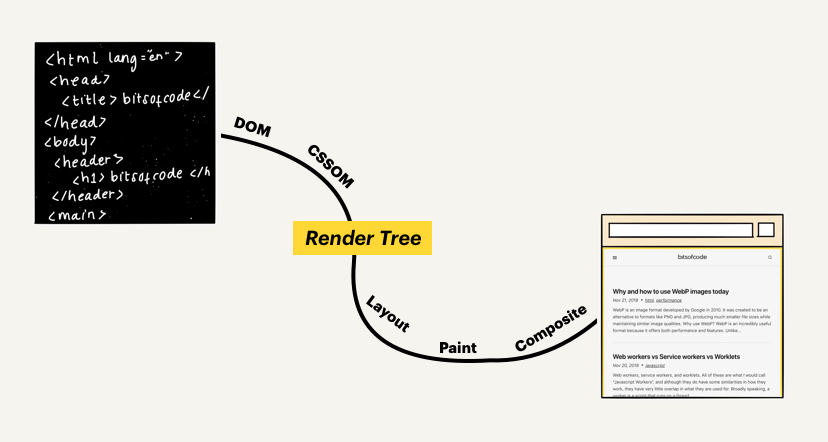
이 글은 Tali Garsiel의 "How Browsers Work: Behind the scenes of modern web browsers"를 번역한 글입니다.
Render tree construction
DOM 트리가 생성되는 동안, 브라우저는 Render Tree 를 생성합니다. Render Tree 는 시각적인 요소들을 화면에 나타나는 순서대로 가지고 있습니다. 이는 요소들을 올바른 순서대로 그리는 것을 목표로 합니다.
Firefox 는 Render Tree 의 요소를 Frames 라고 부릅니다. Webkit 에서는 renderer 혹은 render object 라고 부릅니다.
렌더러는 자신과 자식들을 어디에 어떻게 그려야하는지 알고 있습니다.
Webkit의 RenderObject 클래스는 렌더러의 기본 클래스로 아래와 같이 정의됩니다.
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}각 렌더러는 노드의 CSS 박스에 해당하는 사각형 공간을 나타냅니다. 이는 width, height, position 과 같은 기하학적인 정보도 포함합니다.
박스의 타입은 display 속성의 값에 영향을 받습니다. 아래의 코드는 Webkit이 display 값에 따라 생성할 렌더러의 종류를 결정하는 코드입니다.
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}element의 유형도 고려해야 합니다. Form coontorls 와 tables 은 특별한 구조를 가지고 있습니다.
Webkit에서 element가 특별한 렌더러를 생성해야한다면, createRenderer() 메소드를 오버라이드합니다. 이 때, 생성된 렌더러는 비기하학적인 정보를 포함한 스타일 객체를 나타냅니다.
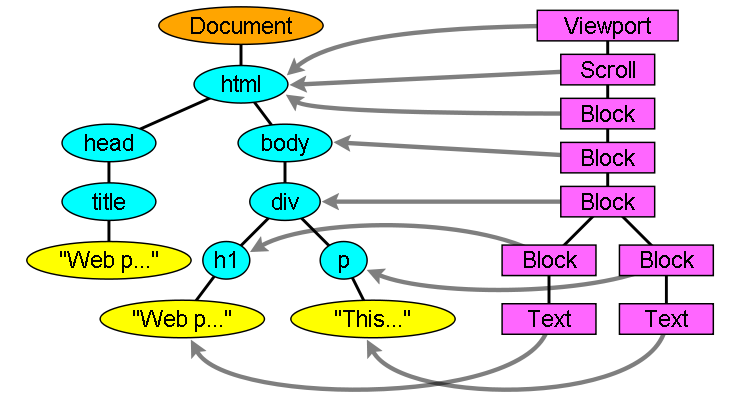
The render tree relation to the DOM tree
렌더러는 DOM의 노드를 가리키지만, 일대일 관계를 가지지 않습니다. head 나, display: none 과 같이 보이지 않는 요소는 Render Tree 에 추가되지 않습니다. 반면, visilibity: hidden 인 요소는 추가됩니다.
하나의 DOM 노드를 여러 렌더러가 가리키는 경우도 있습니다. 주로, 하나의 사각형으로 나타내기 힘든 복잡한 구조를 가졌을 때 위와 같은 상황이 발생합니다. 예를 들면 select 는 "Display area, Drop down list, Button" 을 위한 3개의 렌더러를 가지고 있습니다. 또한, 여러 라인의 text 는 각 라인마다 렌더러가 추가됩니다.
또 다른 예시는 Broken HTML 입니다. CSS 명세에 따르면, inline 요소는 block 요소와 inline 요소 중 하나만을 포함해야 합니다. 만약 두 가지 요소를 모두 포함한다면, 익명의 Block Renderer 가 추가되어inline 요소를 감싸게 됩니다.
Render Object 가 가리키는 DOM 노드와 트리의 같은 위치에 존재해야하는 것은 아닙니다. display: float 과 position: absolute 은 흐름을 벗어나 트리의 다른 위치에 배치됩니다. 원래 위치에는 Placeholder frame 이 자리합니다.
The flow of constructing the tree
Firefox에서 presentation 은 DOM의 리스너로 등록됩니다. Presentation 은 Frame 생성을 FrameConstructor 로 위임합니다. 그리고 이 생성자는 스타일을 계산하고 Frame 을 생성합니다.
Webkit은 스타일을 계산하고 렌더러를 생성하는 과정을 attachment 라고 부릅니다. 모든 DOM 노드는 attach 메소드를 가지고 있습니다. Attachment 는 동기적인 작업으로, 노드가 DOM 트리에 추가될 때마다 새로운 노드의 attch 메소드를 호출합니다.
html 과 body 태그를 처리하면 렌더 트리의 루트가 생성됩니다. Root render object 는 모든 다른 block 을 포함하는 최상위 block 인 containing block 을 나타냅니다. Firefox에서는 ViewPortFrame 으로, Webkit에서는 RenderView 라고 부릅니다. 문서는 Render Object 를 가리키고, 트리의 나머지는 DOM 노드를 추가하면서 생성됩니다.
Style Computation
Render Tree 를 생성하기 위해서는 각 Render Object 에 대한 시각적인 속성을 계산해야 합니다. 이는 각 element 의 스타일 속성을 계산하는 것을 의미합니다.
스타일은 HTML 시각적 속성, 인라인 스타일과 같이 다양한 방법으로 적용할 수 있습니다. HTML의 시각적 속성은 알맞은 CSS 스타일 속성으로 변환됩니다.
기본적인 스타일 시트는 브라우저의 스타일 시트입니다. 하지만, 스타일 시트는 개발자가 제공하기도 하고, 사용자가 커스텀하게 수정할 수도 있습니다. (Firefox에서는 "Firefox Profile" 폴더에 있는 스타일 시트를 변경할 수 있습니다.)
스타일 계산에는 몇 가지의 어려움이 있습니다.
- 스타일 데이터의 구조는 매우 크며, 매우 많은 속성들을 가지고 있어 메모리 문제가 발생할 수 있습니다.
- 최적화가 부족하다면 각
element에게 맞는 규칙을 찾는 것이 성능 문제를 발생시킬 수 있습니다. 모든element마다 모든 규칙을 순회하는 것은 매우 무거운 작업니다. 복잡한 선택자는 이미 틀린 것으로 확인된 경로부터 확인하여 다른 경로를 다시 확인해야 하는 것과 같이 성능 상 문제를 일으킬 수 있습니다. 아래의 선택자는 3개의 조상div가 있는div를 가리킵니다. 규칙을 적용할element를 확인하려면 트리에서 특정 경로를 택하여 순회해야합니다. 이 때, 규칙이 적용되지 않는다면 다른 경로를 선택하여 다시 순회해야합니다.
div div div div{
...
}- 규칙을 적용하는 것은 계층 구조를 파악해야하는 약간은 복잡한 과정을 포함합니다.
이제 브라우저에서 이러한 문제를 어떻게 해결하는 지 살펴보겠습니다.
Sharing style data
Webkit 노드는 Style Object 를 참조합니다. 이 객체는 특정 조건을 만족하면 다른 노드와 공유됩니다.
- 노드가 형제 혹은 사촌 관계에 있어야 합니다.
- 두 요소가 동일한
mouse state에 있어야 합니다. 예를 들어, 둘 중 하나만:hover일 수 없습니다. - id 값이 없어야 합니다.
- 태그가 동일해야 합니다.
- 클래스 속성이 동일해야 합니다.
- 지정된 속성이 동일해야 합니다.
link state와focus state가 동일해야 합니다.Attrtibute selector에 영향을 받아서는 안 됩니다.- 인라인 스타일을 사용해서는 안 됩니다.
- 형제 선택자를 사용해서는 안 됩니다.
WebCore는 형재 선택자를 만나면Global Switch를 열고 문서의 스타일 공유를 중단합니다. 형제 선택자에는+,:first-child,:last-child가 있습니다.
Firefox rule tree
Firefox는 스타일 계산을 쉽게 하기 위해 Rule tree 와 Style context tree 를 추가적으로 생성합니다. Webkit도 Style Object 를 생성하지만, 따로 트리를 생성하지는 않고 DOM 노드에서 관련된 스타일을 참조합니다.
Style Context 는 최종 값을 저장합니다. 이 값은 일치하는 규칙을 순서대로 적용하고, 실제 수치로 변환하는 과정을 통해 계산됩니다. 예를 들어, 화면의 백분율(%)로 값이 지정되어 있다면 이를 계산하여 픽셀 값으로 변환합니다. Rule tree 는 노드 사이에서 이 값을 공유하여 다시 계산하는 일을 방지합니다.
부합하는 모든 규칙은 Rule tree 에 저장됩니다. 노드의 레벨이 높아질수록 우선순위도 높아집니다. Rule tree 는 발견된 모든 규칙의 경로를 저장합니다. 규칙을 저장하는 작업은 Lazy하게 이루어집니다. 처음부터 모든 노드를 계산하는 것이 아니라 스타일이 필요할 때 계산하고 이 경로를 트리에 저장합니다.
트리의 경로를 lexcion에 있는 단어라고 생각할 수 있습니다. 아래와 같은 Rule Tree 가 있습니다.
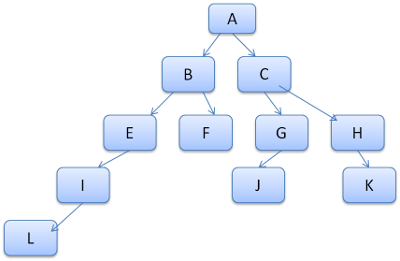
Content Tree 의 다른 노드에 맞는 규칙을 찾아야하고, 이 규칙이 "B-E-I" 라고 가정합시다. 위의 트리에는 이 규칙이 포함된 "A-B-E-I-L" 이라는 경로가 있습니다. 따라서, "B-E-I" 규칙은 이미 계산되었으므로 할 일이 줄었습니다.
이제 트리가 어떻게 작업량을 줄이는 살펴봅시다.
Division into structs
Style Context 는 구조체로 분리됩니다. 이 구조체는 border 나 color 같은 특정 카테고리의 스타일 정보를 저장합니다. 구조체의 모든 속성은 상속받았을수도, 그렇지 않았을 수도 있습니다. 상속받은 속성은 element 에서 정의되지 않았더라도, 부모로부터 상속받습니다. Reset 속성이라 불리는 상속받지 않은 속성은 정의되지 않았을 경우 기본값을 사용합니다.
Render Tree 는 계산된 최종 값을 가진 구조체를 트리에 캐싱합니다. 자식 노드가 구조체를 정의하고 있지 않다면, 캐시된 구조체를 부모로부터 받아서 사용합니다.
Computing the style contexts using the rule tree
특정 element 의 Style context 를 계산할 때, 가장 먼저 Rule Tree 의 경로를 계산하거나 이미 있는 경로를 사용합니다. 새로운 구조체를 만들기 위해 경로를 따라가면서 규칙을 적용합니다. 가장 높은 우선 순위를 가지는 리프 노드부터 시작해서 구조체가 모두 채워질 때까지 트리를 따라 올라갑니다. Rule Tree 의 노드에 구조체를 위한 선언이 없다면, 우리는 상당한 최적화를 진행할 수 있습니다. 구조체를 모두 채울 때 까지 트리를 따라 올라가면서 이를 적용합니다. 이 과정을 통해, 모든 구조체를 공유하여 최종 값의 계산 과정과 메모리를 절약해 최적화를 이루어냅니다.
구조체를 위한 정의를 발견하지 못한다면, 이 구조체는 inherited 타입이 되고, Context Tree 에서 부모의 구조체를 참조하여 구조체를 공유합니다. Reset 구조체인 경우, 기본 값을 사용합니다.
가장 구체적인 노드에 값을 추가하면 실제 값으로 변환하는 과정이 추가로 필요합니다. 결과 값은 트리의 노드에 저장되어 자식들이 사용할 수 있습니다.
같은 노드를 참조하는 형제를 가지고 있는 element 의 경우 Style Context 가 통채로 공유될 수 있습니다.
아래와 같은 HTML과 CSS가 있다고 가정합시다.
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>div {margin:5px;color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}color 구조체와 margin 구조체를 채워야한다고 가정합시다. color 구조체는 'color' 값만 저장하면 됩니다. margin 구조체는 "네 면의 margin" 값을 각각 저장해야 합니다.
아래와 같은 Rule Tree와 Context Tree 가 생성됩니다.
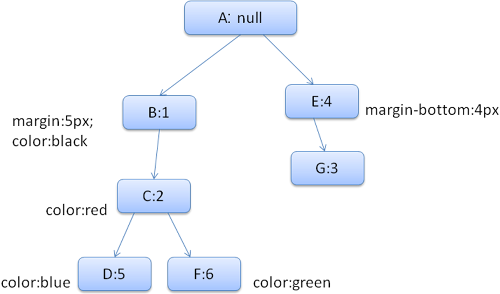
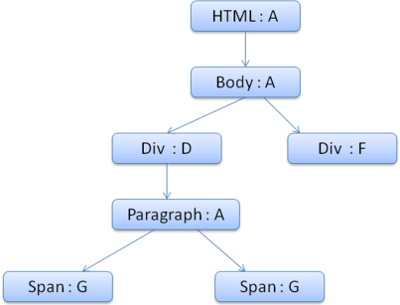
Context Tree (node name: rule node)
HTML을 파싱하고 두 번째 div 태그에 도달했다고 가정합시다. 이 노드를 위한 Style context 를 생성하고 스타일 구조체를 채워야합니다.
이 노드에 맞는 규칙은 1, 2, 6 번 규칙입니다. Rule Tree 를 보면, 사용할 수 있는 경로(B:1, C:2)를 찾을 수 있고 이 경로에 6번 규칙 노드만 추가하면 됩니다. Rule Tree 의 F 노드를 참조하는 Style Context 를 생성하고 Context Tree 추가합니다.
Style Context 를 생성했다면 이제 스타일 구조체를 채워야합니다. 먼저, margin 구조체부터 채울 것 입니다. F 노드부터 Rule Tree 를 따라가면 B 노드에 정의되어 있는 margin 값으로 margin 구조체를 채우게 됩니다.
이제 color 구조체를 채워야합니다. color 값이 정의되어 있으므로, 캐시되어 있는 구조체를 사용할 필요가 없습니다. 대신 최종 값을 계산하고, F 노드에 이 값을 캐싱합니다.
두 번째 span 태그는 훨씬 간단합니다. 맞는 규칙을 찾으면, 전에 나오는 span 태그와 동일하게 Rule Tree 의 G 노드를 참조하고 있음을 알 수 있습니다. 같은 노드를 참조하는 형제 element 가 있으므로, Style Context 를 공유합니다.
부모로부터 상속받는 규칙을 저장하는 구조체는 Context Tree 에서 캐싱합니다. (color 는 상속되지만, Firefox 에서는Reset 으로 간주하고, Rule Tree 에서 캐싱합니다.)
p 태그에 아래의 룰이 추가되었습니다.
p {font-family: Verdana; font size: 10px; font-weight: bold}만약 font 에 관한 규칙이 정의되지 않았다면 p 는 부모 노드와 font 구조체를 공유할 것입니다.
Webkit에서 Rule Tree 가 없다면, 일치하는 규칙을 4번 순회하게 됩니다. 먼저, display 속성과 같이 다른 속성에 영향을 주는 속성(non-important high priority properties)을 적용합니다. 이후로, high priority important, normal priority non-important, normal priority important 순서대로 적용합니다. 여려 번 등장하는 속성의 경우, 위의 순서에 따라 마지막에 등장하는 값이 적용됩니다.
스타일 객체를 공유하여, 위에서 언급했던 1번과 3번 이슈를 해결합니다. Firefox의 Rule Tree 는 속성을 정확한 순서대로 적용하는 것을 수월하게 합니다.
Manipulating the rules for an easy match
스타일을 적용하는 여러가지 방법이 있습니다.
- style 태그 내부 혹은 외부 css 파일에서 정의합니다.
p { color: blue }- 인라인으로 정의합니다.
<p style="color: blue" />- HTML visuaul attribute 를 사용해서 정의합니다.
<p bgcolor="blue" />아래 두 개의 방법은 자신만의 스타일 객체를 가지거나, HTML 속성을 이용하기 때문에 element 에 더욱 쉽게 적용될 수 있습니다.
위에서 언급했듯이, CSS 규칙을 적용하는 것은 까다로운 작업니다. 이를 해결하기 위해 규칙에 쉽게 접근할 수 있도록 해야 합니다.
스타일 시트를 파싱한 후, 규칙은 가장 오른쪽 선택자에 따라 여러 해시맵 중 하나에 추가됩니다. id, className, tagName 를 사용하는 해시맵 그리고 이에 속하지 않는 경우를 위한 해시맵이 있습니다. 이 과정은 규칙을 찾는 일을 훨씬 간단하게 합니다. 모든 규칙을 살펴보지 않고, 해시맵에서 element 와 관련 있는 규칙만을 찾을 수 있기 때문입니다. 이러한 최적화를 통해, 95% 정도의 규칙은 고려하지 않게 됩니다.
아래와 같은 HTML과 css가 있다고 가정합시다.
<p class="error">an error occurred </p>
<div id=" messageDiv">this is a message</div>p.error { color: red }
#messageDiv { height: 5px }
div { margin: 5px }첫 번째 규칙은 class 맵에 추가되고, 두 번째 규칙은 id 맵에, 그리고 마지막은 tag 맵에 추가됩니다.
가장 먼저 p 태그에 맞는 규칙을 찾을 것 입니다. class 맵에는 "error"를 키로 하는 규칙이 있습니다. div 는 id 맵과 tag 맵을 통해 규칙을 찾을 수 있습니다. 이제, 해시맵에서 나온 규칙 중에 실제로 일치하는 규칙을 찾으면 됩니다.
예를 들어, div 를 위한 규칙이 아래와 같다고 합시다
table div { margin: 5px }키가 div 이기 때문에, tag 맵에 있지만, 이 규칙은 table 이 조상이기 때문에, 위의 div 에는 적용되지 않습니다.
Webkit과 Firefox 모두 이 과정을 진행합니다.
Applying the rules in the correct cascade order
스타일 객체는 모든 CSS 규칙을 포함하고 있습니다. 정의되지 않은 속성은, 부모의 스타일 객체로부터 상속받을 수 있고, 그렇지 않은 경우에는 deafult value 로 설정됩니다.
한 번 이상 정의되는 경우에는 '어떤 순서대로 정의해야 하는가' 도 하나의 문제입니다.
Style shhet cascade order
스타일 속성 선언은 여러 스타일 시트에서 여러 번 나타날 수 있습니다. 그렇다면, 규칙을 적용하는 순서도 매우 중요합니다. 이를 cascade order 라고 부르며, CSS 명세에는 아래와 같이 정의하고 있습니다.
- Browser declarations
- User normal declarations
- Author normal declarartions
- Author important declarations
- User important declarations
브라우저의 규칙의 중요도가 가장 낮고, 사용자가 important 로 규칙을 표시하면 개발자의 규칙을 덮어 쓸 수 있습니다. 중요도가 같은 규칙의 경우, specificity 에 의해 결정됩니다. HTML visual attribute는 CSS로 변환되고, 개발자가 정의한 것으로 여겨집니다.
Specificity
CSS 명세에 정의된 선택자 specificity 는 아래와 같습니다.
- 선택자 없이 선언된
style속성은 1, 그렇지 않으면 0 입니다. (=a) - 선택자의
id개수 (=b) - 클래스, 속성 선택자, 가상 클래스 선택자의 개수 (=c)
- 태그, 가상 요소 선택자의 개수 (=d)
위의 4가지 숫자를 순서대로 연결하면 specificity 가 됩니다.
위의 숫자 중 가장 큰 숫자에 의해서 사용할 진법이 결정됩니다. 예를 들어, a=14 이면 16진법을 사용할 수 있습니다. 선택자에 17개의 태그가 있는 특이한 경우에는 17진법을 사용할 수도 있습니다.
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */Sorting the rules
맞는 규칙을 발견한 후에, 이 규칙은 cascade rule 에 따라 정렬됩니다. Webkit은 규칙이 적을 경우에는 버블 소트를, 많은 경우에는 머지 소트를 사용합니다. Webkit은 ">" 를 오버라이드해서 소팅을 구현했습니다.
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}Gradual process
Webkit은 @imports 를 포함한 모든 top level 스타일 시트가 로드되었는지 확인하기 위해서 flag 를 사용합니다. Attachment 도중, 스타일이 완전히 로드되지 않았다면, 마킹된 상태의 placeholder 를 사용하고, 스타일이 완전히 로드되면 다시 한 번 계산합니다.
참고 자료
How Browsers Work: Behind the scenes of modern web browsers
브라우저는 어떻게 동작하는가?
