파티셔너란?
카프카 프로듀서의 중요 개념 중 하나로, 파티션을 좀 더 효과적으로 쓸 수 있다.
파티셔너의 역할
프로듀서가 데이터를 보내면 무조건 파티셔너를 통해서 브로커로 데이터가 전송된다.
어떤 파니션에 넣을지 결정하는 역할
- 레코드에 포함된 메시지 키 / 메시지 값으로 위치를 결정한다.
-
키를 가진 레코드는 파티셔너에 의해 특정한 해쉬값이 생성되는데
이 값을 기준으로 어느 파티션에 들어갈지 결정된다. -
동일한 메시지 키를 가진애들은 순서를 지켜서 데이터를 처리할 수 있다는 장점이 있다. (파티션 내부는 큐처럼 동작하니까 가능)
ex) key = '서울' / key = '부산'
서울키는 무조건 파티션 0번으로 부산키는 무조건 파티션 1번으로 설정 -
메시지 키가 없으면 라운드 로빈으로 들어간다.
메시지 키가 없는 레코드들은 적절히 파티션으로 나뉘어 보내진다.
파티셔너 설정
-
파티셔너를 따로 설정 안 하면 uniformStickyPartitioner로 설정된다.
-
커스텀 파티셔너
커스텀 파티셔너를 만들 수 있도록 파티셔너 인터페이스 제공
커스텀 파티셔너 클래스를 만들면 메시지 키, 값, 토픽이름으로 어느 파티션으로 보낼지 정할 수 있다.
ex) vip 고객을 위해 데이터 처리를 더 빨리하기 위한 로직을 위해 파티셔너 설정
10개의 파티션이 있다면 8개에는 vip 꺼 2개에는 일반 고객꺼로 하면 amqp기반 메시징 시템에서 우선순위 큐를 만드는 것과 비슷하다.
카프카 토픽
데이터가 들어갈 수 있는 공간을 토픽이라고 한다.
카프카에서는 토픽을 여러개 생성 할 수 있다.
데이터베이스의 테이블이나 파일 시스템의 폴더와 유사한 성질
이 토픽에 프로듀서가 데이터를 넣고 컨슈머가 여기서 가져간다.
하나의 토픽은 여러개의 파티션으로 구성될 수 있다.
하나의 파티션은 큐와 같이 데이터가 차곡차곡 쌓이게 된다. 컨슈머는 가장 오래된 순서대로 가져가게 된다. 이때 컨슈머가 데이터를 가져가도 파티션에서 삭제되지 않는다.
- 다른 컨슈머가 데이터를 가지고 갈 수 있을 때 : auto.offset.reset=earliest
동일 데이터를 두번 사용할 수 있다.
카프카 lag = 모니터링 지표중 하나다!
- lag은 프로듀서와 컨슈머의 offset 차이이다.
- lag은 여러개가 존재할 수 있다.
여기서 offset이란?
파티션에 데이터가 하나씩 들어가게 되면 각 데이터는 오프셋이라는 숫자가 붙는다.
파티션이 1개인 토픽에 프로듀서가 데이터를 넣을때 0부터 차례대로 숫자가 붙는다.
프로듀서가 데이터를 넣어주는 속도가 컨슈머가 가져가는 속도보다 빠르면?
=> kafka consumer lag 발생
-
컨슈머가 마지막으로 읽은 offset - 프로듀서가 마지막으로 넣은 offset
이 두 offset간의 차이를 kafka consumer lag 이라고 한다.
프로듀서와 컨슈머의 상태에 대해 유추 가능한데 주로 컨슈머 상태를본다. -
lag은 여러개가 존재할 수 있다.
토픽에 여러 파티션이 존재할 경우 lag은 여러개 존재가능
컨슈머그룹 1개 파티션 2개인 토픽에서 데이터를 가져간다면 lag은 2개 발생 가능
한개의 토픽과 컨슈머 그룹에 대한 lag이 여러개 존재할 때, 그 중 높은 숫자의 lag을 records-lag-max라고 부른다.
컨슈머가 성능이 안나오고 비정상 동작을 하면 주로 lag에 대해 필연적으로 발생하기 때문에 주의 깊게 살펴볼 니즈가 많다.
카프카 lag을 모니터링 하기 위한 오픈소스 Burrow
배경
- lag을 컨슈머 단위에서 모니터링 하면 컨슈머 상태에 디펜던시가 걸리기 때문에 아주 위험하고 운영요소가 많이 든다.
- 컨슈머가 비정상적으로 종료되게 된다면 더이상 컨슈머는 lag정보를 보낼 수 없기 때문에 더이상 lag 측정 불가 문제가 발생한다.
- 추가적으로 컨슈머가 개발 될 때마다 해당 컨슈머에 lag정보를 특정 저장소에 저장할 수 있도록 로직을 개발해야한다.
=> 그래서 linkein에서는 카프카 컨슈머 lag을 효고적으로 모니터링하라고 만든 게 burrow
burrow = 컨슈머 lag 모니터링을 도와주는 독립적인 애플리케이션
3가지 특징
-
멀티 카프카 클러스터 지원
: 대부분이 2개 이상의 카프카 클러스터를 운영할 텐데 이런 경우에도 burrow한개만 실행해서 연동한다면 모두 모니터링할 수 있다. -
Sliding window를 통한 Consumer의 status 확인
에러 , 워닝, 오케이로 표현할 수 있도록 했다.
만약 컨슈머 오프셋이 증가되고 있으면 워닝
컨슈머가 데이터를 가져가지 않으면 에러
status를 기반으로 효과적인 운영 가능 -
http api 제공
이걸로 조회할 수 있게 했다.
버로우는 다양한 추가 생태계 구축 가능
현재 많은 데이터 기반 기업에서 사용하고 있다~
물론 이거 도입한다고 무든 문제가 해결되는 것은 아니다.
카프카 관련 애플리케이션에 도움이 많이 될 것이다.
메시징 플랫폼
-
메시지 브로커
: 이벤트 브로커로 역할을 할 수 없다.많은 기업들의 대규모 메시지 기반 미들웨어 아키텍처에서 사용되고 있다.
미들웨어란 보다 효율적으로 아키텍쳐를 연결하는 소프트웨어를 말한다.
ex ) 메시징 플랫폼, 인증 플랫폼, 데이터 플랫폼메시지 브로커의 특징
메시지를 받아서 적절히 처리하고 나면 즉시 또는 짧은 시간내에 삭제되는 구조
메시지 브로커는 데이터를 보내고 처리하고 삭제한다.반면에 이벤트 브로커는 이벤트 브로커는 삭제하지 않는다
-
이벤트 브로커
: 메시지 브로커로 역할을 할 수 있다.
-
이벤트 또는 메시지라고도 불리느 이 레코드를 이 장부를 하나만 보관하고 인덱스를 통해 개별 엑세스를 관리한다.
-
업무상 필요한 시간동안 보관 가능하다.
이벤트 브로커는 서비스에서 나오는 이벤트를 db에 저장하듯이 큐에 저장하는데
이렇게 저장해서 얻는 이점
-
딱 한번 일어난 이벤트를 브로커에 저장함으로서 단일 진실 공급원으로 사용가능
-
장애가 발생했을 때 장애가 일어난 시점부터 재처리 가능
-
많은 양의 실시간 스트림 데이터를 효과적으로 처리할 수 있다는 특징이 있다.
메시지 브로커는 레디스 큐
이벤트 브로커는 aws 키네시스 / 카프카이벤트 브로커로 클러스터를 구축하면 이벤트 기반 마이크로 서비스 아키텍처로 발전하는데 중요한 역할뿐만 아니라 메시지 브로커로서도 사용하니까 팔방미인이다.
AWS에 카프카 클러스터 설치, 실행하기
카프카의 고가용성의 핵심은 3개 이상의 카프카 브로커로 이루어진 클러스터에서 진가를 발휘한다.
EC2 3대
- 2가지의 애플리케이션 설치!
주키퍼 : 카프카 관련 정보 저장하는 역할
카프카
주키퍼 설정 :
https://blog.voidmainvoid.net/325
방화벽 설정 등등.. 위의 블로그 보세요..
넘 길어!!!
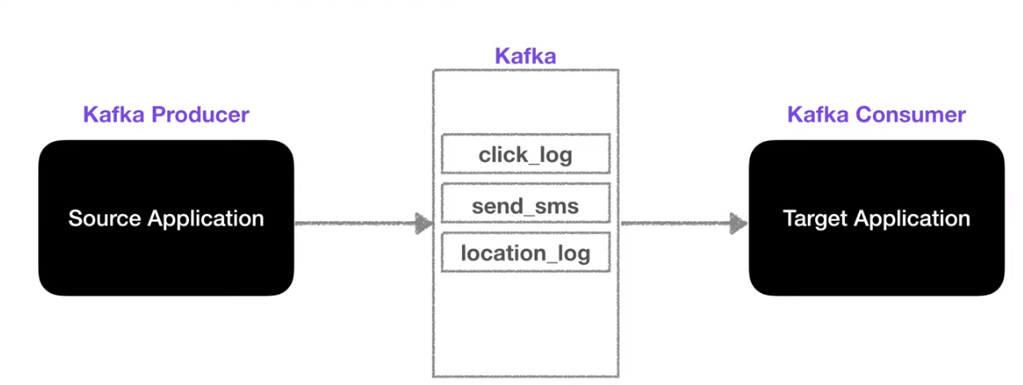
카프카 프로듀서 애플리케이션
프로듀서는 카프카에 데이터를 보내는 역할
데이터를 프로듀싱 즉 생산하는 역할
데이터를 카프카 토픽에 생산한다는 말!
- topic에 전송할 메시지를 생성
- 특정 topic으로 데이터를 publish 가능
- 전송 성공여부를 알 수 있다. 실패의 경우 재시도 가능.
아파치 카프카 라이브러리를 추가해야한다.
그래들이나 메이븐같은 도구를 사용해 편리하게 가져올 수 있다.
주의!! 버전주의하세요
카프카는 브로커버전과 클라이언트 버전의 하위 호환성이 좋지 않다.
일부 카프카 브로커 버전은 특정 클라이언트 버전을 지원하지 않을 수도 있다.
그러므로 하위 호환성에 대해 숙지하고 알맞는 버전 사용하세요~!
카프카 프로듀서 코드
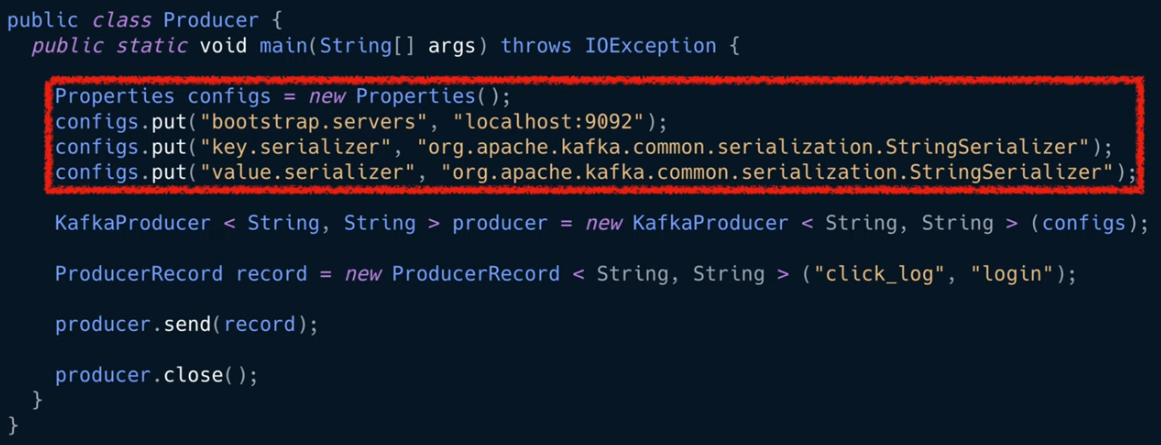
프로듀서를 위한 설정
자바 프로퍼티 객체를 통해 설정을 정의하는데,
- 부트스트랩 서버 설정을 로컬 호스트의 카프카를 바라보도록 설정
카프카 브로커의 주소 목록은 2개이상의 ip와 port를 설정하도록 권장
(둘중 한개가 비정상일 경우 다른 정상적인 브로커에 연결되어 사용가능하기 때문)
그러므로 실제로 연결할 때는 반드시 2개이상의 브로커 정보를 넣는 것을 추천 - 키와 벨류에 대해 스트링시리얼라이저로 직렬화 설정
= 시리얼 라이저는 키 혹은 value를 직렬화하기 위해 byte array, string, integer 시리얼라이즈를 사용할 수 있다.
?여기서 key란?
키는 메시지를 보내면 토픽의 파티션이 지정될 때 쓰인다.
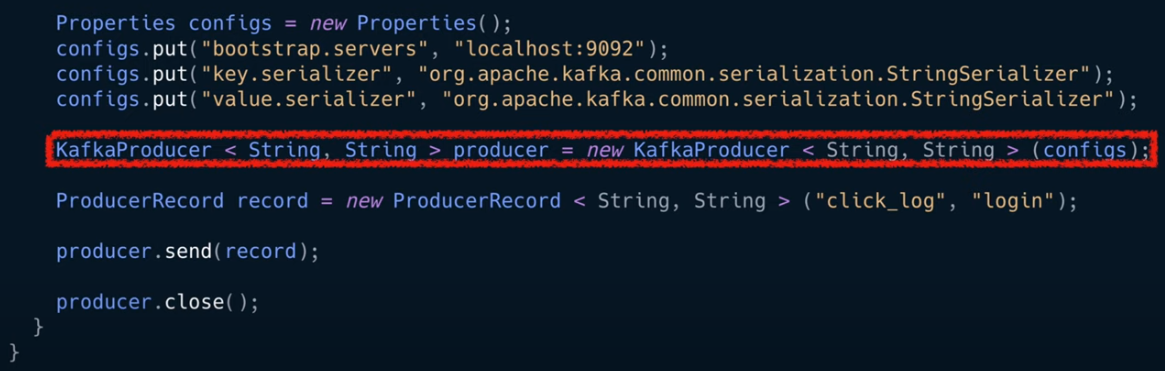
설정한 프로퍼티로 카프카 프로듀서의 인스턴스를 만든 코드
전송할 객체를 만들어야 하는데 카프카 클라이언트에서는 producer record 클래스 제공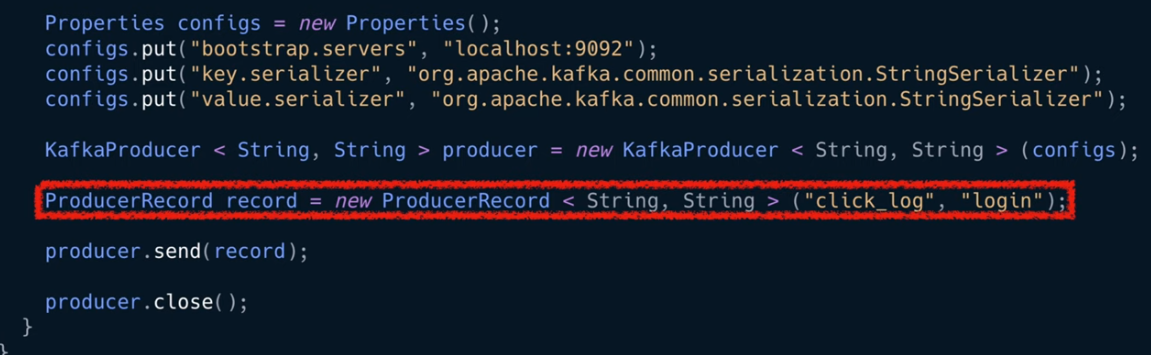
프로듀서 레코드 인스턴스를 생설할때 어떤 토픽에 넣을지 어떤 키나 밸류를 넣을지 선언할 수 있다. 클릭로그 토픽에 login이라는 밸류를 보낸다.

키를 넣고 싶다면 위의 코드로 작성하면 된다.
파라미터 개수에 따라 자동으로 오버로딩되어 인스턴스가 생성되므로 이점 유의!
이전에 생성된 프로듀서 인스턴스에 send()메서드로 전송이뤄진다.
전송 완료되면 close()로 프로듀서 종료

키가 있는 경우 위처럼 들어가는데!
이때, 만약 중간에 파티션을 추가하면 아래그림처럼 질서 와장창이므로
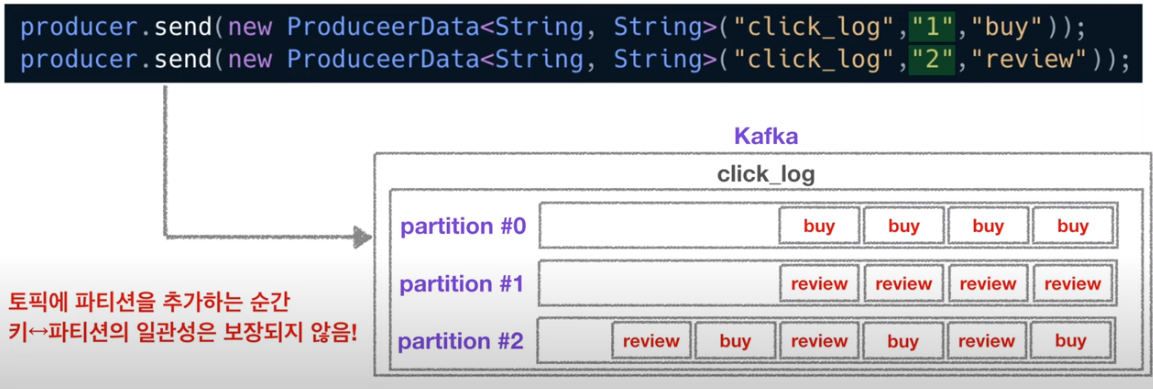
키와 파티션의 매칭이 깨지므로 key와 파티션의 연결이 보장되지 않는다.
그러므로 key를 사용할 경우 파티션 생성유의해서 추후 생성하지 않아야 한다.
데이터 유실 혹은 브로커의 이슈에 대처하기 위해서는 추가 옵션들과 코드가 필요하다.
카프카 컨슈머 애플리케이션
컨슈머가 데이터를 가져가도 데이터가 사라지지 않는 카프카!
데이터 파이프라인으로 운영하는데 핵심적인 부분!
기본적으로 토픽의 데이터를 가져오는 컨슈머!
데이터는 토픽 내부의 파티션에 저장된 데이터를 가져오는데 이것을 polling이라고 한다.
역할
1. topic의 partition으로 부터 데이터 polling
2. partition offset 위치 기록(commit)
3. Consumer group을 통해 병렬처리=더욱 빠른 속도록 데이터 처리 가능
gradle maven 사용하면 추가 쉽다~!
카프카 브로커와 클라이언트의 버전 호환성 역시 주의
- 먼저 자바 프로퍼티 설정
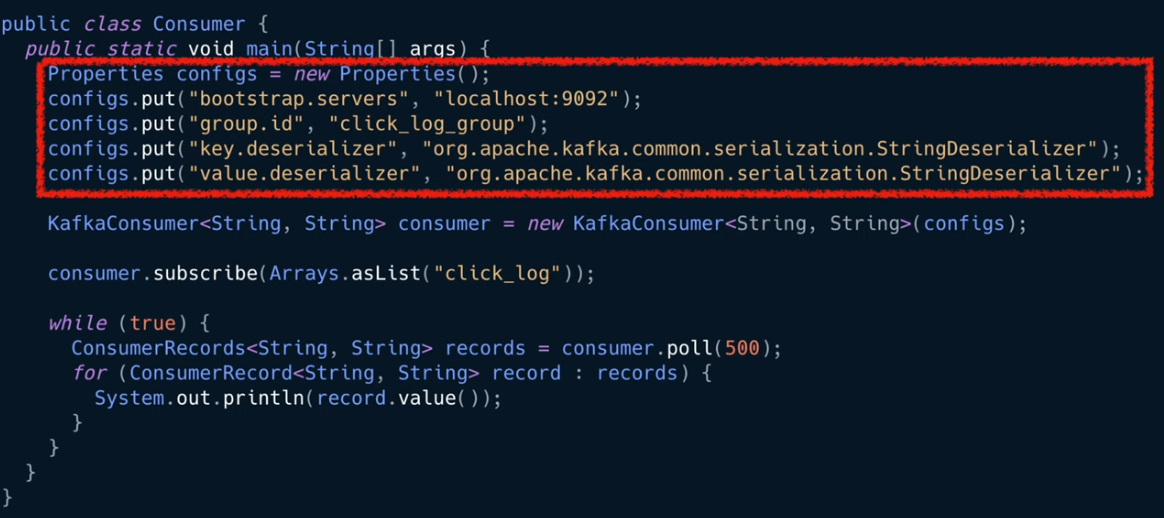
여러개의 브로커 설정!
그리고 그룹아이디 설정 = 컨슈머 그룹 - 컨슈머들의 묶음
그리고 이전에 프로듀서에 설정한것과 같이 key와 value에 대한 직렬화 설정

이것을 통해 데이터를 읽고 처리할 수 있다.

어느 토픽을 대상으로 ㄹ가져올지 설정
일부 파티션의 데이터만 가져오고 싶다면 아래처럼

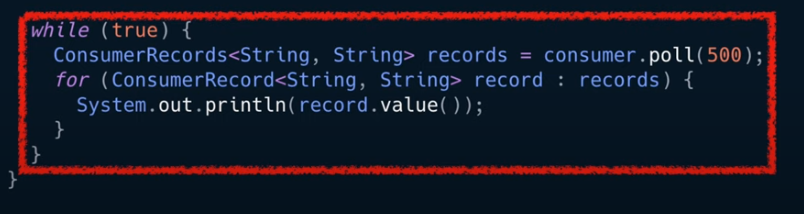
컨슈머가 허락하는 한 많은 데이터를 읽는것
컬링 루프는 컨슈머 api의 핵심 로직이다.
컨슈머는 poll()메서드를 통해 데이터를 가져온다.
설정한 500ms동안 데이터가 오기를 기다리고 아래를 실행한다.
records변수는 데이터 배치로서 레코드의 묶음 list이다.
records 변수를 for 루프에서 실질적으로 처리하는 데이터를 가져오게 하는 것
for구문 내부에서 value()메서드로 반환한 값이 프로듀서가 전송한 값이라고 보면 된다.
실제 기업에서는 데이터를 하둡 혹은 엘라스틱서치와 같은 곳에 저장하는 로직을 써놓는다.

offset은 컨슈머가 데이터를 어느 위치까지 읽었는지 확인하는 용도로 사용된다.
컨슈머가 데이터를 읽기시작하면 offset을 commit하는데 이 정보는 카프카의
_consumer_offset 토픽에 저장된다.
만약 컨슈머가 불의의 사고로 실행 중지되면 이 컨슈머는 파티션 0의 3번까지만 읽고 1번의 2번까지만 읽었다면 이게 저장되어 있으니 이 컨슈머를 재실행하면 중지된 시점을 알고 있으므로 다시 복구해 처리 가능하다.
이것이 고가용성의 특징을 가진다는 것.
컨슈머의 갯수는 파티션의 갯수보다 적거나 같아야 한다.
컨슈머 그룹이 다른 컨슈머들의 동작
각기 다르 컨슈머들은 다른 그룹에 영향을 미치지 않는다.
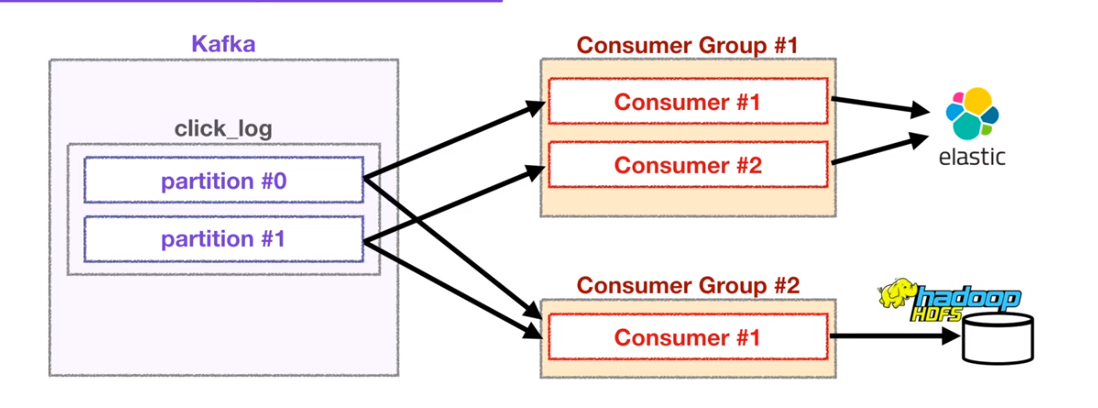
왜냐하면 컨슈머 그룹별로 토픽별로 offset을 나누어 저장하기 때문에 영향을 미치지 않는다.
카프카 스트림즈 애플리케이션
실시간으로 끊임없이 발생하는 데이터를 처리할때 수많은 오픈 소스 데이터 플랫폼중에 효과적인 카프카 스트림즈~!!
컨슈머를 사용해서 데이터를 처리하는 것 보다 더 안전하고 다양한 기능을 사용할 수 있는 카프카 스트림즈는 자바라이브러리로 토픽에 있는 데이터들을 낮은 지연으로 빠른속도록 처리가능하다
자바나 jvm기반 언어중에 하나 선택해서 라이브러리 같이 써도된다.
순수 자바 애플리케이션에 동작하게도 가능하다
장점1. 카프카와 완벽 호환된다.
이런 외부 오픈 소스 툴의 문제는 오픈소스 카프카 버전에 따라오지 못하는 문제가 있는데 카프카 클러스터와 완벽히 소환되는 카프카 스트림즈~
유실이나 중복처리 되지 않고 강력한 기능이 있음
카프카와 연동하는 이벤트 프로세싱중에 유일할 것.
장점2. 스케쥴링 도구가 필요없다.
카프카와 연동하는 스트림 프로세스 툴로 가장 많이 쓰인느게 스파크스트리밍인데
마이크로 배치 처리하는 이벤트 데이터 애플리케이션을 만들 수 있는데
이걸 운영할라면 클러스터 관리자 또는 리소스 매니저들일 필요하다.
반면에 스트림즈는 스케쥴링 도구는 전혀 필요없다.
스트림즈 애플리케이션은 원하는 만큼 배포하면 됩니다.
만약 적은양의 데이터를 처리한다면 2개 정도로만 하고 많으면 스케일 아웃해서 10~20개를 처리한다.
장점3. 스트림즈 dsl과 프로세서 api를 제공한다.
스트림즈dsl은 이벤트 기반 데이터 처리를 할 때 필요한 map, join, window와 같은 메서드를 제공하기에 편리하다.
없다면 프로세서 api를 사용해서 하면 된다. 근데 거의 강력한 기능들을 다 내포하고 있어서 거의 쓸 일 없다.
장점4. 로컬 상태 저장소를 사용한다.
실시간으로 데이터를 처리하는 방식
- 비상태기반처리
- 상태기반 처리
비상태기반은 필터링이나 데이터를 변환하는 처리인데 이런 처리는 데이터가 들어오는 적고 바로 처리하고 프로듀스하면 되기 때문에 유실이나 중복이 발생할 염려가 적고
문제는 stateful 상태기반 처리를 직접 구현하려면 엄청 어렵다. 왜냐면 윈도우, 조인 취합과 같은 처리를 프로세스가 메모리 저장하고 있으면서 다음 데이터를 참조해서 처리해야하기 때문이다. 이런 상태기반 분산프로세스를 구현하는건 허들이 너무 높다.
이걸 해결하는게 스트림즈 스트림즈는 로컬에 rocksdb를 사용해서 상태를 저장하고 상태에 대한 변환정보는 카프카의 변경로그 토픽에 저장한다.
그래서 스트림즈 사용하면 프로세스에 장애 발생해도 그 상태가 모두 안전하게 저장된다. 자연스럽게 장애 복구 가능.
카프카 커넥트
반복적인 데이터 파이프라인을 효과적으로 배포하고 관리하는 방법
=> 커넥트를 활용한다.
카프카에서 공식적으로 제공하는 컴포넌트중 하나이다.
커넥트와 커넥터로 이뤄진다.
커넥트:
커넥터를 동작하도록 실행해주는 프로세스
커넥터:
실질적으로 데이터를 처리하는 코드 담긴 jar 패키지
특정 동작을 하는 코드 뭉치
파이프라인에 필요한 동작, 설정, 실행 매서드들이 포함되어 있다.
커넥터
1. 싱크 커넥터
어딘가로 데이터를 싱크한다는 뜻으로 다르 db로 저장하는 역할
컨슈머와 같은 역할을 한다.
2. 소스 커넥터
데이터베이스로부터 토픽에 넣는 역할
프로듀서 역할
ex) 토픽의 데이터를 오라클 특정 테이블에 넣고 싶다 : oracleSinkConnecter
커넥트
1. 단일 실행모드 커넥트
간단한 데이터 파이프라인 구성 / 개발용
2. 분산 모드 커넥트
여러개의 프로세스를 한개의 클러스터로 묶어서 운영하는 방식
일부 커넥트에 장애가 생기더라도 파이프라인을 자연스럽게 failover로 해서 나머지를 지속적으로 처리할 수 있게 한다.
커넥터와 커넥트의 관계?
커넥트를 실행할 때 커넥터가 어디 위치하는지 config파일에 위치 지정해야한다.
커넥터 jar가 있는 디렉토리를 config파일에 지정하면 이 jar파일의 커넥터들을 모아서 준비상태로 돌입한다.
rest Api를 통해서 커넥터를 통한 파이프라인들이 분산에서 실행할 수 있다.
오라클 db에 데이터를 저장하는 싱크 커넥터가 있다면 특정 토픽에 잇는 데이터를 특정 테이블로 보낼려면 json을 만든다. 이 바디를 restAPI를 통해 커넥트에 명령을 내리는것
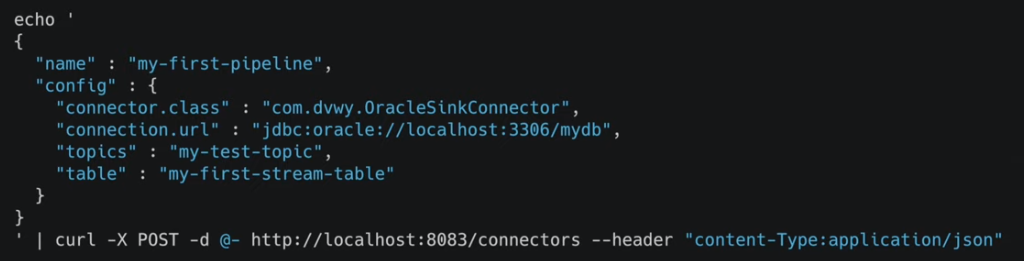
파이프라인을 반복적으로 만들때는 커넥트를 구축해서 반복적으로 커넥터를 실행하는 방식이 여러컨슈머를 만드는 것보다 낫다!
오픈소스 커넥터가 많아서 검색해서 사용해봐라!
클라우드 기반 아파치 카프카 서비스
saas형의 아파치 카프카
클릭 몇번으로 설정하면 즉시 구축된 카프카 서비스를 설정할 수 있다.
웹 인터페이스를 통해 쉽고 간편하게 쓰이기 때문에 클러스터 운영에 들어가는 개발자 리소스를 줄일 수 있다.
출처 및 관련강의 : https://www.inflearn.com/course/아파치-카프카-입문
