Semi-Supervised Learning
Supervised learning의 한계
Supervised Learning은 머신러닝의 대표적인 방법론 중 하나입니다. 이는 labeled data를 통해 데이터의 패턴을 학습하여 새로운 데이터에 대해 예측을 수행하는 방식입니다. 그러나 Supervised Learning에는 아래와 같은 몇 가지 한계점이 존재합니다.
- 데이터 레이블링 비용: 대량의 labeled data를 수집하는 것은 어려우며, 특히 고품질의 labeled data를 얻기 위해서는 상당한 비용과 시간이 필요합니다. 이는 labeling 작업에 전문성이 요구되거나 특정 지식이 필요한 경우 더욱 그렇습니다.
- 과적합(Overfitting) 문제: Supervised Learning은 종종 학습 데이터의 패턴을 "외우는" 경향이 있어, 학습 데이터에는 높은 성능을 보이지만 새로운 데이터에 대해서는 성능이 저하될 수 있습니다. 이를 일반화 성능의 부족이라고도 하며 특히 labeled data가 적을수록 과적합의 위험이 높아집니다.
- 일반화 성능: Supervised Learning의 성능을 향상시키기 위해 더 많은 labeled data가 필요하지만, 현실적으로 labeled data는 한정적이고 unlabeled data는 훨씬 많습니다. 따라서 labeled data의 부족이 성능 향상에 제한을 줄 수 있습니다.
Semi-Supervised Learning
Semi-Supervised Learning(준지도 학습)은 소량의 labeled data와 대량의 unlabeled data가 있을 때, 이 둘을 함께 사용해 학습 성능을 극대화하는 방법론입니다. labeled data에는 Supervised Learning을 적용하고, unlabeled data에는 Unsupervised Learning을 적용하여 모델의 일반화 성능을 높이는 것이 목표입니다. 이 접근법은 labeled data가 부족한 환경에서 unlabeled data를 통해 데이터 분포를 학습함으로써 성능 향상을 기대할 수 있습니다.
이러한 Semi-Supervised Learning은 의료 데이터나 웹 검색, 이미지 분류 등 대량의 unlabeled data가 있지만, labeled data를 구하기 어려운 상황에서 특히 유용합니다.
Semi-Supervised Learning의 기본 아이디어
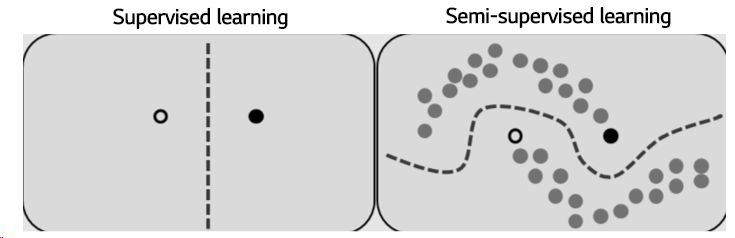
위의 그림을 보면 supervised learning의 decision boundary는 사실상 optimal하지 않고 unlabeled data를 활용하여 데이터 자체의 분포를 모델링하면 우측의 그림 처럼 더욱 optimal한 decision boundary를 얻을 수 있습니다.
Semi-Supervised Learning의 목적함수
Semi-Supervised Learning의 목적함수는 labeled data에 대한 Supervised Loss와 unlabeled data에 대한 Unsupervised Loss의 합을 최소화하는 것으로 표현할 수 있습니다. 이는 Supervised와 Unsupervised 학습을 한 번에, 즉 1-stage로 수행하는 것을 의미합니다. 이는 Self-Supervised Learning이나 Transfer Learning과의 차이점인데, 이들 방법론은 보통 2-stage로 학습을 진행합니다.
- L_s : labeled data에 대한 Supervised Loss로, target이 discrete value일 경우 classification loss(cross-entropy loss), continuous value일 경우 regression loss(mean squared error)를 사용합니다.
- L_u : unlabeled data에 적용되는 Unsupervised Loss로, 데이터의 본질적인 특성을 반영하도록 합니다. 여기서 unlabeled data에 주는 unsupervised task의 설정 방식에 따라 다양한 Semi-Supervised Learning 방법론이 나뉩니다.
Semi-Supervised Learning의 가정
Semi-Supervised Learning은 특정한 가정들을 기반으로 효과적으로 작동합니다. 이러한 가정들은 모델이 unlabeled data로부터 유용한 정보를 얻을 수 있도록 하는 이론적 근거를 제공합니다.
-
Smoothness Assumption
"만약 데이터 포인트 x1과 x2가 고밀도 지역에서 가깝게 위치한다면, 그 출력 y1과 y2도 가깝게 위치해야 한다."
- 같은 class와 cluster에 속하는 두 데이터가 고밀도 지역에 위치한다면, 해당 출력 값도 유사해야 한다는 가정입니다. 반대로, 두 데이터 포인트가 저밀도 지역에서 멀리 떨어져 있다면, 그 출력 값 역시 멀리 떨어져야 합니다. 이 가정은 classification 문제에서 특히 유용합니다.
-
Cluster Assumption
"만약 데이터 포인트들이 같은 cluster에 있다면, 그들은 같은 class일 것이다."
- 하나의 cluster는 하나의 class를 나타낼 수 있으며, decision boundary는 저밀도 지역을 통과하게 됩니다. 데이터가 클러스터 형태로 분포할 때, unlabeled data를 활용해 클러스터 내의 포인트들을 같은 class로 분류함으로써 성능을 높일 수 있습니다.
-
Manifold Assumption
"고차원의 데이터를 저차원 manifold로 표현할 수 있다."
- 고차원 공간에서 데이터 분포를 추정하거나 class 간의 구분을 명확히 하는 것은 어렵습니다. 그러나 데이터를 저차원 공간으로 투영할 수 있다면 unlabeled data를 통해 저차원 표현을 얻고, labeled data를 활용해 더 단순한 학습 작업을 수행할 수 있습니다. 이 가정은 차원 축소 기법을 활용하여 Semi-Supervised Learning의 성능을 높이는 데 기여합니다.
-
Low-Density Assumption
“ 분류기의 결정 경계(decision boundary)가 가급적 입력 공간에서 저밀도 지역을 통과해야한다.”
- Low-Density Assumption은 Smoothness Assumption의 연장선으로, decision boundary가 저밀도 지역을 지나도록 유도하여 데이터의 밀집된 영역에서는 동일한 label을 갖도록 합니다.
위 그림에서 Low-Density Assumption에 따르면, 최적의 decision boundary(점선)는 저밀도 지역을 통과하게 됩니다. 만약 labeled 데이터 5개만(표시된 포인트)을 사용해 지도 학습을 수행한다면, 데이터 간 연결선에 수직인 경계(실선)가 생성될 것입니다.
그러나 unlabeled data를 통해 더 많은 정보를 얻으면, 모델은 자연스럽게 데이터 밀도가 낮은 영역을 경계로 하여 최적의 decision boundary에 가까워집니다.
](https://velog.velcdn.com/images/kimdyun/post/a6925741-dfb9-4eb9-94a0-2f70c74b6df3/image.png)
