모델 훈련 코드
from tqdm.notebook import tqdm
def training_model(model, data_loader, epochs):
since = time.time() # 총 소요 시간 계산을 위해시작 시간을 기록
best_model_wts = copy.deepcopy(model.state_dict()) # 모든 epoch에서 학습 된 모델 중 best model의 가중치를 저장하는 변수
best_acc = 0
for epoch in range(epochs):
avg_cost = 0
for phase in ['train', 'val']: # train mode와 validation mode 순서로 진행
if phase == 'train':
model.train() # model을 training mode로
else:
model.eval() # model을 validation mode로
for X, Y in tqdm(data_loader[phase]):
X, Y = X.to(device), Y.to(device)
optimizer.zero_grad() # 지난 iteration에서 계산했던 기울기 초기화
with torch.set_grad_enabled(phase == 'train'): # training mode에서는 gradient를 기억하여 가중치를 수정해야 함
# validation mode에서는 가중치를 수정하지 않으므로 필요 없음
hypothesis = model(X) # 순전파 과정으로 예측값 도출
cost = criterion(hypothesis, Y) # 예측값과 실제값을 비교한 loss
if phase == 'train':
cost.backward() # 역전파, 기울기 계산
optimizer.step() # optimizer로 가중치 갱신
avg_cost += cost / total_batch[phase]
else: # validation에서는 역전파로 가중치를 학습할 필요 없음
prediction = model(X) # 학습한 모델로 test 데이터의 예측값 도출(각 숫자에 해당할 확률)
prediction = prediction.to(device)
correct_prediction = torch.argmax(prediction, 1) == Y # 모든 확률 중에서 가장 큰 확률을 가진 숫자를 예측값으로 지정하고 이를 실제값과 비교
global accuracy
accuracy = correct_prediction.float().mean().item() # 정확도 계산
if phase == 'train':
print('[Epoch: {:>4}] train cost = {:.4f}'.format(epoch + 1, avg_cost)) # training 과정에서 각 epoch 마다의 cost 출력
else:
print('val Accuracy = {:.4f}', accuracy) # validation 과정에서 각 epoch에서 학습된 모델의 성능 출력
print('='*100)
if phase == 'val' and accuracy > best_acc: # 이번 epoch에서 만들어진 모델이 이전에 만들어진 모델보다 더 성능이 좋을 경우, best accuracy을 수정
best_acc = accuracy
best_model_wts = copy.deepcopy(model.state_dict())
training_time = time.time() - since # 학습 경과 시간
print('total training time for {} epochs: {:.0f}m {:.0f}s'.format(epochs, training_time//60, training_time%60))
print('Best val Accuracy: {:.4f}'.format(best_acc))
model.load_state_dict(best_model_wts)
return model # best model 반환-
Q. tqdm 이란?
tqdm 은 Progress Meter 또는 Progress Bar 를 만드는 데 사용되는 라이브러리입니다.

위와 같이 딥러닝에서는 훈련이 어느 정도 진행되었는 지를 시각적으로 한 눈에 볼 수 있습니다.
-
Q. copy.deepcopy 란?
copy 에는 그냥 copy와 deepcopy가 있습니다. (얕은 복사와 깊은 복사)
얕은 복사와 깊은 복사의 차이는 아래 코드를 보고 이해할 수 있습니다.
예를 들어, a라는 리스트를 만들고, 리스트에 새로운 element를 append했을 때, 얕은 복사는 영향을 주지만 깊은 복사는 영향을 주지 않습니다.
>>> import copy # 얕은 복사 >>> a = [[1,2], [3,4]] >>> b = copy.copy(a) >>> a[1].append(5) >>> a [[1, 2], [3, 4, 5]] >>> b [[1, 2], [3, 4, 5]] # 깊은 복사 >>> a = [[1,2],[3,4]] >>> b = copy.deepcopy(a) >>> a[1].append(5) >>> a [[1, 2], [3, 4, 5]] >>> b [[1, 2], [3, 4]] -
Q. Validation 이란?
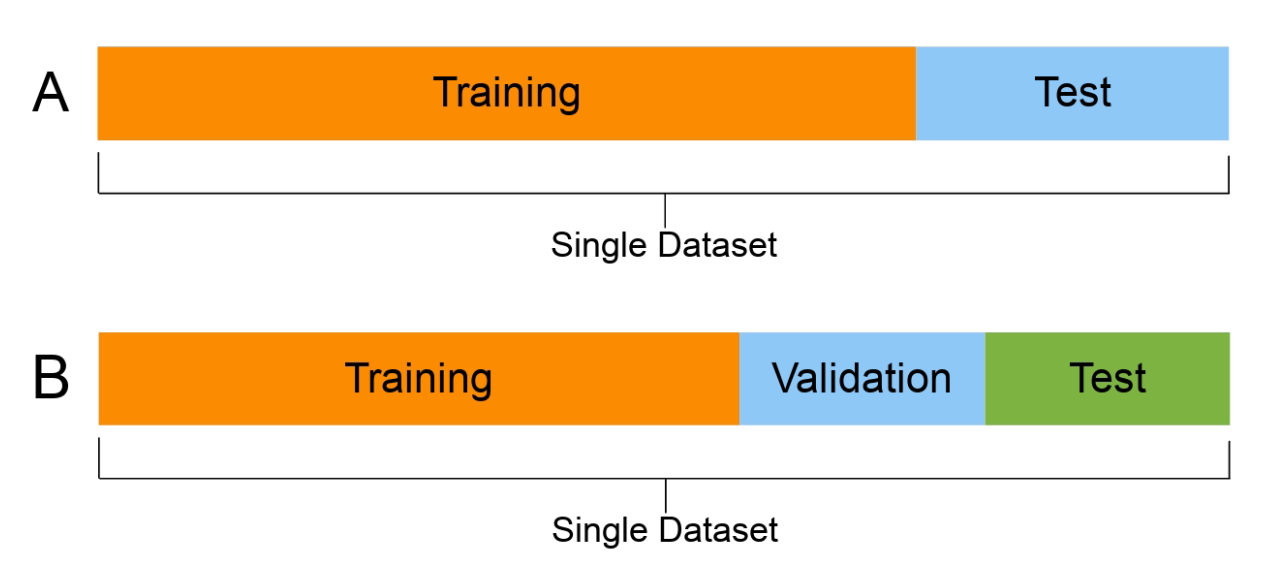
기계 학습에서 사용되는 데이터는 train , validation, test set 세 가지로 분류됩니다.
validation 은 train set과 test set 사이의 괴리를 보완하고, 학습을 시킨다기보다 학습한 내용을 말 그대로 검증하며, 모델 성능을 검증하는 기회를 제공합니다.
딱 한 번의 시험으로 평가 기회가 끝난다면, 새로이 업그레이드 된 상태를 시험해보고 싶을 때 더 이상 시험 문제가 없어서 확인할 수가 없겠죠. 이런 안타까운 상황을 막고자 Validation(검증) 세트가 존재합니다.
정리하면
훈련은 순수 학습을 위해,
검증은 학습 내용을 검토하고 성능을 체크해보기 위해,
테스트는 개발-검증을 거친 모델의 최종 능력을 시험해보기 위해 존재합니다.
b. Data Augmentation
# Data Augmentation
transform = transforms.Compose([
transforms.Resize(256),
transforms.RandomCrop(227),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) #3채널(R,G,B) 데이터의 평균과 분산을 0.5로 설정
])c. 데이터셋 분류
# CIFAR-10 dataset을 사용했습니다.
batch_size = 64
cifar_train = datasets.CIFAR10('~/.data', download=True, train=True, transform=transform)
train_loader = torch.utils.data.DataLoader(cifar_train, batch_size=batch_size, shuffle=True) #batch_size는 원하는 크기로 변경 가능.
#단, 2의 제곱수로 하고 test_loader의 batch_size도 동일한 수로 변경할 것.
cifar_test = datasets.CIFAR10('~/.data', download=True, train=False, transform=transform)
test_loader = torch.utils.data.DataLoader(cifar_test, batch_size=batch_size, shuffle=True)
data_loaders = {'train' : train_loader, 'val': test_loader}
total_batch = {'train' : len(train_loader), 'val': len(test_loader)}
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 클래스 총 10개 지정
from torchvision import utils
import matplotlib.pyplot as plt
import numpy as np
dataiter = iter(train_loader) # iter함수로 iteration 객체 가져오기
images, labels = next(dataiter)모델 구조 및 코드 구현
a-1. AlexNet
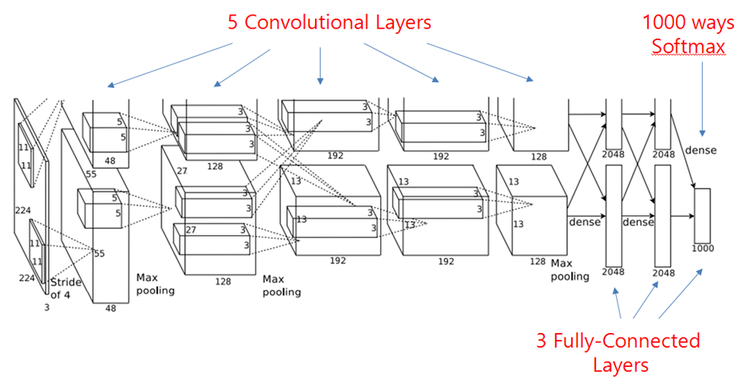
class AlexNet(nn.Module):
def __init__(self, input_size = 227, num_classes = 10): # data augmentation 과정에서 이미지 크기를 227로 crop했으므로, input_size = 227
# CIFAR-10 데이터는 총 10개의 종류로 분류되므로, num_classes = 10
super(AlexNet, self).__init__()
# CNN Layer
self.CNNLayer = nn.Sequential(
# 1st Conv layer
# Q1. 바로 하단의 layer후에 size가 227->55가 되도록 kernel_size 설정
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, padding = 0, stride=4),
# Q2. 아래의 활성화 함수(####) 채워 넣기 (모든 layer에 대해)
# Q3. pooling 방식(함수) 채워 넣기 (모든 layer에 대해)
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2), # LRN
nn.MaxPool2d(kernel_size=3, stride=2), # overlap pooling, 55->27
# 2nd Conv layer
nn.Conv2d(96, 256, 5, padding = 2, stride = 1), # 27->27
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2), # 27->13
# 3rd Conv layer
nn.Conv2d(256, 384, 3, padding = 1, stride = 1), # 13->13
nn.ReLU(inplace=True),
# 4th Conv layer
nn.Conv2d(384, 384, 3, padding = 1, stride = 1), # 13->13
nn.ReLU(inplace=True),
# 5th Conv layer
nn.Conv2d(384, 256, 3, padding=1, stride = 1), # 13->13
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # 13->6
)
# Fully-connected Layer
self.FCLayer = nn.Sequential(
# 1st FC layer
nn.Linear(in_features=(256 * 6 * 6), out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
# 2nd FC layer
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
# 3nd FC layer & classifier
nn.Linear(in_features=4096, out_features=num_classes),
)
self.init_bias() # bias 초기화
def init_bias(self):
for layer in self.CNNLayer:
if isinstance(layer, nn.Conv2d):
# weight와 bias 초기화
nn.init.normal_(layer.weight, mean=0, std=0.01)
nn.init.constant_(layer.bias, 0)
# 논문에 2,4,5 conv2d layer의 bias는 1로 초기화한다고 나와있습니다.
nn.init.constant_(self.CNNLayer[4].bias, 1)
nn.init.constant_(self.CNNLayer[10].bias, 1)
nn.init.constant_(self.CNNLayer[12].bias, 1)
def forward(self, x):
output = self.CNNLayer(x)
output = output.view(-1, 256 * 6 * 6)
output = self.FCLayer(output)
return output파이토치에 내장된 모델로 손쉽게 구현하는 방법도 있습니다.
a-2. AlexNet using Torch
import torchvision.models as models
alexnet = models.alexnet(pretrained=True)
num_ftrs = alexnet.classifier[6].in_features
alexnet.classifier[6] = nn.Linear(num_ftrs, 10) # pretrained된 모델의 마지막 레이어 노드 개수는
# 우리가 사용하는 데이터의 num_classes와 다르므로 바꿔줘야 한다.
print(alexnet.classifier[6])
alexnet.to(device)b-1. VGG-11
VGG는 layer들을 블록화해서 레고 쌓듯 층을 쌓은 모델입니다.
이전 CNN 모델보다 훨씬 더 많은 레이어를 사용하여 깊게 만든 신경망으로,
깊이를 증가시켜 정확도를 높이면서 필터 크기를 조정해 파라미터 수가 크게 늘어나지 않도록 했습니다.
모델명 뒤에 붙는 숫자는 layer 수를 의미합니다.
VGG-11 은 convolution layer 8개와 Fully Connected layer 3개로 이루어져 있습니다.
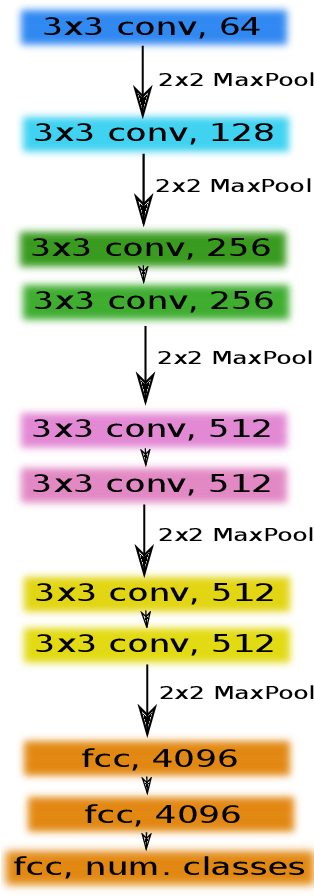
def vgg_11(conv_arch):
conv_blks = []
in_channels = 3
# The convolutional part
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
# The fully-connected part
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10))
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
vgg_11 = vgg_11(conv_arch)
vgg_11.to(device)b-2. VGG-16
# 첫 번째 블록 (합성곱 층이 두 개)
def conv_2_block(in_features, out_features):
net = nn.Sequential(
nn.Conv2d(in_features, out_features, kernel_size = 3, padding = 1),
nn.ReLU(),
nn.Conv2d(out_features, out_features, kernel_size = 3, padding = 1),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
return net
# 두 번째 블록 (합성곱 층이 3개)
def conv_3_block(in_features, out_features):
net = nn.Sequential(
nn.Conv2d(in_features, out_features, kernel_size = 3, padding = 1),
nn.ReLU(),
nn.Conv2d(out_features, out_features, kernel_size = 3, padding = 1),
nn.ReLU(),
nn.Conv2d(out_features, out_features, kernel_size = 3, padding = 1),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
return net
# 직접 합성 곱 층 개수를 지정할 수 있는 블록 함수
def vgg_block(num_convs,in_channels,out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels, kernel_size = 3, padding = 1))
layers.append(nn.ReLU(inplace = True))
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size = 2, stride = 2))
return nn.Sequential(*layers)
# VGG-16
class VGGNet(nn.Module):
def __init__(self, input_size = 227, num_classes=10):
super(VGGNet, self).__init__()
self.CNNLayer = nn.Sequential(
conv_2_block(3, 64), # 3->64
conv_2_block(64, 128), # 64->128
conv_3_block(128, 256), # 128->256
conv_3_block(256, 512), # 256->512
conv_3_block(512, 512), # 512->512
)
#self.avgpool = nn.AdaptiveAvgPool2d(7)
self.FCLayer = nn.Sequential(
nn.Linear(512*4*4, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 1000),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(1000, num_classes),
)
def forward(self, x):
output = self.CNNLayer(x)
#output = self.avgpool(output)
output = output.view(-1, output.size(0))
output = self.FCLayer(output)
return outputb-3. VGG-16 using Torch
import torchvision.models as models
vgg16 = models.vgg16(pretrained=True)
num_ftrs = vgg16.classifier[6].in_features
vgg16.classifier[6] = nn.Linear(num_ftrs, 10)
vgg16.to(device)c-1. GooglNet
GoogleNet은 Inception module 이란 것을 사용해 신경망 내에 또다른 신경망을 넣음으로써 구조가 분산되는 것을 막아 계산의 효율성을 높인 모델입니다.
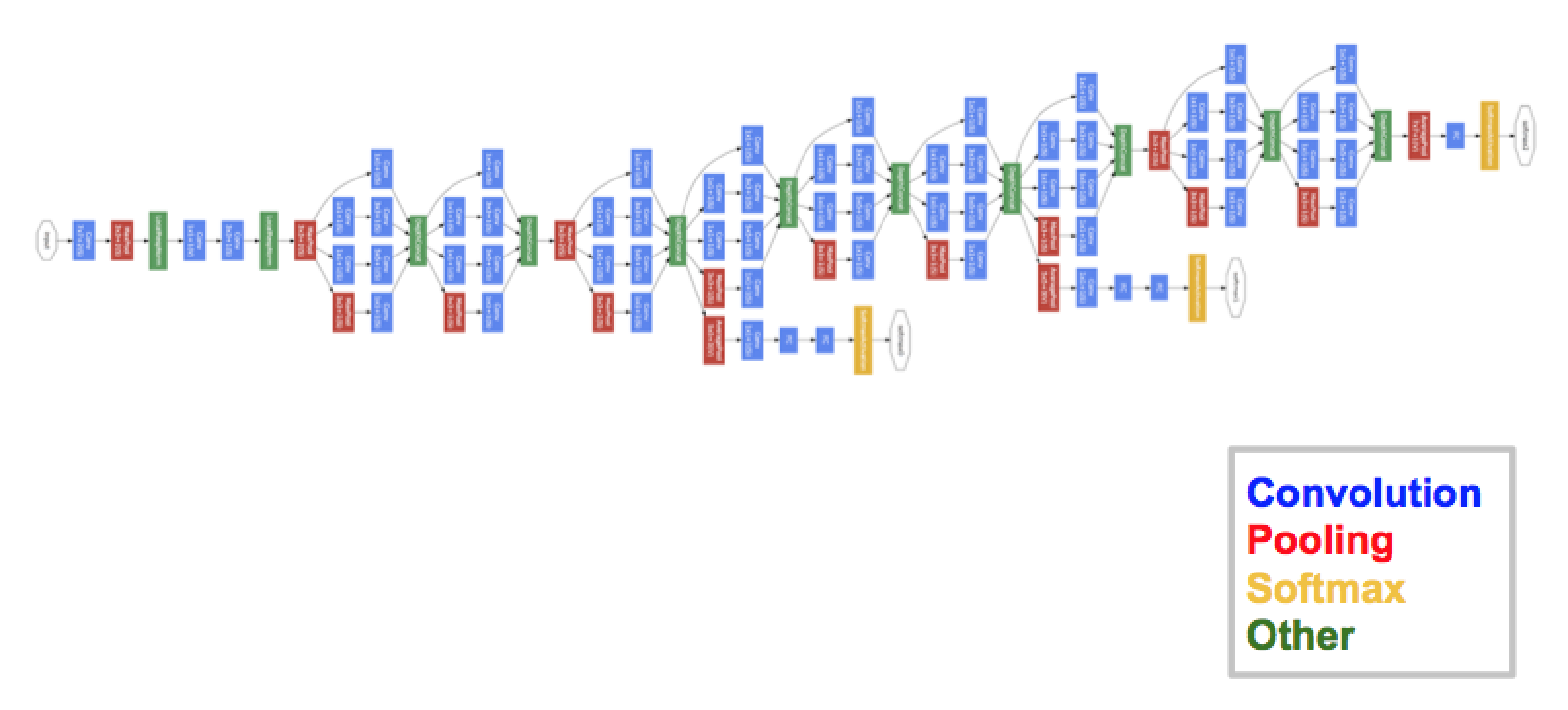
# 1x1 conv net
def conv_1(in_features,out_features):
net = nn.Sequential(
nn.Conv2d(in_features, out_features, 1, 1),
nn.ReLU(),
)
return net
# 1x1, 3x3 conv net
def conv_1_3(in_features, mid_features, out_features):
net = nn.Sequential(
nn.Conv2d(in_features, mid_features, 1, 1),
nn.ReLU(),
nn.Conv2d(mid_features, out_features, 3, 1, 1),
nn.ReLU()
)
return net
# 1x1, 5x5 conv net
def conv_1_3(in_features, mid_features, out_features):
net = nn.Sequential(
nn.Conv2d(in_features, mid_features, 1, 1),
nn.ReLU(),
nn.Conv2d(mid_features, out_features, 3, 1, 1),
nn.ReLU()
)
return net
# maxpooling net
def max_3_1(in_features, out_features):
net = nn.Sequential(
nn.MaxPool2d(kernel_size = 3, stride = 1, padding = 1),
nn.Conv2d(in_features, out_features, 1, 1),
nn.ReLU(),
)
return net
# Inception Module
class inception_module(nn.Module):
def __init__(self, in_features, out_features_1, mid_features_3, out_features_3,
mid_features_5, out_features_5, pool_features):
super(inception_module, self).__init__()
# 1x1 -> 1x1
self.conv_1 = conv_1(in_features, out_features_1)
# 1x1 -> 3x3
self.conv_1_3 = conv_1_3(in_features, mid_features_3, out_features_3)
# 1x1 -> 5x5
self.conv_1_5 = conv_1_5(in_features, mid_features_5, out_features_5)
# 3x3 -> 1x1
self.max_3_1 = max_3_1(in_features, pool_features)
def forward(self,x):
output_1 = self.conv_1(x)
output_2 = self.conv_1_3(x)
output_3 = self.conv_1_5(x)
output_4 = self.max_3_1(x)
output = torch.cat([output_1, output_2, output_3, output_4], 1) # 모든 output 이어붙이기
return output
# GoogleNet
class GoogLeNet(nn.Module):
def __init__(self, base_features, num_classes = 10):
super(GoogLeNet, self).__init__()
self.num_classes = num_classes
self.layer_1 = nn.Sequential(
nn.Conv2d(3, 64, 7, 2, 3),
nn.MaxPool2d(3, 2, 1),
nn.Conv2d(64, 192, 3, 1, 1),
nn.MaxPool2d(3, 2, 1),
)
self.layer_2 = nn.Sequential(
inception_module(192, 64, 96, 128, 16, 32, 32),
inception_module(256, 128, 128, 192, 32, 96, 64),
nn.MaxPool2d(3, 2, 1),
)
self.layer_3 = nn.Sequential(
inception_module(480, 192, 96, 208, 16, 48, 64),
inception_module(512, 160, 112, 224, 24, 64, 64),
inception_module(512, 128, 128, 256, 24, 64, 64),
inception_module(512, 112, 144, 288, 32, 64, 64),
inception_module(528, 256, 160, 320, 32, 128, 128),
nn.MaxPool2d(3, 2, 1),
)
self.layer_4 = nn.Sequential(
inception_module(832, 256, 160, 320, 32, 128, 128),
inception_module(832, 384, 192, 384, 48, 128, 128),
nn.AvgPool2d(7, 1),
)
self.layer_5 = nn.Dropout2d(0.4)
self.FCLayer = nn.Linear(1024, self.num_classes)
def forward(self, x):
output = self.layer_1(x)
output = self.layer_2(output)
output = self.layer_3(output)
output = self.layer_4(output)
output = self.layer_5(output)
output = output.view(batch_size, -1)
output = self.FCLayer(output)
return outputc-2. GoogleNet using Torch
import torchvision.models as models
googlenet = models.googlenet(pretrained=True)
num_ftrs = googlenet.fc.in_features
googlenet.fc = nn.Linear(num_ftrs, 10)
googlenet.to(device)d-1. ResNet
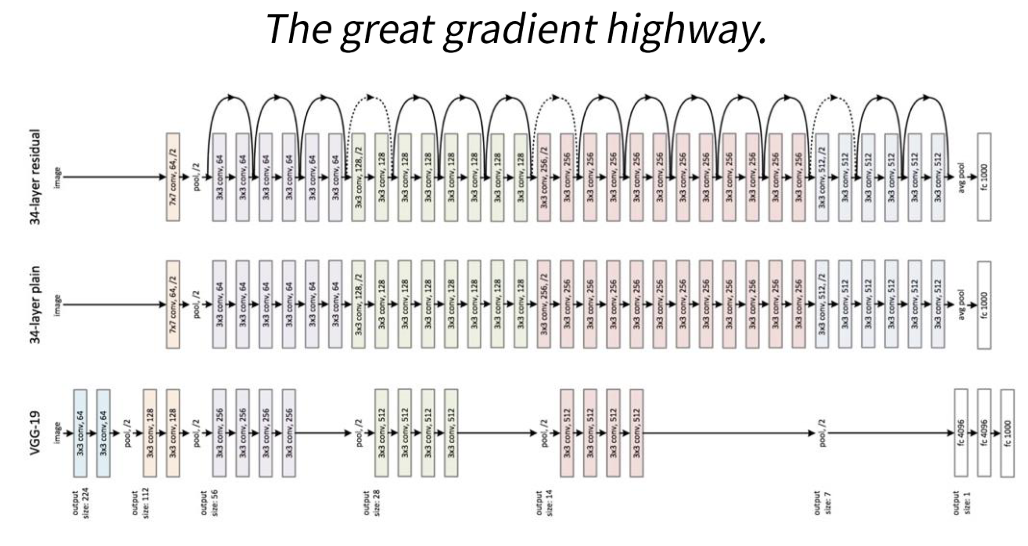
ResNet은 딥러닝 모델에서 층이 깊어질수록 발생하는 기울기 소실, 폭주 문제를 해결하기 위해 Residual block을 사용한 신경망입니다.

# 1x1 conv block
def conv_block_1(in_features, out_features, stride=1):
net = nn.Sequential(
nn.Conv2d(in_features, out_features, kernel_size=1, stride = stride),
nn.BatchNorm2d(out_features),
nn.ReLU(),
)
return net
# 3x3 conv block
def conv_block_3(in_features, out_features, stride=1):
net = nn.Sequential(
nn.Conv2d(in_features, out_features, kernel_size = 3, stride = stride, padding = 1),
nn.BatchNorm2d(out_features),
nn.ReLU(),
)
return net
# BottleNeck
class BottleNeck(nn.Module):
def __init__(self, in_features, mid_features, out_features, down=False):
super(BottleNeck, self).__init__()
self.down=down
# feature map 크기가 감소하는 경우
if self.down:
self.layer = nn.Sequential(
conv_block_1(in_features, mid_features, stride=2),
conv_block_3(mid_features, mid_features, stride=1),
conv_block_1(mid_features, out_features, stride=1),
)
self.downsample = nn.Conv2d(in_features, out_features, kernel_size=1, stride=2)
# feature map의 크기가 유지되는 경우
else:
self.layer = nn.Sequential(
conv_block_1(in_features, mid_features, stride=1),
conv_block_3(mid_features, mid_features, stride=1),
conv_block_1(mid_features, out_features, stride=1),
)
self.dim_equalizer = nn.Conv2d(in_features, out_features, kernel_size=1)
def forward(self, x):
if self.down:
downsample = self.downsample(x)
output = self.layer(x)
output = output + downsample
else:
output = self.layer(x)
if x.size() is not output.size():
x = self.dim_equalizer(x)
output = output + x
return output
'''
'''
# ResNet
class ResNet(nn.Module):
def __init__(self, num_classes=10):
super(ResNet, self).__init__()
# Q6. 빈칸 채워넣기
self.layer_1 = nn.Sequential(
nn.Conv2d(3,64,kernel_size = 7, stride = 2, padding=3),
nn.ReLU(),
nn.MaxPool2d(3,2,1),
)
self.layer_2 = nn.Sequential(
BottleNeck(64,64,256),
BottleNeck(256,64,256),
BottleNeck(256,64,256,down=True),
)
self.layer_3 = nn.Sequential(
BottleNeck(256,128,512),
BottleNeck(512,128,512),
BottleNeck(512,128,512),
BottleNeck(512,128,512,down=True),
)
self.layer_4 = nn.Sequential(
BottleNeck(512,256,1024),
BottleNeck(1024,256,1024),
BottleNeck(1024,256,1024),
BottleNeck(1024,256,1024),
BottleNeck(1024,256,1024),
BottleNeck(1024,256,1024,down=True),
)
self.layer_5 = nn.Sequential(
BottleNeck(1024,512,2048),
BottleNeck(2048,512,2048),
BottleNeck(2048,512,2048),
)
self.avgpool = nn.AvgPool2d(1,1)
self.fc_layer = nn.Linear(2048,num_classes)
def forward(self, x):
output = self.layer_1(x)
output = self.layer_2(output)
output = self.layer_3(output)
output = self.layer_4(output)
output = self.layer_5(output)
output = self.avgpool(output)
output = output.view(batch_size,-1)
output = self.fc_layer(output)
return outputd-2. ResNet using Torch
import torchvision.models as models
resnet = models.resnet50(pretrained=True)
num_ftrs = resnet.fc.in_features
resnet.fc = nn.Linear(num_ftrs, 10)
resnet.to(device)+) cuda out of memory 에러 해결 방법
여러번 코드를 돌리다보면 cuda의 메모리가 떨어졌다는 오류메시지가 나올 수 있습니다.
찾아보니 여러 해결방법이 있지만 저는 캐시 삭제, 가비지 컬렉터를 수동으로 실행하는 방법을 사용해봤습니다.
import gc
gc.collect()
torch.cuda.empty_cache()