
다들 한 번쯤은 웹 브라우저에서 찾고 싶은 단어를 빠르게 찾기 위해서 ctrl/cmd + f 단축키를 눌러서 검색해 본 적이 있을 것이다. ctrl/cmd + f를 누르고 찾고 싶은 단어를 입력하면 아래 캡처한 화면처럼 순식간에 원하는 단어를 모두 찾을 수 있다.
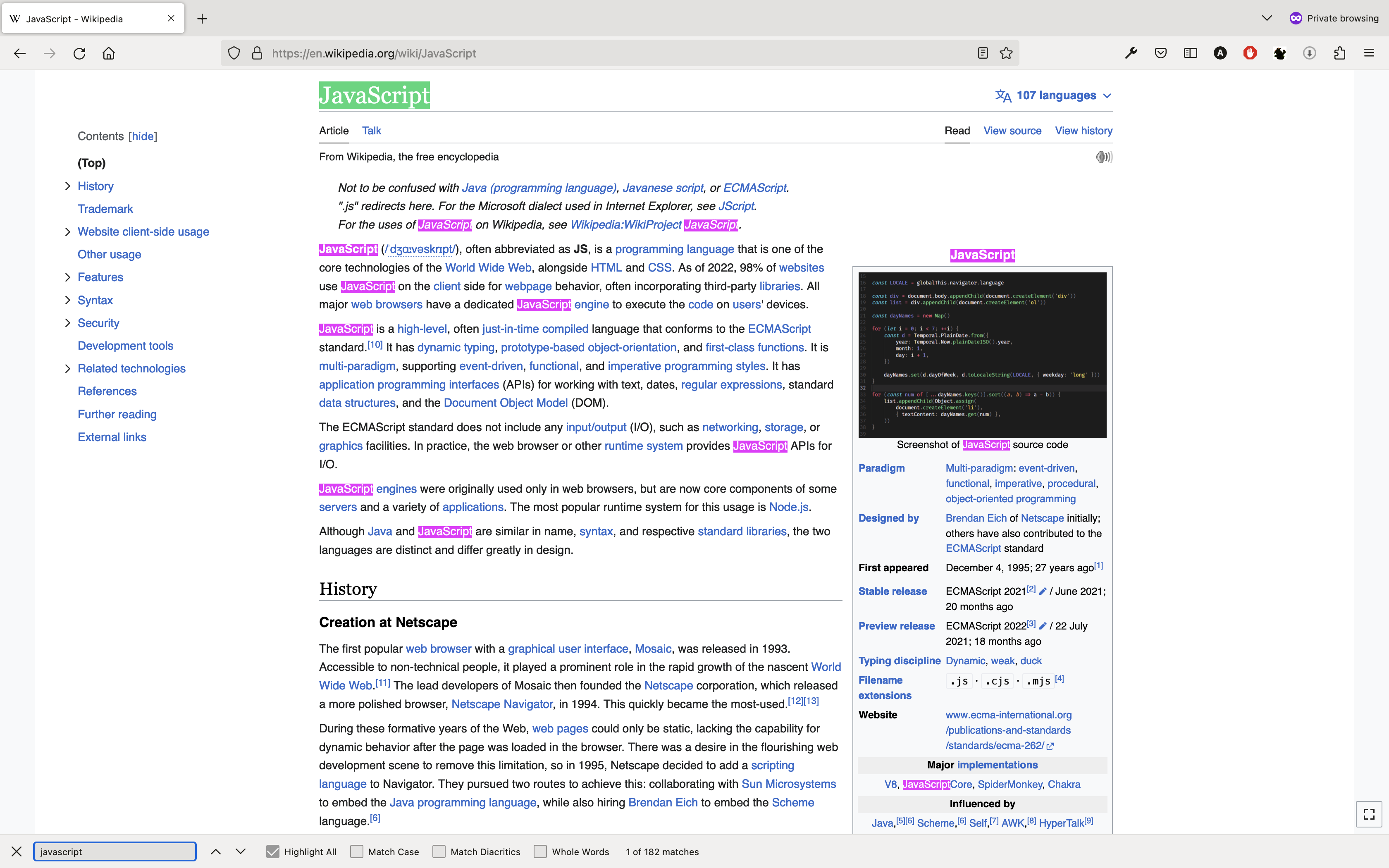
이처럼 텍스트 내에서 특정 문자열 또는 패턴을 찾는 것을 문자열 검색이라고 한다.
가장 단순한(무식한) 문자열 검색
그럼 어떻게 해서 문자열을 검색할 수 있을까? 가장 쉬운 방법은 전부 다 비교하는 것이다.

말 그대로 원본 문자열과 찾고 싶은 문자열의 모든 문자를 하나하나 다 비교하는 것이다.
문자열의 맨 앞부터 시작해서 탐색하다, 두 문자가 일치하지 않으면 원본 문자열의 두 번째 문자부터 다시 비교하는 과정을 거치는 방법이다.
이때의 시간 복잡도는 원본 문자열의 길이가 n, 탐색 문자열의 길이가 m일 때 O(nm)이다.
운이 좋으면 원본 문자열의 앞에 있는 문자들이 찾고 싶은 문자열이랑 전부 일치해서 빠르게 끝날 수도 있다. 하지만 위에 있는 Wikipedia 예시처럼 수많은 문자열들 속에서 javascript와 일치하는 모든 서브 스트링을 찾으려면 엄청나게 많은 시간이 걸릴 것이다.
그럼 이보다 더 효율적으로 문자열을 검색할 수 있는 방법은 없을까?
있다!! KMP 알고리즘을 이용하면 시간 복잡도 O(n + m)으로 문자열 검색을 할 수 있다.
KMP 알고리즘
KMP는 Knuth-Morris-Pratt의 약자로 이 알고리즘을 만든 Donald Knuth, James H. Morris와 Vaughan Pratt을 이름을 따서 명명되었다.
있어 보이는 이름을 가진 것 말고 도대체 이 알고리즘은 무엇을 어떻게 하길래 이렇게 빠르게 탐색할 수 있을까?
접두사(Prefix) & 접미사(Suffix)
먼저 KMP 알고리즘을 이해하기 위해서는 접두사와 접미사의 개념을 알아야 한다.
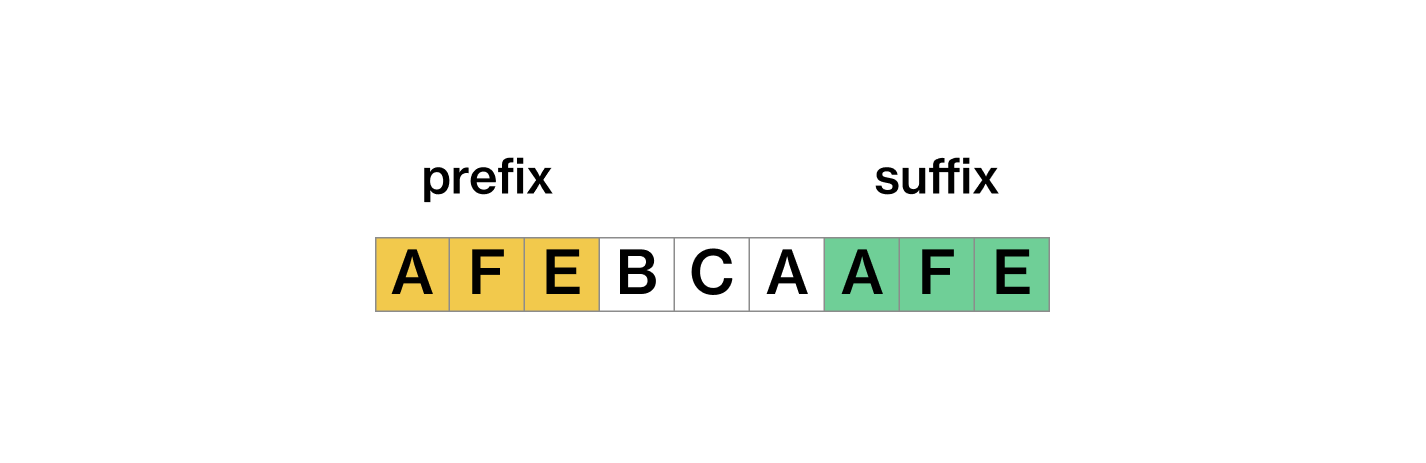
KMP에서 접미사와 접두사란, 문자열에서 맨 앞과 맨 뒤에 같은 문자열이 나오는 경우를 말한다. 위 그림처럼 문자열 속에서 앞에 위치한 서브 스트링(접두사)이랑 뒤에 위치한 서브 스트링(접미사)이 AFE로 같은 경우인 것이다.
KMP 알고리즘 컨셉
KMP 알고리즘은 위에서 알아 본 간단한 문자열 검색에서 문자 하나하나를 비교하지 말고 일정 부분을 건너 뛰어서 검색을 할 수는 없을까?라는 아이디어에서 시작됐다.
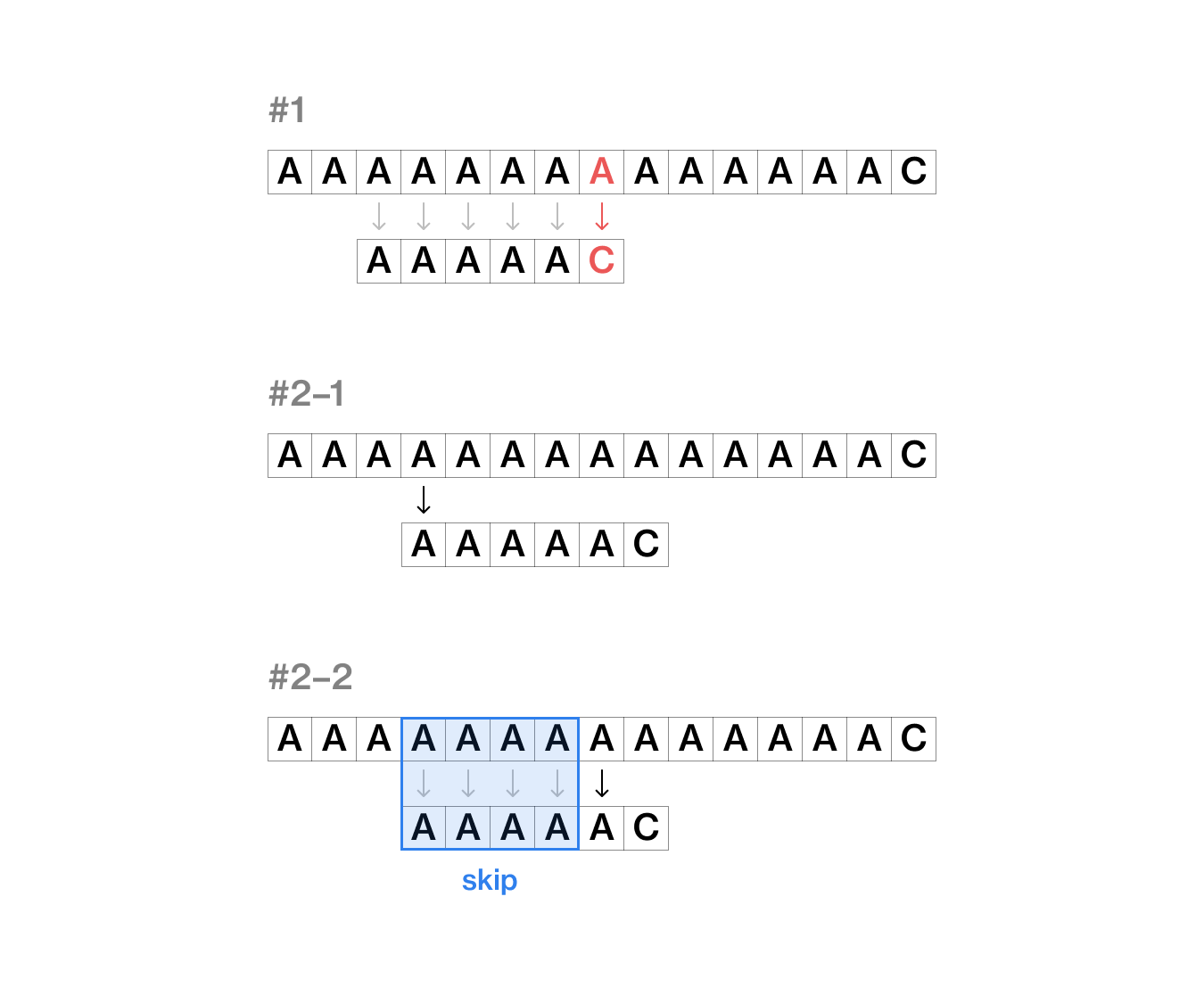
문자열이 불일치하는 경우, 일정 부분을 건너 뛸 수는 없을까?
위 예시처럼 문자열이 불일치할 때 #2–1처럼 다시 시작했던 위치의 다음 문자부터 탐색 문자열도 처음부터 검색하는 대신, #2–2처럼 앞서 탐색했던 정보를 이용해서 일정 부분을 건너뛴 후 탐색을 재개하는 것이 KMP 알고리즘의 컨셉이다.
그럼 언제 특정 구간을 건너뛸 수 있을까?
KMP 알고리즘에서는 건너 뛴 후의 탐색 문자열의 앞 부분과 원본 문자열의 뒷부분이 일치해야 건너뛸 수 있다. KMP 알고리즘은 문자열이 일치하지 않는다는 사실보다는 조금이라도 일치했다에 주목해서 문자열 탐색을 더 효율적으로 만들어 준다.
그럼 얼마큼 건너뛸지 어떻게 알 수 있을까?
그건 바로 위에서 알아 본 접두사와 접미사를 활용하면 된다.
탐색 문자열의 가장 긴 접두사와 접미사를 미리 알고 있다면, 얼마큼 건너뛸 수 있는지 알 수 있다.
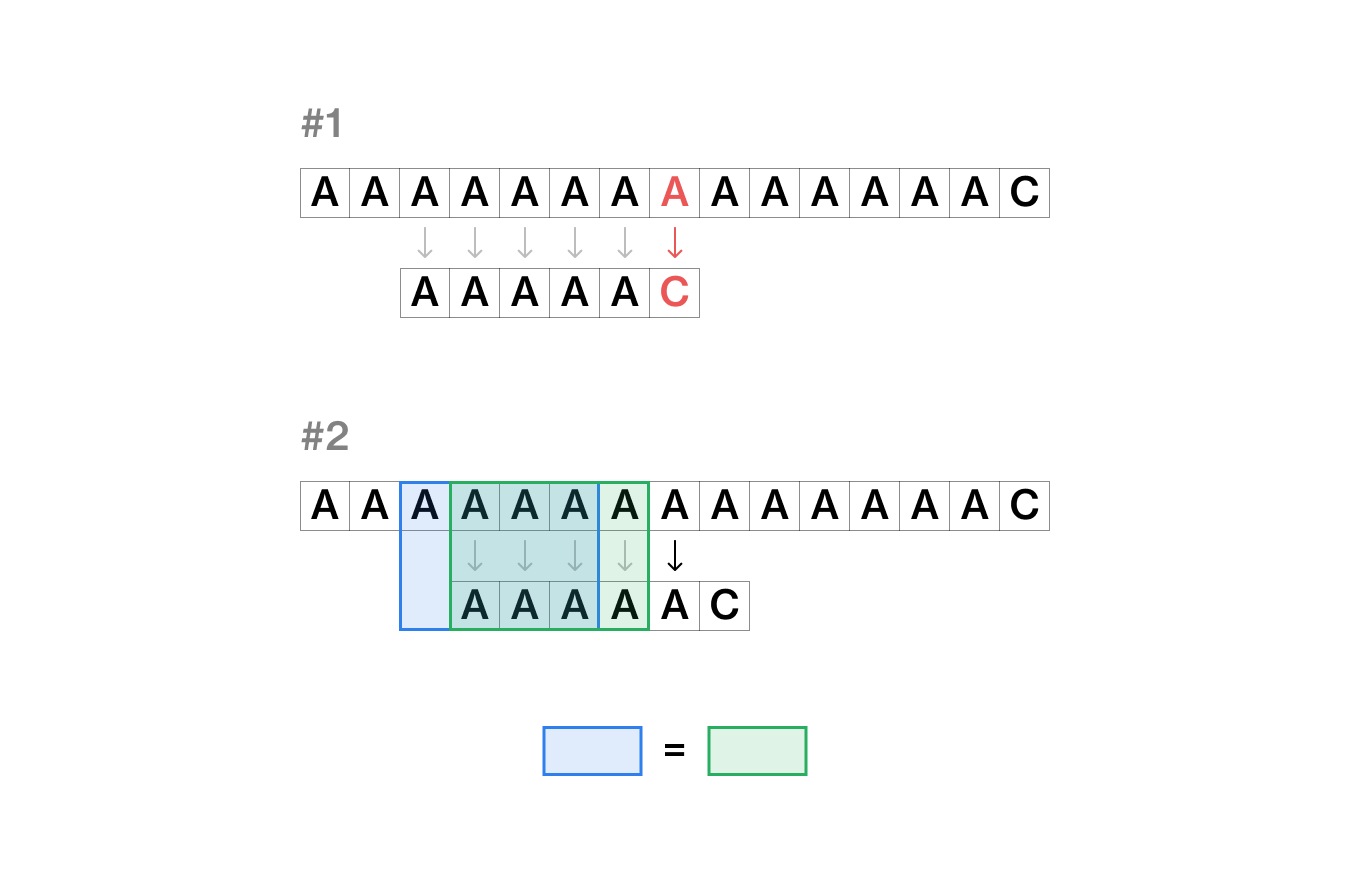
위 이미지처럼 건너뛰어서 원본 문자열의 불일치가 일어났던 시점이랑 탐색 배열의 불일치가 일어나기 직전의 시점에서 다시 검색을 시작하기 위해서는 그전까지 탐색했던 부분인 파란색 섹션과 건너뛴 초록색 섹션이 일치해야 한다.
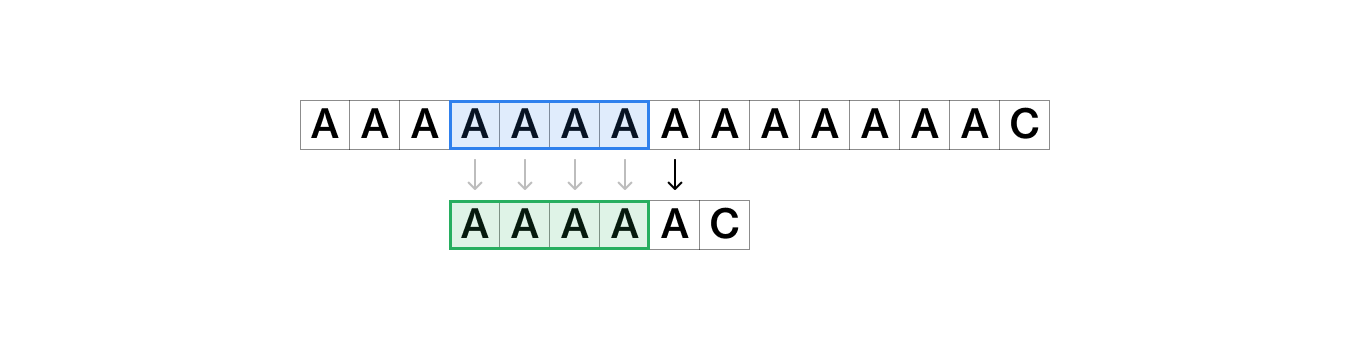
즉, 이렇게 탐색 문자열의 앞 부분과 원본 문자열의 뒷부분이 동일한 부분까지는 문자열 탐색을 건너뛸 수 있다! 유레카!
그럼 이제 KMP 알고리즘을 어떻게 구현하는지 알아보자.
KMP 알고리즘 구현
KMP 알고리즘은 크게 두 파트로 나눠진다.
- 얼만큼 건너뛸 수 있는지 알기 위해서 가장 긴 접두사와 접미사 찾기
- 원본 문자열에서 탐색 문자열과 일치하는 위치 찾기
LPS: Longest Prefix Suffix
const kmp = function (substr) {
const lps = new Array(substr.length).fill(0);
let i = 1;
let j = 0;
while (i < substr.length) {
if (substr[i] !== substr[j]) {
if (j === 0) i += 1;
else j = lps[j - 1];
} else {
j += 1;
lps[i] = j;
i += 1;
}
}
return lps;
};
kmp()는 탐색 문자열의 가장 긴 접두사와 접미사(Longest prefix suffix)를 찾는 함수다.
이렇게 설명하면 이해하기 어려우니까 그림이랑 함께 보자!

KMP 알고리즘의 핵심은 가장 긴 접두사와 접미사를 구해서 건너뛸 부분을 건너 뛰는 것이라고 했는데, 어느 시점에서 얼마만큼 건너뛸지 알기 위해서 탐색 문자열이 가장 짧을 때부터 가장 길 때까지 같은 접두사 접미사를 구해서 기록해 주는 것이다.
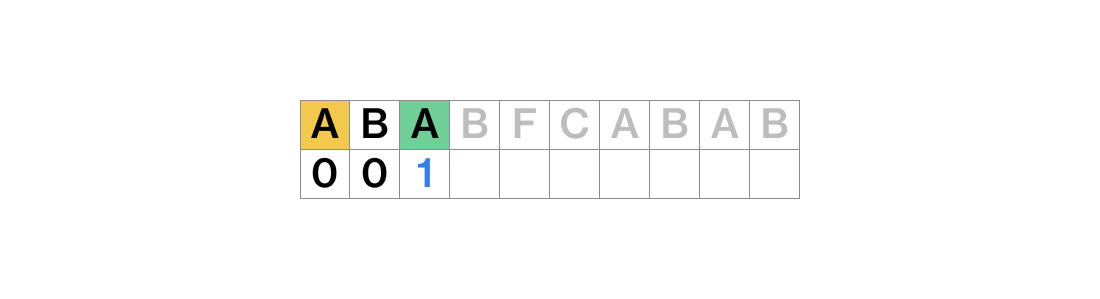
위 예시를 보면, 일단 A 혼자서는 어떠한 접두사와 접미사를 가지지 못하기 때문에 lps는 0이다. 마찬가지로 AB 또한 공통된 접두사와 접미사가 없기 때문에 0이다.
이번에는 드디어 우리가 공통된 접두사와 접미사를 찾았다!
ABA에서 접두사 A와 접미사가 일치하기 때문에 이번에는 lps는 A의 길이인 1이 된다.
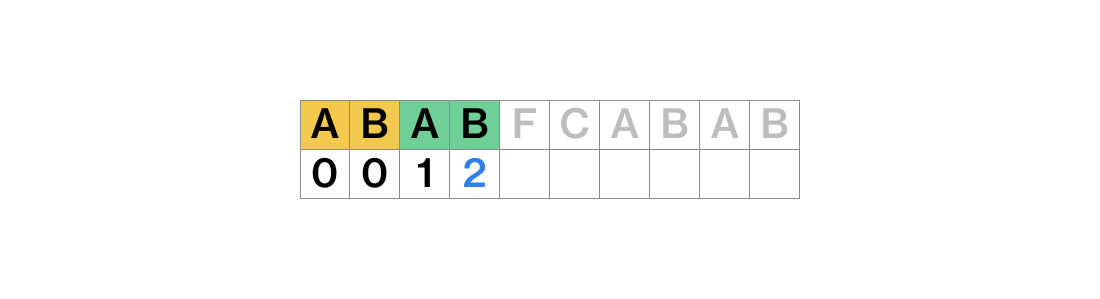
이다음에도 접두사 AB와 접미사 AB가 같기 때문에 lps는 2가 된다.
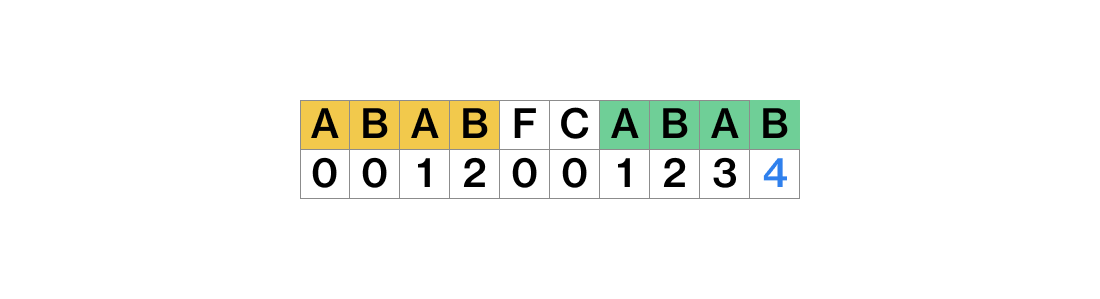
그래서 최종적으로 탐색 문자열 ABABFCABAB의 lps를 찾으면 [0, 0, 1, 2, 0, 0, 1, 2, 3, 4]가 된다.
그럼 우리는 이 lps 배열 정보를 이용해서 문자열 검색을 하면 된다.
문자열 검색
const search = function (str, substr) {
const lps = kmp(substr);
let i = 0;
let j = 0;
while (i < str.length) {
if (str[i] === substr[j]) {
if (j === substr.length - 1) return i - j;
i += 1;
j += 1;
} else if (str[i] !== substr[j]) {
if (j === 0) i += 1;
else j = lps[j - 1];
}
}
return -1;
};앞에서 설명한 것처럼 이제 lps 정보를 이용해서 O(m + n)의 시간 복잡도로 문자열 검색을 할 수 있다!
원본 문자열이랑 탐색 문자열이 불일치하면 lps 정보를 통해서 탐색 문자열에서 가장 마지막까지 일치했던 부분을 찾고 그 위치부터 다시 비교를 시작한다.
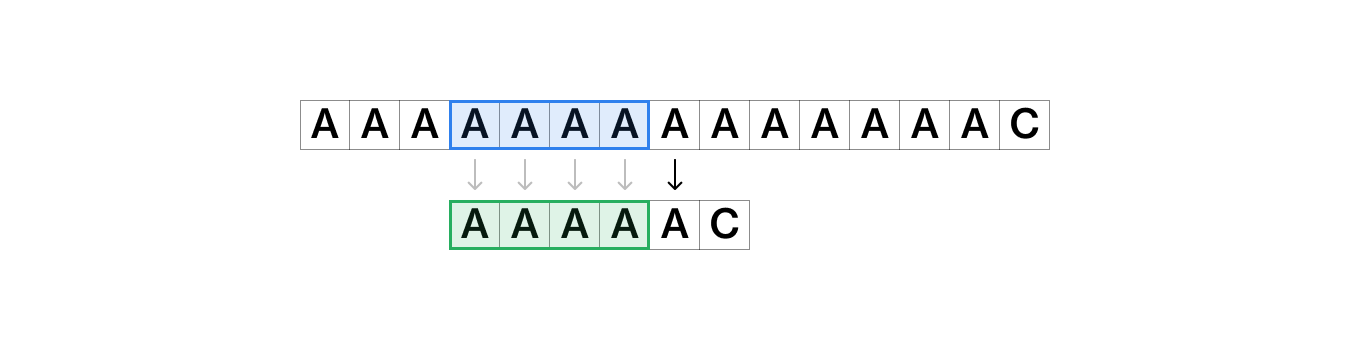
위에서 예시로 보여줬던 이 이미지처럼 검은색 화살표부터 다시 검색을 시작한다. 그럼 단순하게 비교하는 알고리즘과 다르게 회색 화살표 부분은 다시 비교하지 않아도 된다.
