탐색
많은 양의 데이터 중에 원하는 데이터를 찾는 과정을 말합니다
대표적인 알고리즘은 DFS, BFS가 있습니다
이에 대한 이해를 하려면 자료구조 스택과 큐에 대한 이해를 해야 합니다.
자료구조(Data Structure)
데이터를 관리하고 처리하기 위한 구조를 말합니다
다들 자료 구조가 아니더라도 한번 쯤은 개발을 하면서 들어본 용어일 겁니다
push와 pop 함수들입니다.
- 삽입push():데이터를 삽입한다(저의 방식 대로 이해하면 밀어넣는다 push 그래서 삽입)
- 삭제pop(): 데이터를 삭제한다(pop은 빵터져버린다 터져버리면 데이터가 없어지겠죠? 그래서 삭제)
그외에도
Overflow(오버플로우)
특정한 자료구조가 수용할 수 있는 데이터의 크기를 이미 가득찬 상태에서 발생하는 것으로, 데이터가 넘쳐 흐른다
underflow(언더플로우)
데이터가 전혀 들어 있지 않은 상태에서 삭제 연산을 수행하면 데이터가 전혀 없는 상태
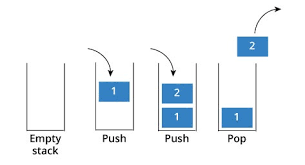
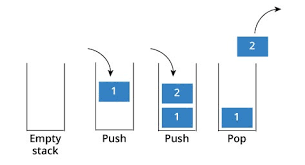
스택
선입후출(First In Last out) and 후입선출(Last In First out)구조를 말합니다
stack = []
#삽입(5) - 삽입(2) - 삽입(3) -삽입(7) - 삭제()- 삽입(1) -삽입(4)- 삭제()
stack.append(5)
stack.append(2)
stack.append(3)
stack.append(7)
stack.pop() #7이 삭제된다
stack.append(1)
stack.append(4)
stack.pop() #4가 삭제된다
print(stack) #최하단 원소부터 출력
print(stack[::-1]) #최상단 원소 부터 출력이렇게 되면
최하단 원소부터 출력하면 [5,2,3,1]
최상단 원소부터 출력하면 [1,3,2,5]
이렇게 되는 것이다
★ append() - 리스트의 가장 뒤쪽에 데이터를 삽입하는 함수
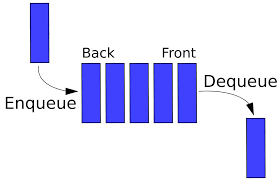
큐
First in First out(선입 후출)의 구조를 말합니다.
쉽게 생각해서 나중에 온 사람일 수록 나중에 들어간다!(놀이공원줄 생각하라)
from collections import deque
#큐 구현을 위해 deque라이브러리를 이용하였습니다
queue = deque()
#삽입(5)-삽입(2)-삽입(3)-삽입(7)-삭제()-삽입(1)-삽입(4)-삭제()
queue.append(5)
queue.append(2)
queue.append(3)
queue.append(7)
queue.popleft() #제일 앞의 요소가 삭제되는 것이 아니라 끝의 요소가 삭제됨
queue.append(1)
queue.append(4)
queue.popleft()
print(queue) #먼저 들어온 순서대로 출력
queue.reverse() # 다음 출력을 위해 역순으로 바꾸기
print(queue) #나중에 들어온 원소부터 출력이렇게 되면
먼저 들어온 순서대로 출력하자면
deque([3,7,1,4])
나중에 들어온 원소부터 출력하면
deque([4,1,7,3])
이러한 결과가 나온다.
모든 내용들은 이것이 코딩테스트다 나동빈님의 책을 참고하여 공부용으로 올림을 다시한번 알려드립니다

깊이 있는 배움을 가진 개발자 안성현입니다