Parallel Consumer 를 읽고나서
개요
팀에서 여러 형태로 카프카를 많이 사용하고 있는데, 처리량을 늘리 수 있다는 Parallel Consumer 에 대해서 알아보고 팀에 느낀점과 서비스에 적용해볼만한 포인트를 작성해본다.
파티션 늘리면 안 돼?
기존에는 파티션을 늘리고, BatchConsumer 를 이용해서 메시지를 배치 처리하는 형태로 동시 처리량을 늘려왔다. 플랫폼 팀에서 카프카를 제공해줬기 때문에, 파티션에 늘어나는 것에 따라 발생하는 여러 단점에 대해서는 생각지 못했었다. 서비스에 따라 수백개의 파티션을 사용하는 경우도 있는데, 이번기회로 반성을 해본다
Parallel Consumer
Parallel Consumer 의 개요를 읽어보면, 단일 파티션에 여러 컨슈머 스레드를 사용하여 파티션을 늘리지 않고 동시 처리량을 증가시키기 위해 만들어진 라이브러리라고 할 수 있다.
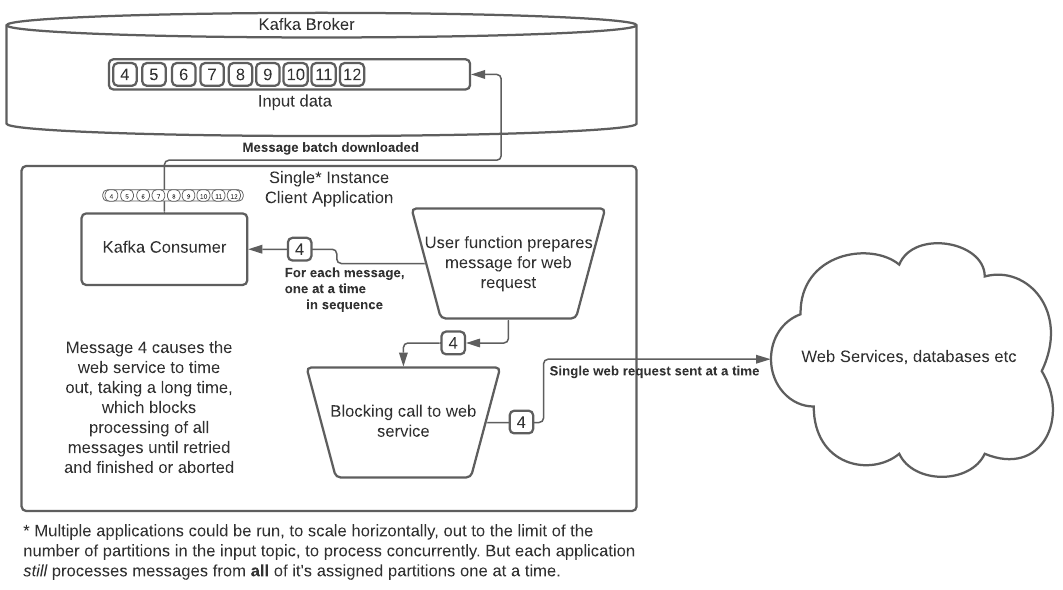
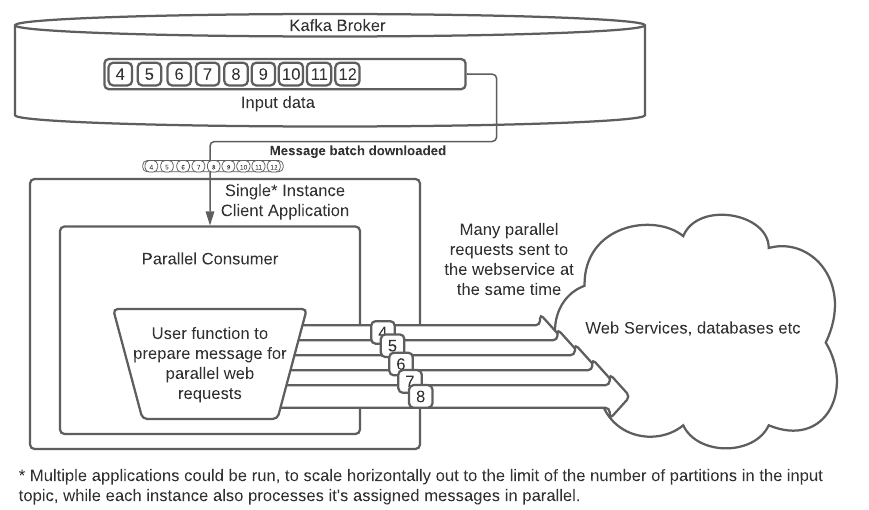
쉽게 말하면 아래 처럼 하나의 컨슈머에서 여러 메시지를 동시처리 할 수 있다는 것이다. 처음에는 commit 때문에 어떻게 동시처리할 수 있을까하는 생각이 들었다.
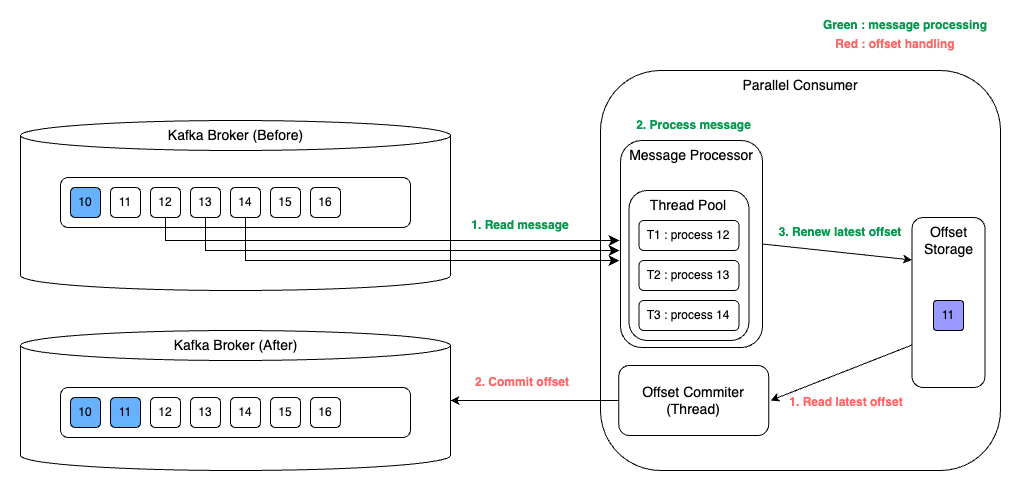
살펴보니 위와 같이 메시지 처리와 커밋을 비동기로 처리하는 방식으로 이해했다. 메시지는 병렬로 각자의 메시지를 처리하고, 처리한 메시지를 저장하고, 가장 최신의 offset 을 commit 하는 것이 각각 비동기로 동작한다.
순서 보장 방식
그 다음의문이 순서 보장이다. 기존에는 순서보장을 위해서는 parition key 를 지정해서, partition 내에서 순서보장을 하는 방식을 주로 사용했다. parallel consumer 에는 아래와 같이 3가지 방식이 지원된다
- Partition: Kafka 파티션 단위로 순서보장을 하는 것으로 원래방식과 큰 차이가 없어봉니다
- Key : Kafka 메시지에 있는 Key를 이용하여 Key 단위의 순서를 보장한다. 기존 Kafka 방식과 다른 점은, 동일 파티션 내에도 Key 가 다르면 메시지가 병렬로 처리 가능하다는 것이다.
- Unordered: 순서를 보장하지 않고, 앞서 들어온 메시지의 완료를 기다리지 않고 전부 병렬로 처리한다.
Parallel Consumer의 내부 구조
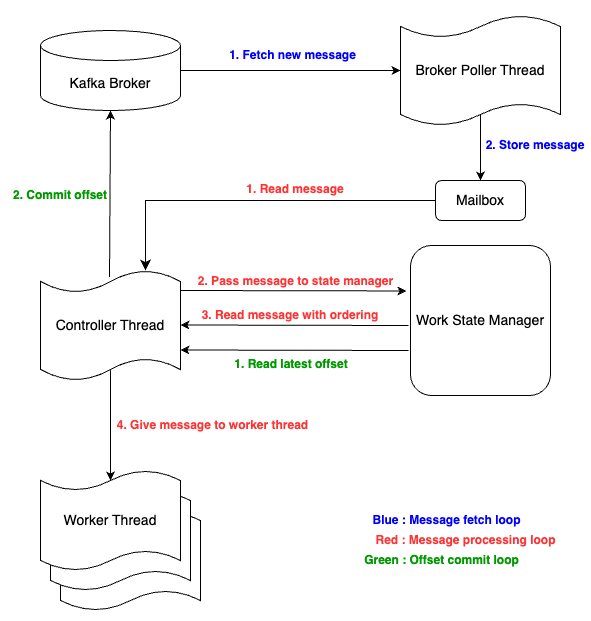
간단히 모듈별로 정리해본다. 자세한 설명은 d2블로그를 참조하자.
- Broker Poller Thread: 실제 Kafka 메시지를 읽어서 Mailbox 에 저장한다
- Controller Thread: mailbox 에서 메시지를 가져와 Worker Therad 에 전달하고, 최신의 offset 을 commit 한다. (전체적인 orchestration 을 담당한다)
- mailbox: 카프카 메시지를 전달하기 위한 매개체
- Work State Manager: 메시지의 순서 보장 및 처리한 오프셋을 관리한다. Controller Thead 에게 적합한 메시지를 전달하고, commit 할 offest 정보를 전달한다
순서 보장 방식 구현
Parallel Consumer는 Kafka 메시지를 shard 단위로 분배하며, 각 shard별로 작업이 병렬 수행된다.
파티션과 별개의 shard라는 개념을 이용해 위에 설명한 것처럼 Partition, Key, Unordered 등을 구현하는 것으로 생각된다. 기억할만한 점은 Partition/key 방식은 순서를 보장하기위해 shard 별로 1개씩의 메시지가 contro ller therad 에 전달되지만, unordered 는 순서를 보장하지 않아도 되기 때문에 batch size 만큼 메시지가 전달된다
오류로 인한 메시지 중복 처리 방지
예를 들어 한 파티션에서 4, 5, 6, 7번 오프셋을 처리 중 4, 6, 7번 오프셋은 성공했지만 5번 오프셋은 처리하지 못한 경우 4번 오프셋까지 완료했다고 커밋한다.
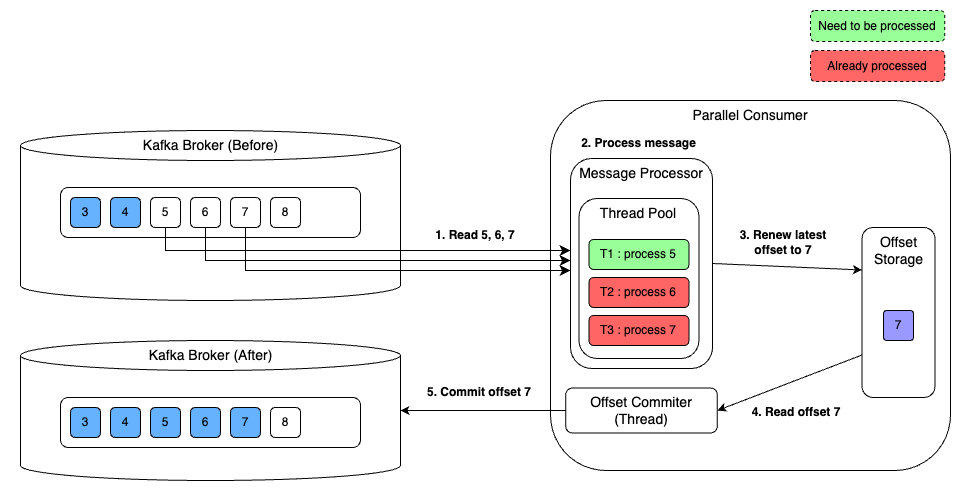
완료되지 않은 오프셋들을 오프셋 메타데이터에 기록한다. 이를 incompleteOffsets이라고 부른다. 최신 offset 과 오프셋 메타데이터를 비교해 처리할 메시지를 선정하는 것이다. 카프카 브로커에는 아직 4번 offset 이 commit 되어있으므로 5,6,7 을 순차적으로 읽게되고 이때 처리되지 않은 offset 5 의 메시지만 처리하고 6,7은 처리하지 않게된다. 오류 시에 같은 메시지를 여러번 읽게되는 경우를 줄여줄 것 같다.
우아한 종료
Parallel Consumer에는 DrainingMode라는 것이 존재한다.
- DRAIN: queue 에 존재하는 것은 모두다 처리후 종료
- DONT_DRAIN: 메시지를 모두 버린다
특이한 점은 처리한 오프셋에 대한 commit 은 수행한다는 것이다.
성능 비교
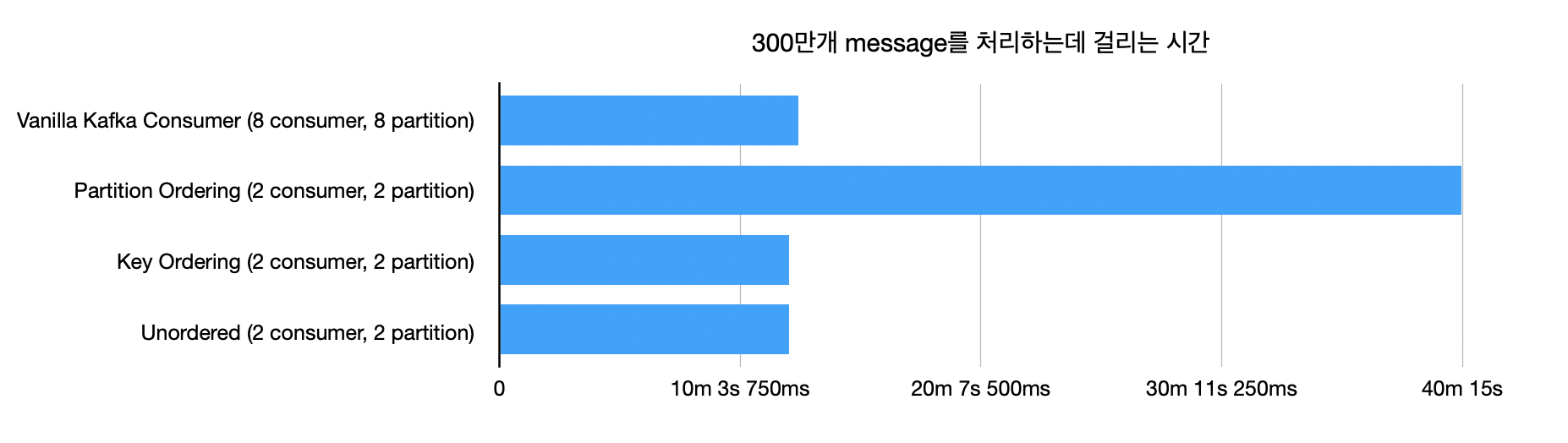
성능 결과를 보아하니 Key가 고르게 분배된다면 Key 도 사용해볼만 하다.
결론 및 느낀점
Parallel consumer 개념 자체는 굉장히 좋게 와닿았다.
파티션 증가에 대한 부담이 있다면 사용할 수 있을 것 같다. Key 방식을 도입하고, 파티션 증설에 어려움이 있다면 써볼만 할 것 같다. 하지만 아직 0.5.2.8 버전이 최신버전이기도 하고, 조금은 더 지켜봐야할 상황이 아닐까 생각한다.
내부적으로 reactor-kafka 도 사용하고 있기 때문에, maxDeferredCommits 에 대해서도 살펴보고 도입을 고민해봐야겠다.
Reference
https://d2.naver.com/helloworld/7181840
https://github.com/confluentinc/parallel-consumer
