
9. 서브쿼리 활용하기
9.1 서브쿼리란
9.1.1 서브쿼리의 개념
서브쿼리(subquery)란 쿼리 안에 포함된 또 다른 쿼리를 말하는 것으로, 안쪽 서브쿼리의 실행 결과를 받아 바깥쪽 메인쿼리가 실행됩니다.
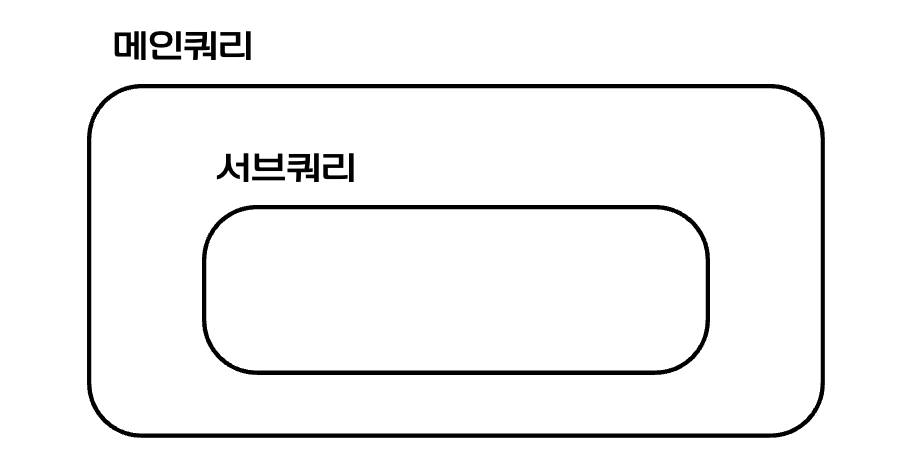
9.1.2 서브쿼리의 특징
1. 중첩 구조임
서브쿼리는 메인쿼리 내부에 중첩해 작성합니다. ()(괄호) 안에 서브쿼리를 작성해 메인쿼리의 일부로 사용합니다.
SELECT 컬럼명1, 컬럼명2, ...
FROM 테이블명
WHERE 컬럼명 연산자 (
서브쿼리
);2. 메인쿼리와는 독립적으로 실행됨
서브쿼리는 메인쿼리와는 별개로 독립적으로 실행됩니다. 서브쿼리가 자체적으로 실행한 결과를 반환하면, 메인쿼리가 이를 받아 최종 실행합니다.
3. 다양한 위치에서 사용 가능
서브쿼리는 SQL의 여러 절에서 사용할 수 있습니다.
대표적으로 SELECT, FROM, JOIN, WHERE, HAVING 절에서 사용할 수 있습니다.
4. 단일 값 또는 다중 값을 반환함
서브쿼리는 실행 결과를 단일 값 또는 다중 값으로 반환합니다. 이를 각각 단일 값 서브쿼리, 다중 값 서브쿼리라고 합니다.
단일 값 서브쿼리(single-row subquery)
- 서브쿼리를 실행하면 하나의 값을 반환합니다.
- 단일 값으로 반환된 결과는 메인쿼리에서 받아 비교 연산자(
=, !=, >, <, >=, <=)와 함께 사용됩니다.
다중 값 서브쿼리(multiple-row subquery)
- 서브쿼리를 실행하면 여러 개의 값을 반환합니다.
- 다중 값으로 반환된 결과는 메인쿼리에서 받아
IN, ANY, ALL, EXIST연산자와 함께 사용됩니다.
5. 조건 필터링 결과 또는 데이터 집계 결과를 반환함
서브쿼리는 메인쿼리에 특정 조건으로 필터링한 결과나 특정 연산에 따라 집계된 데이터를 제공합니다. 따라서 좀 더 복잡하고 정교한 데이터 분석을 할 때 유용합니다.
9.2 다양한 위치에서의 서브쿼리
서브쿼리는 SQL 문장의 여러 위치에서 사용될 수 있으며, 위치에 따라 그 역할과 동작 방식이 달라집니다.
9.2.1 SELECT 절에서의 서브쿼리
각 행마다 서브쿼리 결과를 계산해 새로운 열로 출력합니다. 주로 비교 기준이 되는 전체 평균, 최댓값 등을 함께 출력할 때 사용합니다.
이를 스칼라 서브쿼리(Scalar Subquery) 라고도 합니다.
예시
SELECT name, (SELECT AVG(score) FROM exams) AS avg_score
FROM students;9.2.2 FROM 절에서의 서브쿼리
서브쿼리 결과를 임시 테이블처럼 사용합니다. 이를 인라인 뷰(inline view) 라고도 합니다.
예시
SELECT sub.name, sub.total
FROM (
SELECT name, SUM(score) AS total
FROM exams
GROUP BY name
) AS sub
WHERE sub.total > 250;9.2.3 JOIN 절에서의 서브쿼리
조인 대상 테이블 중 하나를 서브쿼리로 대체하여 조건에 맞는 데이터만 조인할 수 있습니다.
예시
SELECT u.name, p.filename
FROM users u
JOIN (
SELECT * FROM photos
WHERE created_at >= '2024-01-01'
) p
ON u.id = p.user_id;9.2.4 WHERE 절에서의 서브쿼리
서브쿼리 결과를 조건값으로 사용할 수 있습니다. 가장 일반적으로 사용되는 방식입니다.
이를 중첩 서브쿼리라고도 합니다.
예시
SELECT name
FROM students
WHERE score > (SELECT AVG(score) FROM students);9.2.5 HAVING 절에서의 서브쿼리
그룹화된 결과에 조건을 적용할 때 유용합니다. 집계된 결과를 기준으로 서브쿼리의 값과 비교합니다.
WHERE 절에서의 서브쿼리와 마찬가지로, 이를 중첩 서브쿼리라고도 합니다.
예시
SELECT class_id, AVG(score) AS avg_score
FROM exams
GROUP BY class_id
HAVING AVG(score) > (SELECT AVG(score) FROM exams);9.3 IN, ANY, ALL, EXIST
9.3.1 IN 연산자
IN 연산자는 지정된 집합에 포함되는 대상을 찾습니다.
IN (값1, 값2)와 같은 형태로 ,(쉼표)로 구분된 값 목록을 입력받거나 IN (서브쿼리) 형태로 다중 행의 단일 컬럼(N x 1)을 반환하는 서브쿼리를 입력받습니다.
SELECT 컬럼명1, 컬럼명2, ...
FROM 테이블명
WHERE 컬럼명 IN (쉼표로_구분된_값_목록);
-- 또는
SELECT 컬럼명1, 컬럼명2, ...
FROM 테이블명
WHERE 컬럼명 IN (다중_행의_단일_컬럼을_반환하는_서브쿼리);9.3.2 ANY 연산자
ANY 연산자는 지정된 집합의 모든 요소와 비교 연산을 수행해 하나라도 만족하는 대상을 찾습니다.
다음 형식에 볼 수 있듯 다중 행의 단일 컬럼(N x 1)을 반환하는 서브쿼리를 입력으로 받습니다.
SELECT 컬럼명1, 컬럼명2, ...
FROM 테이블명
WHERE 컬럼명 비교_연산자 ANY (다중_행의_단일_컬럼을_반환하는_서브쿼리);9.3.3 ALL 연산자
ALL 연산자는 지정된 집합의 모든 요소와 비교 연산을 수행해 모두를 만족하는 대상을 찾습니다.
ANY 연산자가 집합의 요소 중 하나라도 만족하는 대상을 찾는다면 ALL 연산자는 모두를 만족하는 대상을 찾습니다. ALL 연산자는 ANY 연산자와 마찬가지로 다중 행의 단일 컬럼(N X 1)을 반환하는 서브쿼리를 입력받습니다.
SELECT 컬럼명1, 컬럼명2, ...
FROM 테이블명
WHERE 컬럼명 비교_연산자 ALL (다중_행의_단일_컬럼을_반환하는_서브쿼리);9.3.4 EXIST 연산자
EXIST 연산자는 서브쿼리를 입력받아 서브쿼리가 하나 이상의 행을 반환하는 경우 TRUE를, 그렇지 않으면 FALSE를 반환합니다.
이때 서브쿼리가 반환하는 행의 개수나 컬럼의 내용에는 제한이 없습니다 (컬럼의 내용에 제한이 없다고 한 이유는 컬럼에 값이 있는지 없는지만 보기 때문입니다).
SELECT 컬럼명1, 컬럼명2, ...
FROM 테이블명
WHERE EXIST (서브쿼리);9.4 상관 쿼리(correlated subquery)
상관 쿼리는 메인쿼리의 각 행에 대해 반복 실행되는 서브쿼리로, 서브쿼리가 메인쿼리의 컬럼 값을 참조합니다.
상관 쿼리는 상호 의존 관계를 가진 메인쿼리와 서브쿼리 간 특정 조건을 만족하는 튜플을 찾는 데 사용합니다.
상관 쿼리의 주요 특징은 다음과 같습니다.
9.4.1 의존성
서브쿼리는 메인쿼리의 값을 참조해 데이터 필터링을 수행합니다.
9.4.2 반복 실행
서브쿼리는 메인쿼리의 각 행에 대해 반복적으로 실행됩니다.
9.4.3 성능 저하
메인쿼리의 각 행마다 서브쿼리를 실행하므로 쿼리 전체의 성능이 저하될 수 있습니다. 데이터 양이 많을 경우 특히 그렇습니다.
9.5 정리
9.5.1 서브쿼리
쿼리 안에 포함된 또 다른 쿼리를 말합니다. 서브쿼리는 메인쿼리의 일부로 사용되며, 메인쿼리는 서브쿼리의 결과를 이용해 최종 실행됩니다. 서브쿼리를 이용하면 보다 복잡한 데이터 조회 및 분석을 할 수 있습니다.
SELECT 컬럼명1, 컬럼명2, ...
FROM 테이블명
WHERE 컬럼명 연산자 (
서브쿼리
);9.5.2 SELECT 절에서의 서브쿼리 (스칼라 서브쿼리)
SELECT 절에서의 서브쿼리는 실행 결과로 단일 값(1 x 1)을 반환해야 합니다.
9.5.3 FROM 절에서의 서브쿼리 (인라인 뷰)
FROM 절에서의 서브쿼리는 반환하는 행과 컬럼의 개수에 제한은 없습니다. 다만 결과 테이블에 반드시 별칭을 지정해야 합니다.
9.5.4 JOIN 절에서의 서브쿼리
JOIN 절에서의 서브쿼리도 반환하는 행과 컬럼의 개수에 제한은 없습니다. 다만 결과 테이블에는 반드시 별칭을 지정해야 합니다.
9.5.5 WHERE 절에서의 서브쿼리 (중첩 서브쿼리)
WHERE 절에서의 서브쿼리는 단일 값(1 x 1) 또는 다중 행의 단일 컬럼(N x 1)을 반환할 수 있습니다.
만약 단일 값을 반환할 경우 메인쿼리에서는 비교 연산자(=, !=, >, <, >=, <=)를 사용하고,
다중 행의 단일 컬럼을 반환할 경우 메인쿼리에서는 IN, ANY, ALL, EXIST 연산자를 사용합니다.
9.5.6 HAVING 절에서의 서브쿼리 (중첩 서브쿼리)
HAVING 절에서의 서브쿼리는 그룹화 필터링을 수행하기 위한 것이므로
WHERE 절의 서브쿼리와 같이 단일 값(1 x 1) 또는 다중 행의 단일 컬럼(N x 1)을 반환할 수 있습니다.
9.5.7 IN 연산자
지정된 집합에 포함되는 대상을 찾습니다.
IN (값1, 값2)과 같은 형태로 ,(쉼표)로 구분된 값 목록을 입력받거나
IN (서브쿼리) 형태로 다중 행의 단일 컬럼(N x 1)을 반환하는 서브쿼리를 입력받습니다.
컬럼명 IN (쉼표로_구분된_값의_목록)
-- 또는
컬럼명 IN (다중_행의_단일_컬럼을_반환하는_서브쿼리)9.5.8 ANY 연산자
지정된 집합의 모든 요소와 비교 연산을 수행해 하나라도 만족하는 대상을 찾습니다.
다중 행의 단일 컬럼(N x 1)을 반환하는 서브쿼리를 입력받습니다.
컬럼명 비교_연산자 ANY (다중_행의_단일_컬럼을_반환하는_서브쿼리)9.5.9 ALL 연산자
지정된 집합의 모든 요소와 비교 연산을 수행해 모두를 만족하는 대상을 찾습니다.
ANY 연산자와 마찬가지로 다중 행의 단일 컬럼(N x 1)을 반환하는 서브쿼리를 입력받습니다.
컬럼명 비교_연산자 ALL (다중_행의_단일_컬럼을_반환하는_서브쿼리)9.5.10 EXISTS 연산자
서브쿼리를 입력받아 서브쿼리가 하나 이상의 행을 반환하는 경우 TRUE를, 그렇지 않으면 FALSE를 반환합니다.
서브쿼리가 반환하는 행의 개수나 컬럼의 내용에는 제한이 없습니다.
SELECT 컬럼명1, 컬럼명2, ...
FROM 테이블명
WHERE EXISTS (서브쿼리);9.5.11 상관 쿼리
메인쿼리의 각 행에 대해 실행되며 서브쿼리가 메인쿼리의 컬럼 값을 참조하는 쿼리입니다.
상호 의존 관계를 가진 메인쿼리와 서브쿼리 간 특정 조건을 만족하는 튜플을 찾는 데 사용합니다.
