데이터베이스 정규화 란 ?
데이터베이스 정규화가 뭘까 ??
한참을 고민하다가
chat gpt 에 질문을 해봤다.
데이터베이스 정규화는 데이터의 중복성을 최소화하고 데이터 무결성을 유지하기 위해 디자인된 규칙 또는 원칙들의 집합입니다. 정규화의 목적은 데이터 구조의 비효율성과 중복성을 제거하며, 데이터에 대한 삽입, 삭제 및 갱신 이상 현상(insertion, deletion, and update anomalies)을 방지하는 것입니다.
-
1NF (첫 번째 정규형)
- 각 칼럼의 값이 원자적 (atomic) 해야 한다는 원칙에 기반합니다.
- 즉, 각 칼럼에는 반복되거나 리스트 형태의 데이터가 들어갈 수 없습니다.
- 모든 엔트리(레코드)는 유일한 키에 의해 식별됩니다.
-
2NF (두 번째 정규형)
- 1NF를 만족하고 추가로, 부분 함수 종속성(partial functional dependency)을 제거합니다.
- 이는 복합키 (composite key, 여러 칼럼으로 이루어진 키)를 사용하는 테이블에서 관련 없는 칼럼들이 복합키의 일부에만 종속적인 경우 이를 분리하라는 원칙입니다.
- 예를 들어, 복합키가 A, B 라면, C라는 다른 칼럼이 A 또는 B에만 함수적으로 종속되는 경우, C와 관련된 칼럼은 별도의 테이블로 분리되어야 합니다.
-
3NF (세 번째 정규형)
- 2NF를 만족하면서 추가로, 이행적 함수 종속성(transitive functional dependency)을 제거합니다.
- 즉, A -> B, B -> C의 관계가 있을 때, A -> C의 관계가 이행적 함수 종속성을 형성합니다.
- 이러한 종속성이 테이블에 존재하면, C와 관련된 칼럼들은 별도의 테이블로 분리되어야 합니다.
정규화는 데이터베이스의 설계를 개선하기 위한 중요한 도구지만, 모든 경우에 무조건적으로 정규화를 적용해야 하는 것은 아닙니다. 때로는 성능 향상을 위해 의도적으로 비정규화(denormalization)를 수행하기도 합니다. 여러 원칙과 요구 사항을 고려하여 데이터베이스의 최적의 구조를 결정하는 것이 중요합니다.
정리하면 정규화를 하는 목적은 중복성을 없애고 데이터 무결성을 유지하기 위함이다.
하지만 때로는 성능 향상을 위해 비정규화를 할때도 있다.
정리하면 될것 같다.
그러면 정규화는 어떻게 하는걸까 ??
정규화 하는 방법
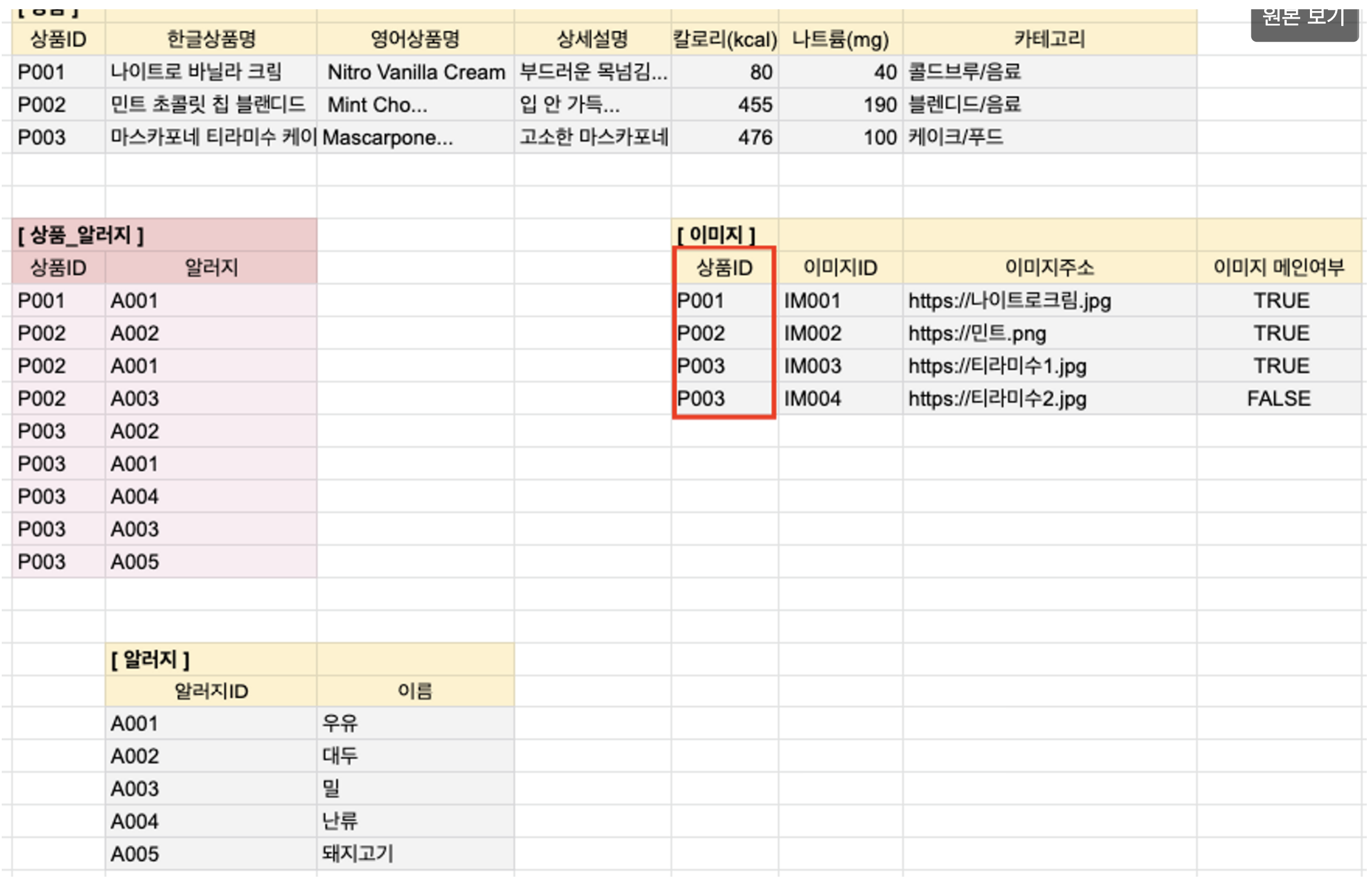
- 중복된 데이터가 있는지 파악을한다.
- 1: N 인지 N:M 인지 파악을 한다.
- 파악한 결과에 따라 id 값으로 빼버린다.

꾸준함이란 ... ?