제너레이터를 사용하게 되면 성능을 향상 시키며 , 메모리 사용을 줄이고 , 가독성을 높일 수 있다.
📌better way 27 map 과 filter 대신 컴프리헨션을 사용
파이썬은 다른 시퀀스나 이터러블에서 새 리스트를 만들어내는 간결한 구문을 제공한다
=> 리스트 컴프리헨션
📌better way28 컴프리헨션 내부에 제어 하위 식을 세개 이상 사용하지 말라
리스트 컴프리헨션 에 하위식은 컴프리헨션에 들어간 순서대로 왼쪽에서 오른쪽으로 실행된다.

조건문을 추가하는것도 가능하다.
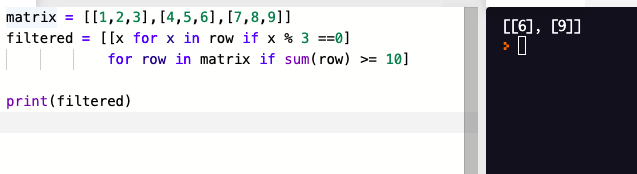
하지만
이 이상 컴프리헨션이 길어지게 된다면.. 사용하는 것을 권장하지 않는다.
가독성이 안좋아 진다.
📌 better way 29 대입식을 사용해 컴프리헨션 안에서 반복 작업을 피하라
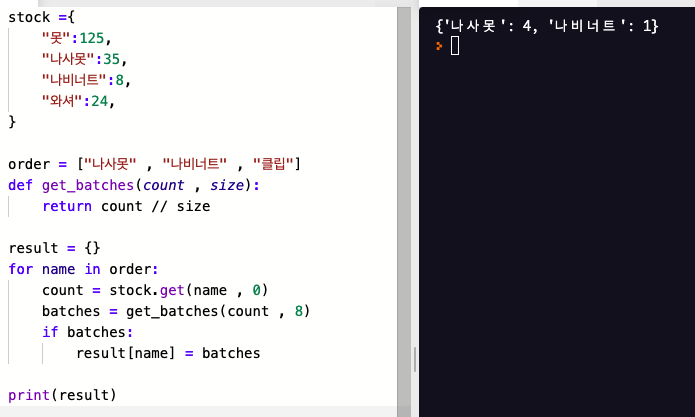
딕셔너리 컴프리헨션을 사용하게 되면 간결하게 표현할 수 있다.
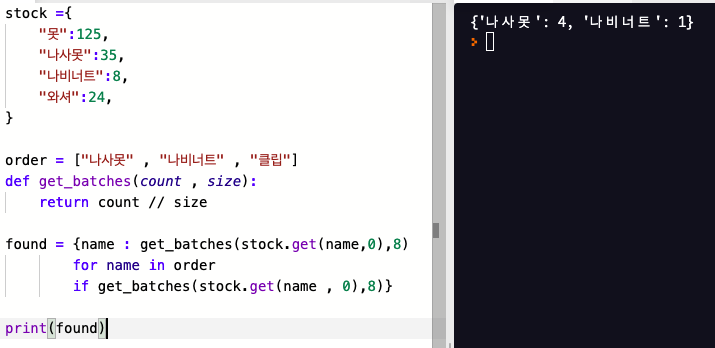
하지만 가독성이 문제가 있을 수 있을 수 있다.
여기에 왈러스 를 사용해 보자.
👉왈러스
파이썬 3.8 에 도입된 왈러스 연산자 (:=) 를 사용해서 컴프리헨션의 일부분에 대입식을 만들 수 있다.
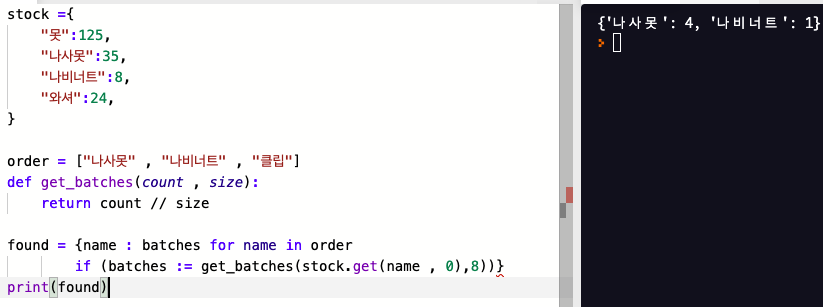
stock 딕셔너리에서 각 order 키를 한 번만 조회하고 get_bacthes 를 한 번
만 호출해서 그 결과를 batches 변수에 저장 할 수 있다.
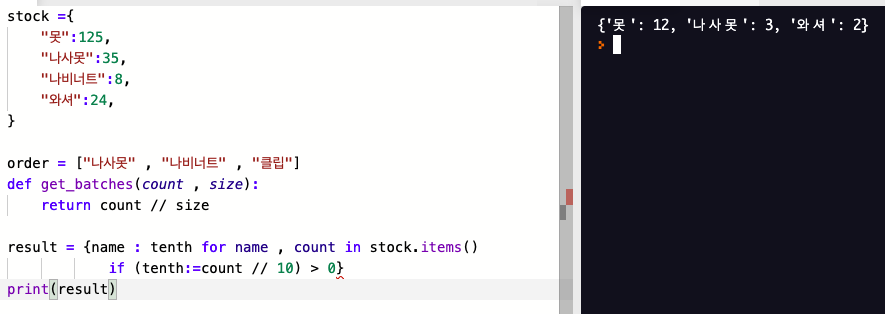
컴프리헨션이 값 부분에서 왈러스 연산자를 사용할 때 그 값에 대한 조건 부분이 없다면 ,
루프 밖 영역으로 루프 변수가 누출된다.
👉 변수 누출
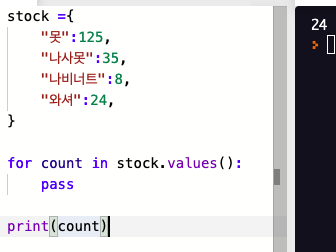
이 부분에서 count 가 왜 출력이 되는걸까 ?? 출력이 안되야하는게 아닐까 ?
하지만 컴프리헨션의 루프 변수인 경우에는 비슷한 누출이 생기지 않는다.
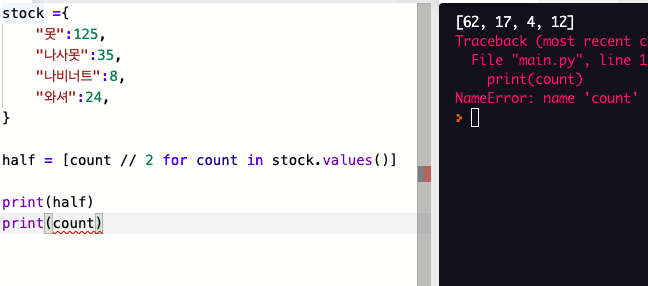
에러발생
따라서 컴프리헨션에서 대입식을 조건에만 사용하는 것을 권장한다.
📌better way30 리스트를 반환하기 보다는 제너레이터를 사용하라
앞전엔 list comprehension 에 대한 내용이 나왔지만
list comprehension 과 generator 에 대해서 알아본다.
() 사이에 list comprehension 과 비슷한 구문을 넣어 제너레이터 식(generator expression) 을 만들 수가 있다.
# 리스트 컴프리헨션
value = [len(x) for x in open('my_file.txt')]
print(value) # [7, 5, 4, 1, 5] (뉴라인 문자가 있어 눈에 보이는 것 보다 1 길다)
# Example 2 (제너레이터 식)
it = (len(x) for x in open('my_file.txt'))
print(it) # <generator object <genexpr> at 0x000002F4E761DAC0>
print(next(it)) # 7
print(next(it)) # 5제너레이터 식은 이터레이터처럼 한 번에 원소를 하나씩 출력하기 때문에 메모리 문제를 피 할 수 있다.
def index_words(text):
result = []
if text:
result.append(0)
for index , letter in enumerate(text):
if letter == " ":
result.append(index + 1)
return result
address='오늘은 금요일 입니다.'
result = index_words(address)
print(result[:2])
코드의 잡음이 많다.
이 함수를 개선하는 방법으로 제너레이터 를 사용하는 것이다.
# Not Good
def index_words(text):
result = []
if text:
result.append(0)
for index, letter in enumerate(text):
if letter == " ":
result.append(index + 1)
return result
print(index_words("안녕하세요 오늘은 제가 발표하는 날입니다.."))
# [0, 6, 10, 13, 18]개인적으로.. 이렇게 코드를 작성해도 전혀 문제가 없어 보이지만 ,,
책에서는 제너레이터 를 사용하는것을 권장 하고 있다.
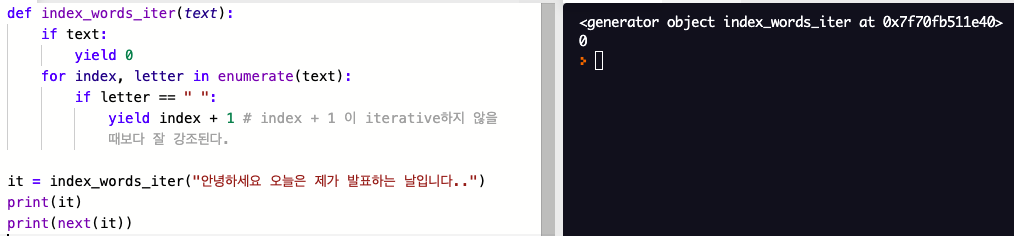
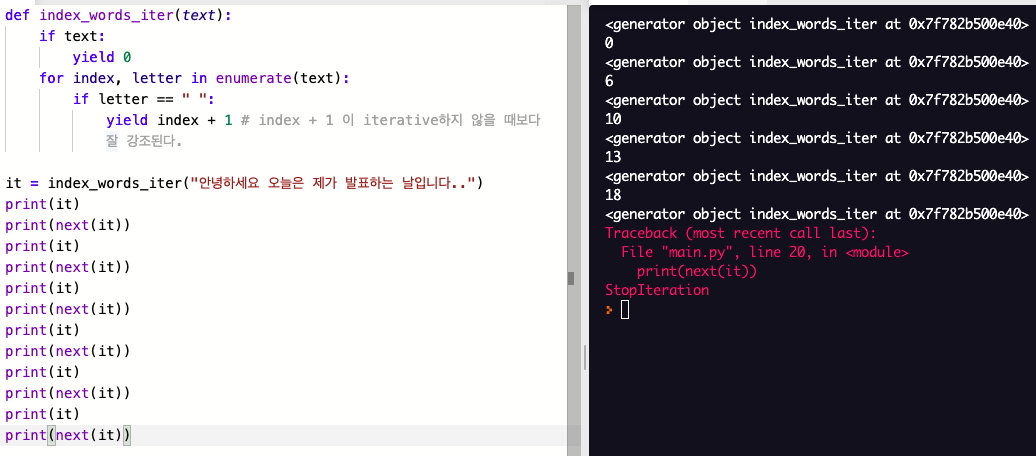
def index_words_iter(text):
if text:
yield 0
for index, letter in enumerate(text):
if letter == " ":
yield index + 1 # index + 1 이 iterative하지 않을 때보다 잘 강조된다.
it = index_words_iter("안녕하세요 오늘은 제가 발표하는 날입니다..")
print(it) # <generator object index_words_iter at 0x7f70fb511e40>
print(next(it)) # 0
print(next(it)) # 6코드는 깔끔해 진것 같다 하지만 yield 식에 의해 전달이 된다.
그리고 다 출력이 됬으면 , StopIteration 에러를 뱉게된다.
📌👉
📌 better way 32긴 리스트 컴프리헨션 보다는 제네레이터 식을 사용
긴 리스트 컴프리헨션의 문제점은 메모리를 많이 차지하게 된다.

만약에 이러한 리스트가 있다고 했을때 각 요소의 길이를 구한다고 하면
list comprehension 을 사용할 경우 ,
메모리에 저장을 해야한다. 크기가 작으면 문제 되지 않겠지만 만약 크다면 메모리를 많이 차지하게 됨
그래서 generator 를 사용하는것을 권장한다.
lst = [35, 20, 49]
type(iter(lst))
val = (x for x in lst)
print(next(val)) # 35
print(next(val)) # 20
print(next(val)) # 49📌better way33 제너레이터 합성
제너레이터 식이 반환한 이터레이터를 다른 제너레이터 식의 하위 식으로 사용함으로써 제너레이터 식을 서로 합성 할 수 있다.
제너레이터 식이 반환한 이터레이터를 다른 제너레이터 식의 입력으로 사용
# Example 2 (제너레이터 식)
it = (len(x) for x in open('my_file.txt'))
print(it) # <generator object <genexpr> at 0x000002F4E761DAC0>
# 제너레이터 식 합성 (roots 에 next가 불리면 it 먼저 한 칸 진행함)
roots = ((x, x**0.5) for x in it)
print(next(roots)) # (7, 2.6457513110645907)
print(next(roots)) # (5, 2.23606797749979)