대표적인(?) 문자열 탐색 알고리즘 KMP알고리즘.
KMP는 만드신 분들 이름의 앞 글자를 따온 듯 하다.
(사실 알려줘서 공부했지. 혼자서 뭔지 접했으면 때려치웠을지도..?)
그래서 KMP는 뭐고 LPS는 또 뭔데..,,
문자열 패턴 매칭하면 제일 먼저 떠오르는 건 역시 Brute force로 하나하나 비교하는 건데, 이럴 경우 최악의 시간복잡도는 O(len(pattern)*len(text))이다.
그래서 불필요한 패턴 매칭을 피해 시간복잡도를 줄이는 알고리즘으로 KMP, BoyerMoore 알고리즘 등이 있다..!
KMP 알고리즘의 시간복잡도는
O(len(pattern) + len(text))이다!
KMP 알고리즘
KMP 알고리즘은 패턴의 전처리를 통해 LPS배열을 만들고, 불필요하게 확인하는 부분을 건너뛰는 방법이다..!
이렇게 들으면 무슨 소린지 1도 모르겠다.
prefix, suffix..., 괜히 영어로 접두사, 접미사하니까 또 뭔 말인지 모르겠고..
아무튼 설명하자면 이렇다.

패턴의 시작부터 문자를 1개씩 늘려가면서 접두사랑 접미사랑 일치하는 가장 긴 길이를 lps 배열에 저장한다.
뭐 어떻게 사용되는지는 나중에 확인하기로 하고..,
LPS 배열 만들기
그래서 LPS 배열 만드는걸 코드로 구현하면 이렇게 된다.
문자가 일치하면 앞으로 한 문자씩 더 가면서 더 확인하고,
일치하지 않으면 다시 세고..
코드
def makeLps(p, lps):
length = 0
i = 1
while i < len(p):
if p[length] == p[i]:
length += 1
lps[i] = length
i += 1
else:
if length == 0:
lps[i] = 0
i += 1
else:
length = lps[length - 1]아무튼 이렇게 LPS 배열을 만들었다면, KMP 알고리즘을 위한 준비는 끝났다.
KMP알고리즘?
KMP 알고리즘은 앞에 LPS배열에서 접두사, 접미사가 일치하는 길이를 이용해 일치구간은 확인하지 않는 알고리즘이다.
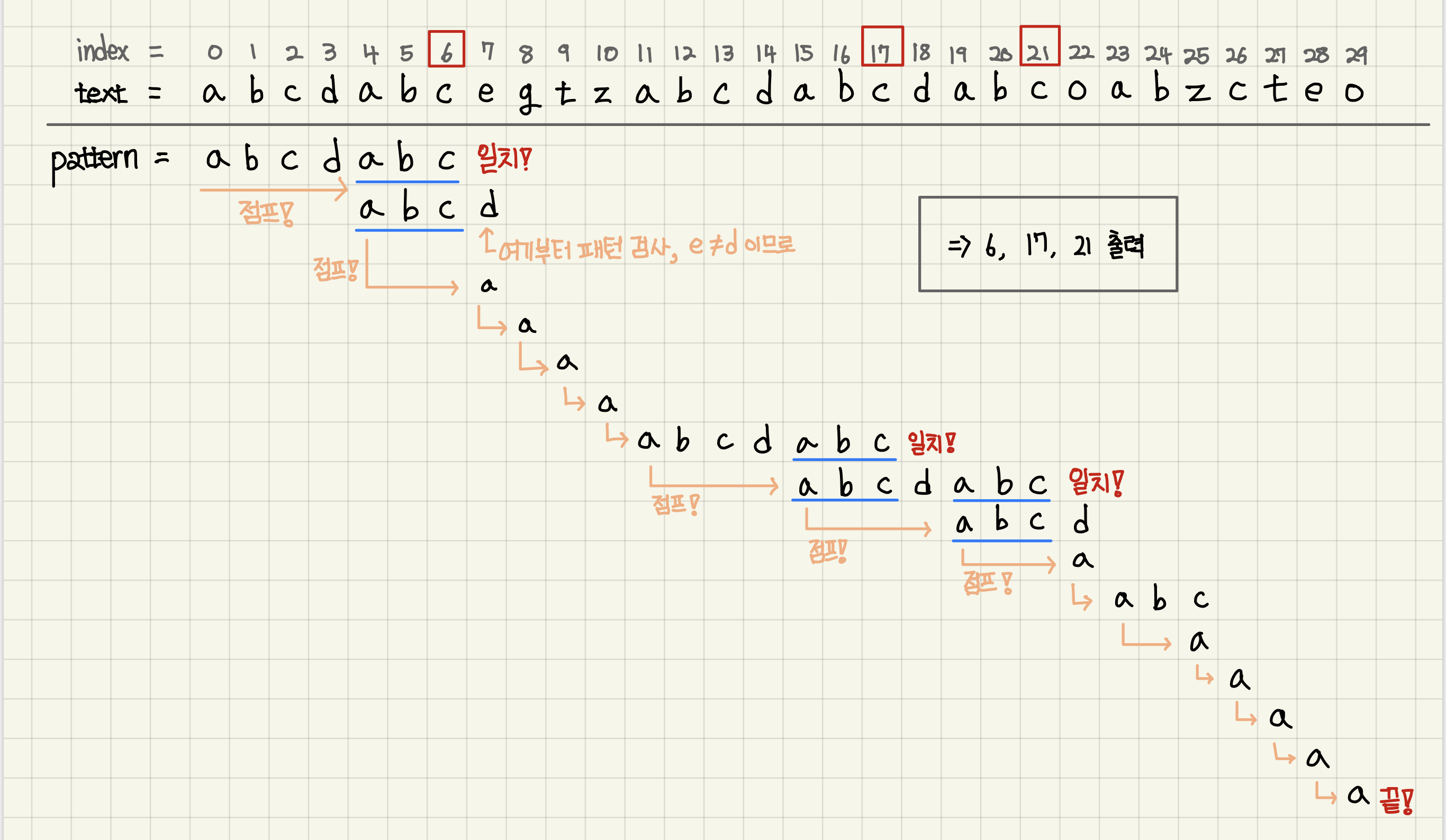
위에서 만든 lps배열을 통해 kmp알고리즘은 이렇게 움직인다.
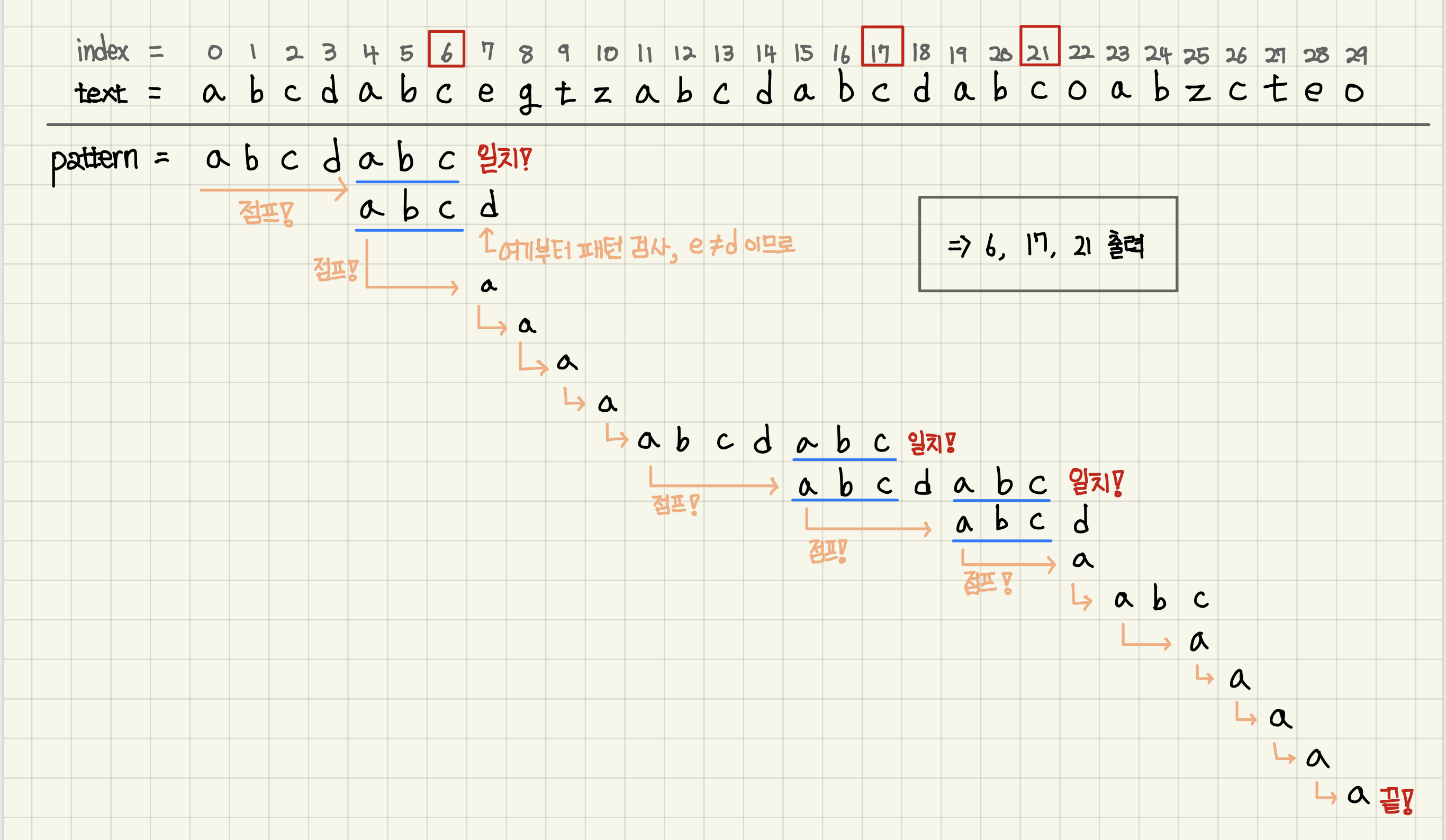
- 6번 인덱스에서 패턴 일치 이후에
lps[j-1] (j=7)이 3이므로text[7]과pattern[3]을 비교한다. text[7]과pattern[3]을 비교했을 때, 일치하지 않으므로, j의 값을lps[j-1]로 바꿔text[7]과pattern[0]을 다시 비교한다.- 이런 과정을 반복하면서 일치하는 문자열의 마지막 인덱스를 출력(반환, 삽입 등..)한다.
코드로 나타내면 이렇다
def KMP(t, p):
lt, lp = len(t), len(p)
lps = [0] * lp
makeLps(pattern, lps)
i, j = 0, 0
while i < lt:
if t[i] == p[j]:
i += 1
j += 1
else:
if j != 0:
j = lps[j-1]
else:
i += 1
if j == lp:
print(i)
j = lps[j-1]근데 사실 kmp는 별로 쓰이지 않는다고..
백준 1786번. 찾기

아래꺼가 kmp로 돌린 거다
그냥 궁금해서 BoyerMoore 알고리즘으로도 돌려봤으나 40%에서 시간초과가 나온다.
그나저나 kmp알고리즘은 무슨 단순 구현문제도 플래티넘이네... 이게 특이한건가 싶기도하고..






