자료구조
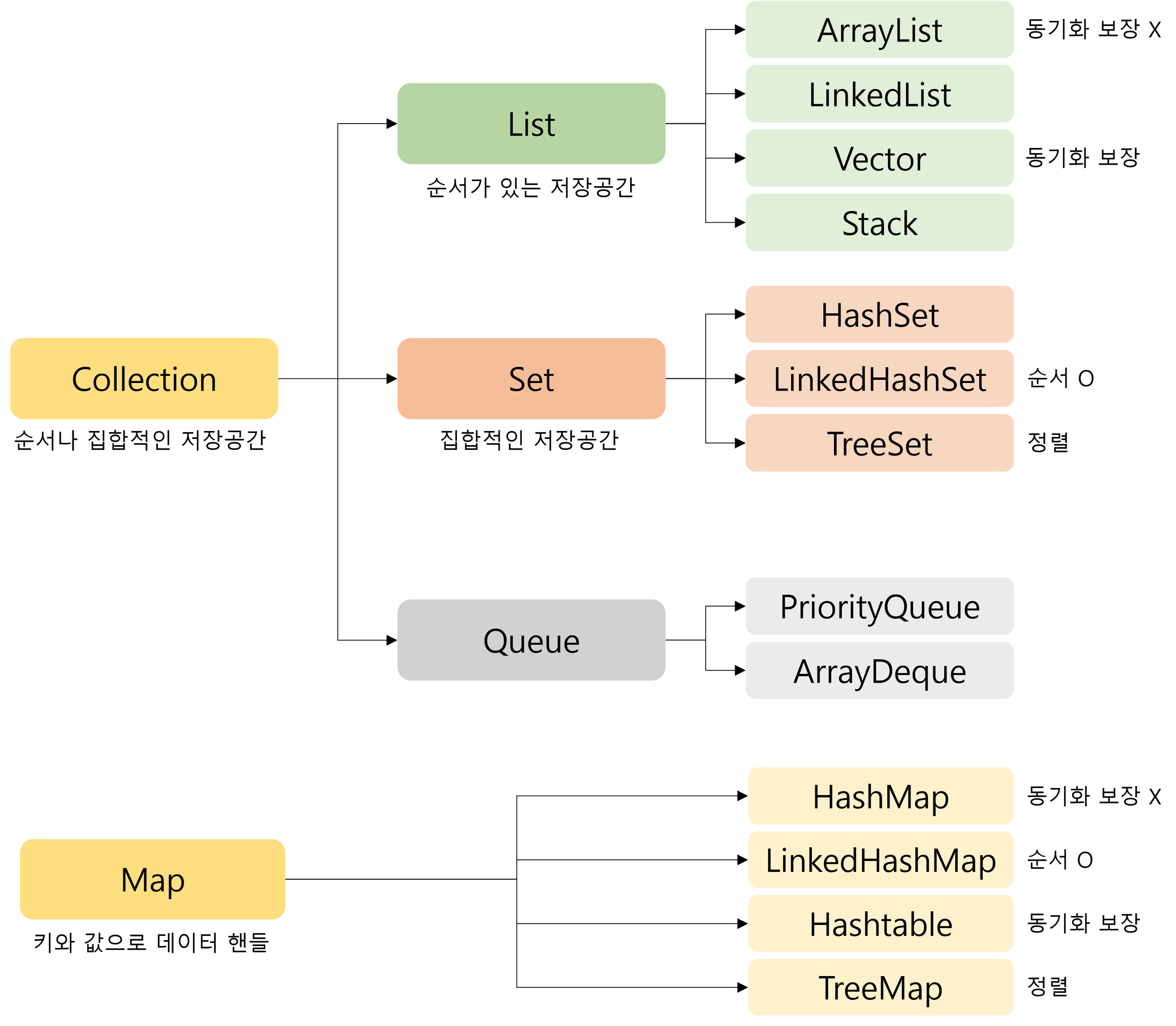
- Collection은 value를 나열하며, Map은 key-value 쌍으로 이루어져 있습니다.
- Collection과 Map 모두 참조 자료형(객체)만 저장하고 이용할 수 있습니다. 기본 자료형의 경우 Wrapper Class를 활용하여 사용합니다.
| List | Set | Map |
|---|---|---|
| - 순서를 유지하고 저장 - 중복 저장 가능 | - 순서를 유지하지 않고 저장 - 중복 저장 안 됨 | - 키와 값의 쌍으로 저장 - 순서를 유지하지 않고 저장 - 키는 중복 저장 안 됨 |
배열 (Array)
- 선형으로 자료를 관리
- 정해진 크기의 메모리를 먼저 할당받아 사용
- 자료의 물리적 위치와 논리적 위치가 같음(index와 value값으로 구성)
1) List 인터페이스
index 라는 식별자로 순서를 가지며, 데이터의 중복을 허용하는 자료구조.
ArrayList
-
단방향 포인터 구조로 각 데이터에 대한 인덱스를 가지고 있어 조회 기능에 성능이 뛰어남
-
배열과 달리 초기크기를 지정하지 않아도 되므로, 삽입 삭제가 자유로움
-
내부적으로 배열 구조를 사용하고 있으므로 중간에 데이터가 추가되거나 삭제될 경우 기존 데이터를 복사해 새로운 구조를 만들어야 하기 때문으로 이와 같은 경우에는 LinkedList 를 사용할 것을 권장
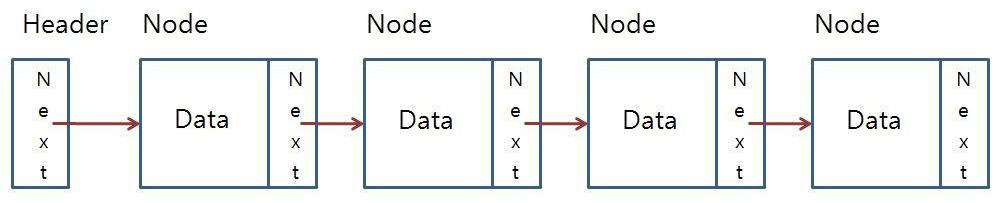
LinkedList
-
메모리 여러 곳에 실제값을 담아놓고, 실제값이 있는 주소값으로 데이터를 저장하는 리스트
-
불연속적으로 존재하는 데이터를 서로 연결(link)한 형태로 구성
-
각각의 노드는 데이터와 함께 next(다음 노드)와 prev(이전 노드) 값을 내부적으로 가지고 있음
-
중간에 데이터를 추가나 삭제하더라도 전체의 인덱스가 한 칸씩 뒤로 밀리거나 당겨지는 일이 없기에 ArrayList에 비해서 데이터의 추가나 삭제가 용이
-
인덱스가 없기에 특정 요소에 접근하기 위해서는 순차 탐색이 필요로 하여 탐색 속도가 떨어진다는 단점
Vector
- 과거에 대용량 처리를 위해 사용했으며, 내부에서 자동으로 동기화처리가 일어나 비교적 성능이 좋지 않고 무거워 잘 쓰이지 않음
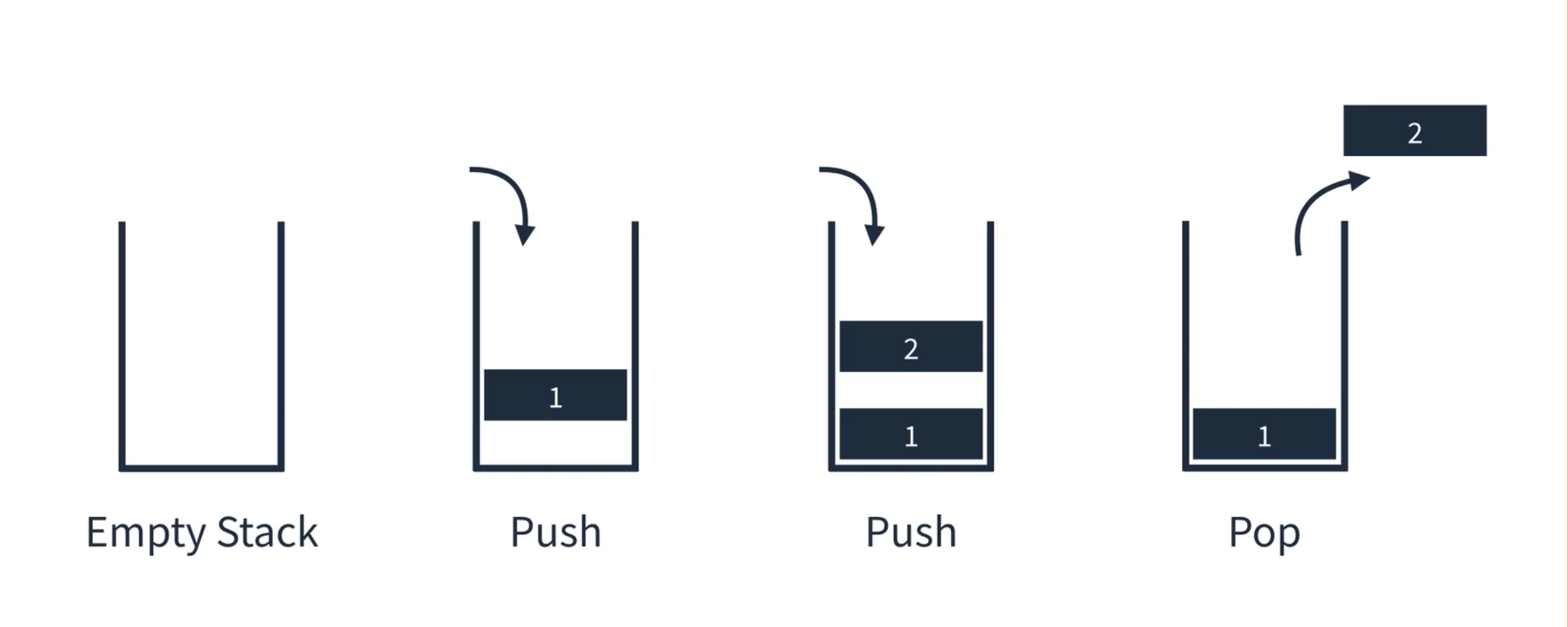
스택 (Stack)
- 가장 나중에 입력 된 자료가 가장 먼저 출력되는 자료 구조 (Last In First OUt)
2) Set 인터페이스
순서가 없고, 데이터 유일성(중복 X)을 가지는 자료구조.
HashSet
- 가장빠른 임의 접근 속도
- 순서를 예측할 수 없음
TreeSet
- 레드 블랙 트리(이진 탐색 트리(BinarySearchTree)) 구조
- 오름차순으로 데이터를 정렬

레드 블랙 트리는 부모노드보다 작은 값을 가지는 노드는 왼쪽 자식으로, 큰 값을 가지는 노드는 오른쪽 자식으로 배치하여 데이터의 추가나 삭제 시 트리가 한쪽으로 치우쳐지지 않도록 균형을 맞추어줍니다.
3) Map 인터페이스
- 키(Key), 값(Value)의 쌍으로 이루어진 자료구조
- 순서가 없고, 키(Key)는 유일성을 가지고, 값(Value)의 중복은 허용한다.
Hashtable
- HashMap보다는 느리지만 동기화 지원
- Thread-safe
- null불가
HashMap
- 중복과 순서가 허용되지 않으며 key값에도 null값이 올 수 있다.
TreeMap
- 레드 블랙 트리(이진 탐색 트리(BinarySearchTree)) 구조로 treeSet과 달리 키와 값이 저장된 Map, Etnry를 저장
- TreeMap은 일반적으로 Map으로써의 성능이 HashMap보다 떨어짐
- 하지만 정렬된 순서대로 키(Key)와 값(Value)을 저장하여 검색이 빠름
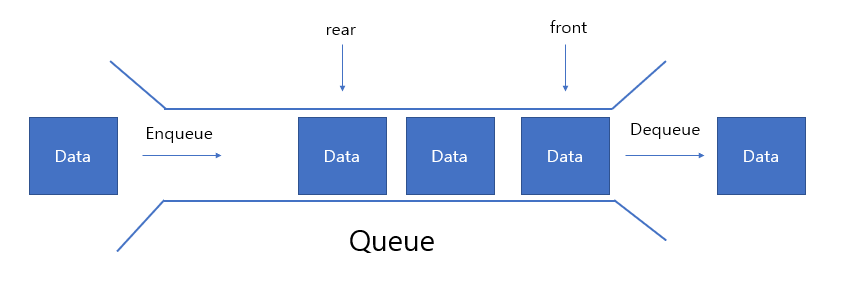
4) Queue
- 맨 앞에서 자료를 꺼내거나 삭제하고, 맨 뒤에서 자료를 추가하는 Fist In First Out (선입선출) 구조
- 순차적으로 입력된 자료를 순서대로 처리하는데 많이 사용 되는 자료구조
Queue는 LinkedList의 생성자를 사용
ex)Queue<String> queue = new LinkedList<>();
Priorty Queue
- 들어간 순서에 상관없이 우선순위가 높은 데이터가 먼저 나오는 구조
- 일반적인 Queue와 달리 힙(Heap) 자료구조
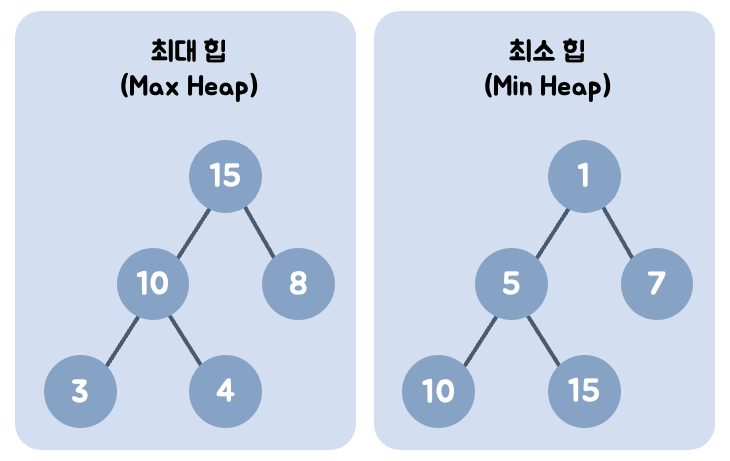
Heap
- 데이터에서 최댓값과 최솟값을 빠르게 찾기 위해 고안된 완전 이진 트리(Complete Binary Tree)
- 힙은 최대힙(Max heap)과 최소힙(Min heap)으로 나뉘어진다. 최대힙은 자식 노드보다 부모 노드의 값이 크고, 최소힙은 자식 노드보다 부모 노드의 값이 작다.
- 노드가 왼쪽부터 채워지는 완전 이진 트리 형태를 가진다.
- 중복을 허용한다.
heap vs 이진트리
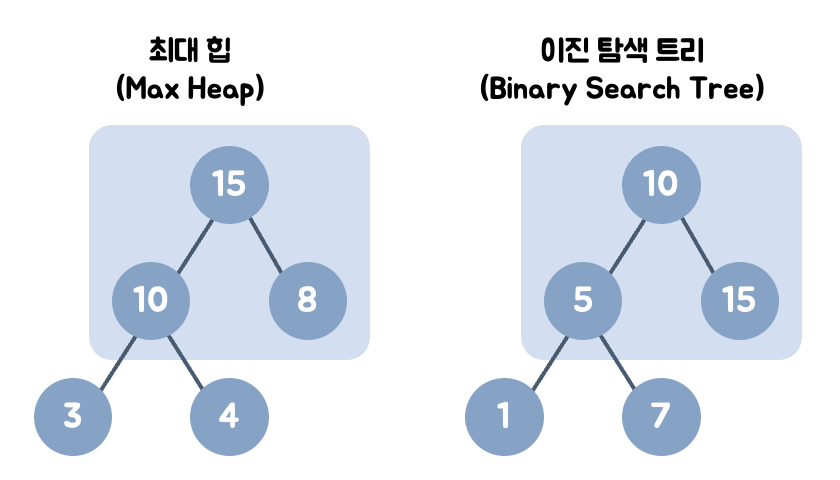
- (최대힙의 경우) 힙은 각 노드의 값이 자식 노드보다 크거나 같다.
- 이진 탐색 트리는 각 노드의 왼쪽 자식은 더 작은 값으로, 오른쪽 자식은 더 큰 값으로 이루어져있다.
- 왼쪽 자식 노드 < 부모 노드 < 오른쪽 자식 노드
- 힙은 왼쪽 노드의 값이 크든 오른쪽 노드의 값이 크든 상관 없다.
- 힙은 최대/최소 검색을, 이진 탐색 트리는 탐색을 위한 구조이다.
참조 :
https://velog.io/@gnwjd309/data-structure-heap
https://uni.rejoice-it.com/27 https://soliloquiess.github.io/study/2021/03/20/java_%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0.html
https://dinfree.com/lecture/language/112_java_6.html
https://bangu4.tistory.com/194
