프라인은 색인 과정에서 다른 인덱스에서 데이터를 참조해서 가져와 색인하려는 도큐먼트에 확장해서 넣을 수 있다 rdb에서 조인같은 기능이다.
비츠와 에이전트를 이용하여 데이터를 바로 수집하는 경우 ingest pipeline이랑 같이 사용하는 것이 중요하니 알아보도록 하자.
또한 개발 중 파이프라인 테스트가 가능한 기능을 제공한다고 하니 데모를 통해 이 부분을 실습해 보고자 한다.
3. 데모 - Ingest pipeline 관리도구 (kibana)
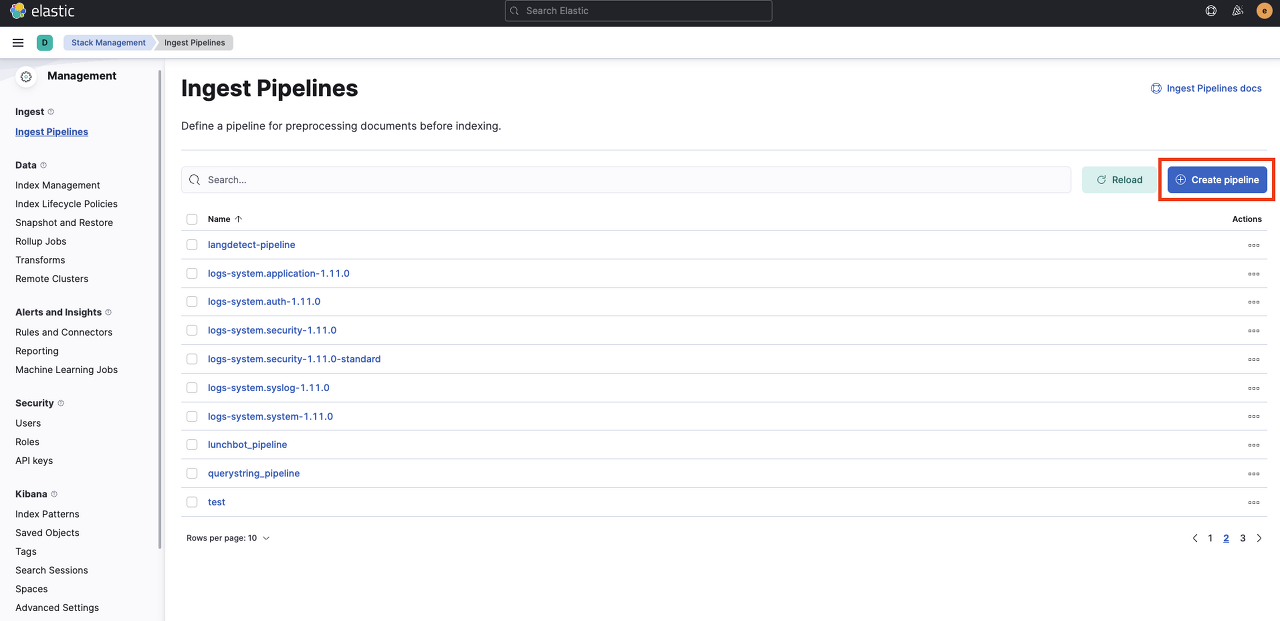
인제스트 파이프라인 디플로이먼트 생성
stack management > ingest pipeline 선택 > create pipeline
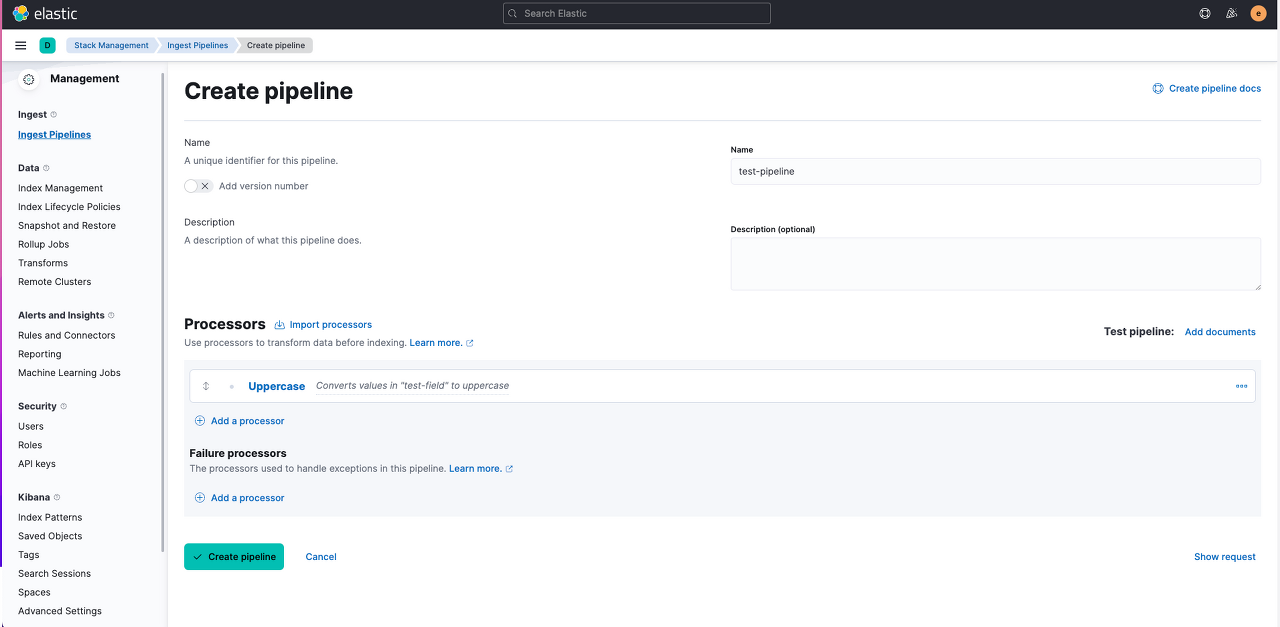
name : test-pipeline
processor : uppercase
field:test-field
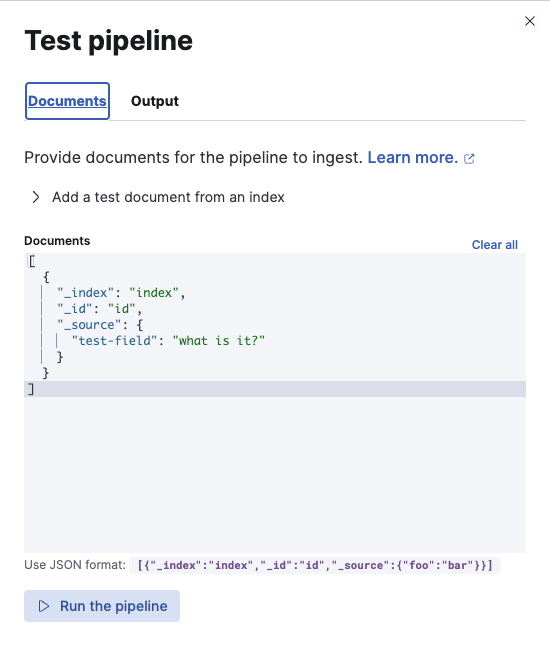
Test pipeline: Add documents를 클릭 하면 바로 파이프라인이 어떻게 작동하는지 테스트할 수 있다.
json format으로 테스트 파이프라인을 작성하고 Run the pipeline을 실행시키면 uppercase가 작동된 것을 확인할 수 있다.
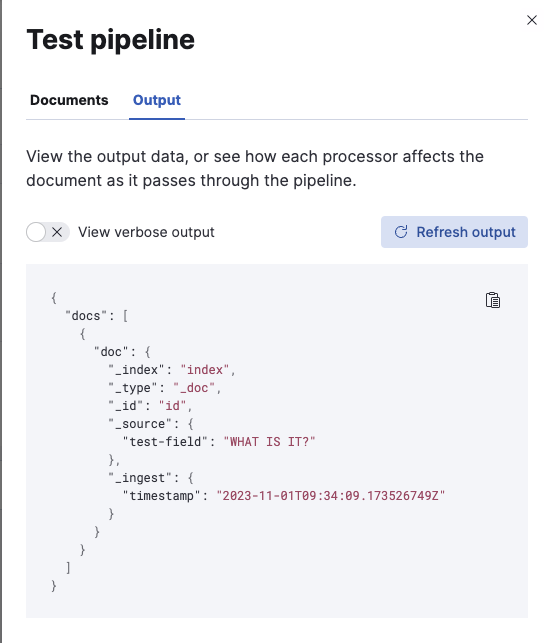
show request를 누르면 dev tools에 보내는 request도 볼 수 있으니 dev tools를 이용하여 pipeline을 만들 때 이용하면 된다.
운영 환경에서는 설치해야할 수집기가 많기 때문에 통합관리 기능이 필요하다. 다음번에는 운영 환경에서는 전체 파이프라인을 구성해야할때 어떻게 관리해야하는 지 알아보도록 하겠다.
