"상품명"에서 어떻게 유의미한 키워드를 추출 할 것인가.
몇몇 커머스회사에서 안타깝게도, 가장 쉬우면서 효율적인 방법을 잘 몰라서 너무 어려운 방법으로 검색품질을 높이려고 하는 모습들을 보았습니다.
저의 경험 내에서 쉽고 간단하면서도 큰 효과를 볼 수 있는 방법 중에 제가 가장 No.1으로 뽑는 방법을 소개드리려고 합니다.
참고로 전 "잇어빌리티"를 지양합니다.~~
Case
- 커머스 검색을 처음 도입한 경우.
- 도입한지 얼마 안되어서 검색 품질을 빠르게 올리고 싶은 경우.
- 검색을 위한 기초 데이터셋, 즉 키워드사전 정보가 없을 경우.
필수 조건
- 검색 로그가 수집 중인 경우.
- 상품 Category ID가 관리되고 있는 경우.
Query Tags 활용
- Query Tags란. 사용자 질의(Query)로 부터 유의미한 Keyword 또는 Word Set.
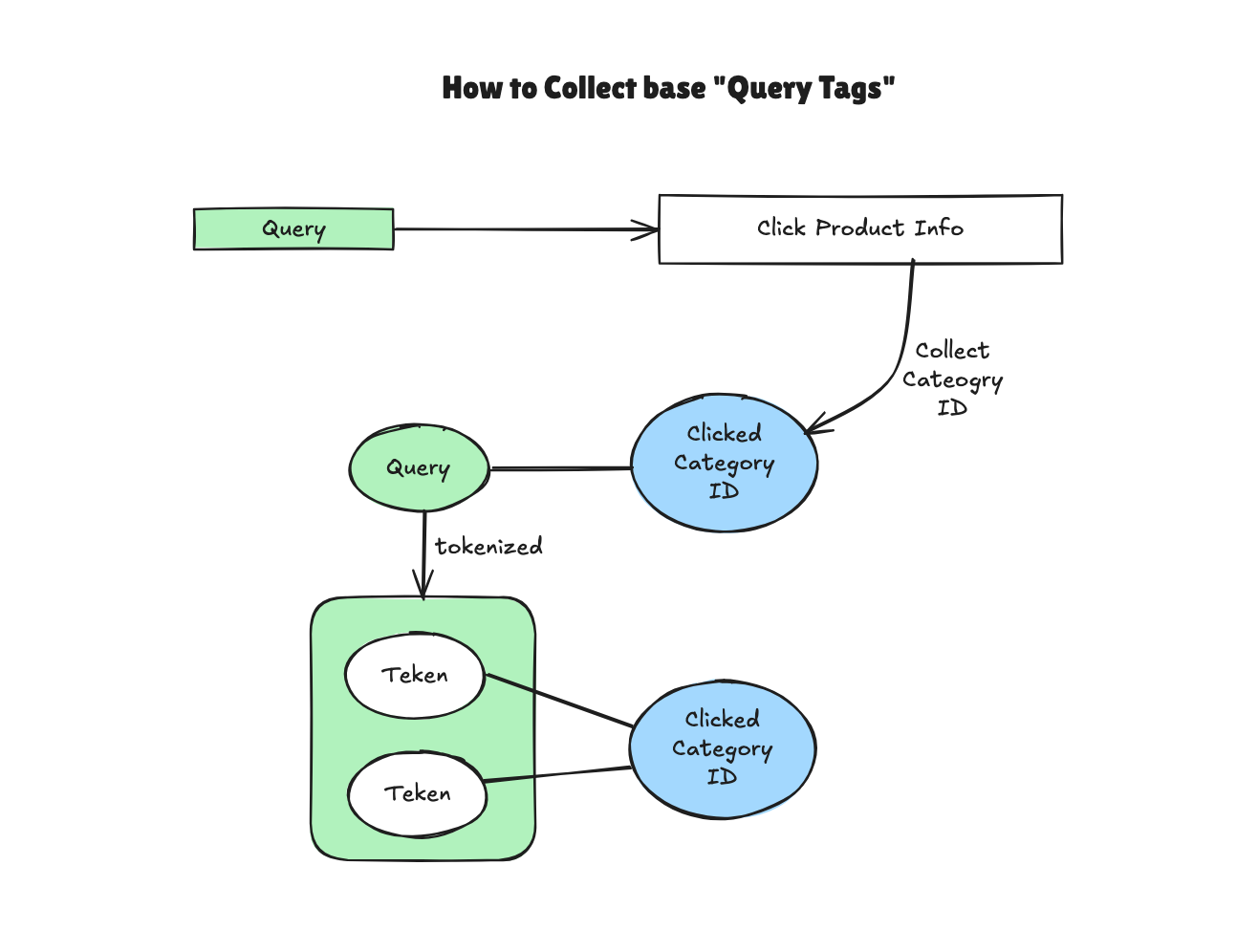
- 가장 기초적인 "Query Tags"를 수집하는 방법
- 상품 Click Log를 이용해서, 질의(Query)별 클릭한 상품의 Category ID를 수집합니다.
물론, 잘못된 클릭으로 수집된 데이터가 있으므로, 의미 있는 클릭에 대해서만
Normalization하여 수집합니다.
- Query에 대해서 Tokenizer를 활용하여, Token으로 분리 합니다. 만약 Tokenizer가 없다면 Opensource를 사용해도 되고, Space Tokenizer로만 사용해도 가능합니다.
- 이렇게 분리된 Token을 수집된 Category ID로 묶습니다. 물론 여기에도 의미 없는 token을 걸러내면 좋습니다. 예를 들어 빈도수(Exposure)가 현저히 낮는 token들은 버립니다.
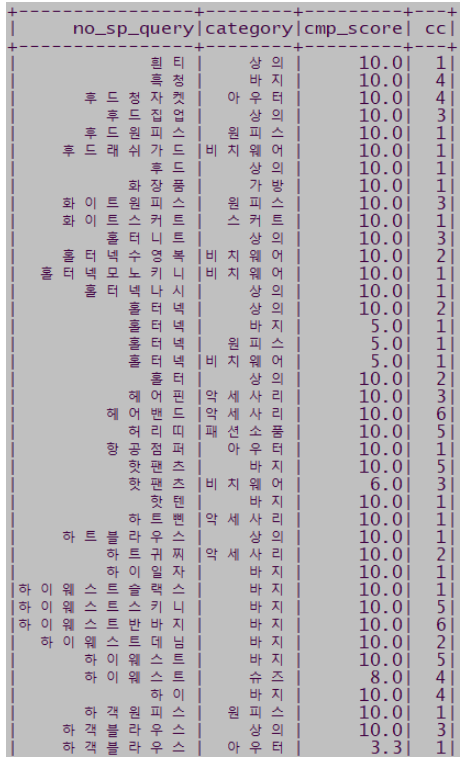
- 수집된 데이터를 기반으로 Query Tags는 아래와 같이 표현됩니다.
- 알아보기 쉽게 아래 예시는 Category ID 대신 카테고리명(category)로 표현했습니다.
- cmp_score는 Token 과 Category ID의 노출빈도(Exposure)를 점수로 표현했습니다.
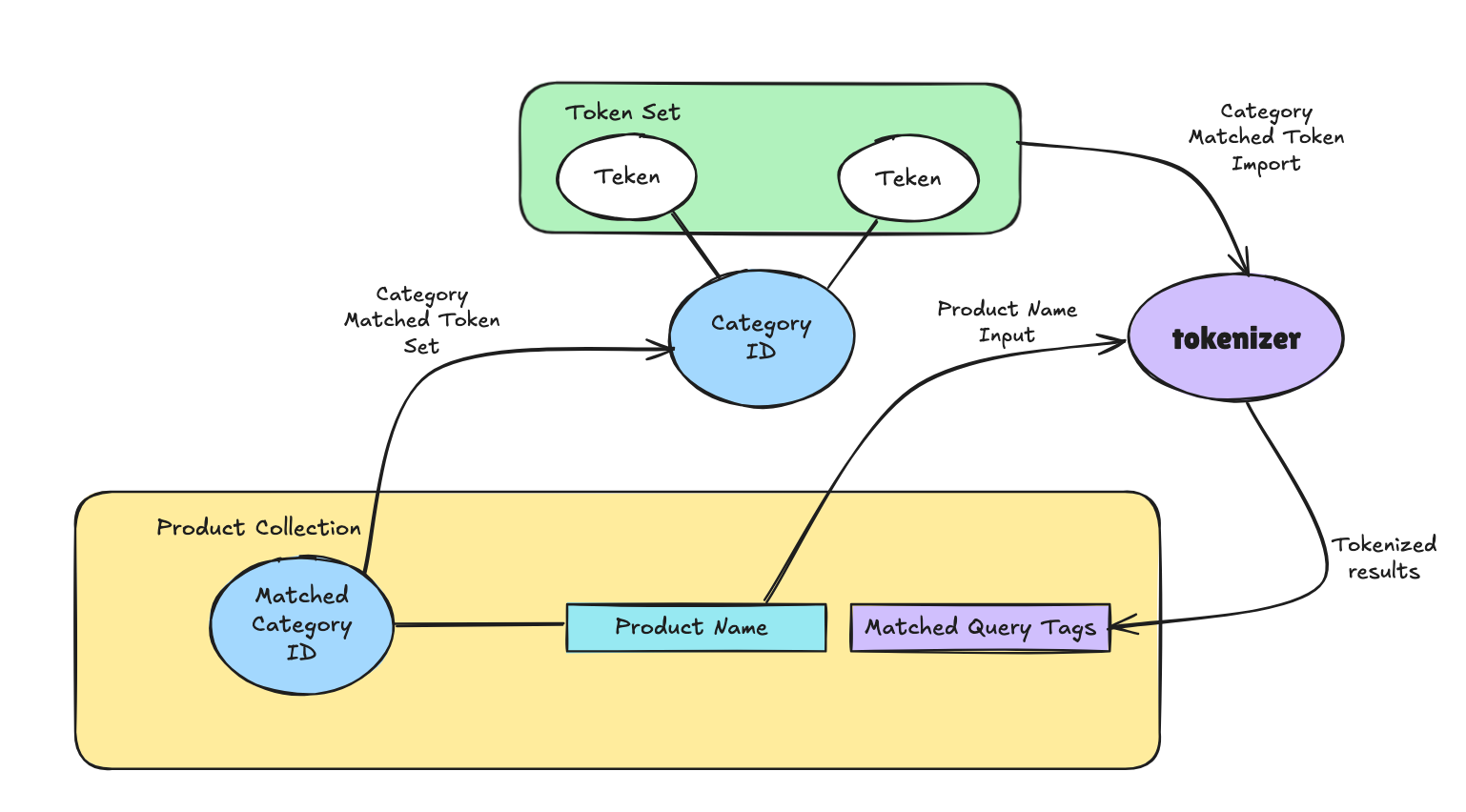
- 수집된 Query Tags를 상품 검색을 위한 Collection에 사용하는 방법
- 상품의 매칭된 Matched Category ID에 해당하는 Query Tags로 부터 Token Set를 가지고 상품명(Product Name)을 Tokenize합니다.
- 이렇게 상품명(Product Name)을 Token으로 분리된 것을 Matched Query Tags로 표현합니다.
- 아래 예시에서는 title(Product Name), matched_tags(Matched Query Tags)로 표현 되었습니다. 그외 t1000_tag는 나중에 자세히 다룰 것입니다.

- 반드시 상품의 매칭된 Category ID에 종속된 token set를 사용해서 tokenize하는 이유는 해당 카테고리에 유저들이 찾는 단어셋을 상품명에서 추출하기 위함입니다.
예를 들어 상품명이 “[삼성카드할인] 현대백화점 리바이스 511 진청 청바지” 이라고 할때 “청바지”카테고리내에선 “삼성카드”, “현대백화점“ 같은 단어가 유저들에겐 큰의미를 두지 않기 때문에 필터링 하기 위함입니다.
- 검색 랭킹에 적용
- 상품 Colletions에서 추출된 "Matched Query Tags"를 필드별 가중치, 즉 FMP(Field Mapping Probablity)로 주면 기존 보다 나은 검색 품질을 보여줍니다.


서비스에 죽고 못사는 개발자