이전 게시글에서 Realtional Algebra의 기본연산자 6개와 추가적인 연산자 2개에 대해서 알아보았다.
이 포스팅에서는 추가적인 연산자 5개와! 확장된 연산자 2개를 설명할 예정이다.
✚ Additional 추가적인 연산자
1. set Intersection 연산자 (∩)
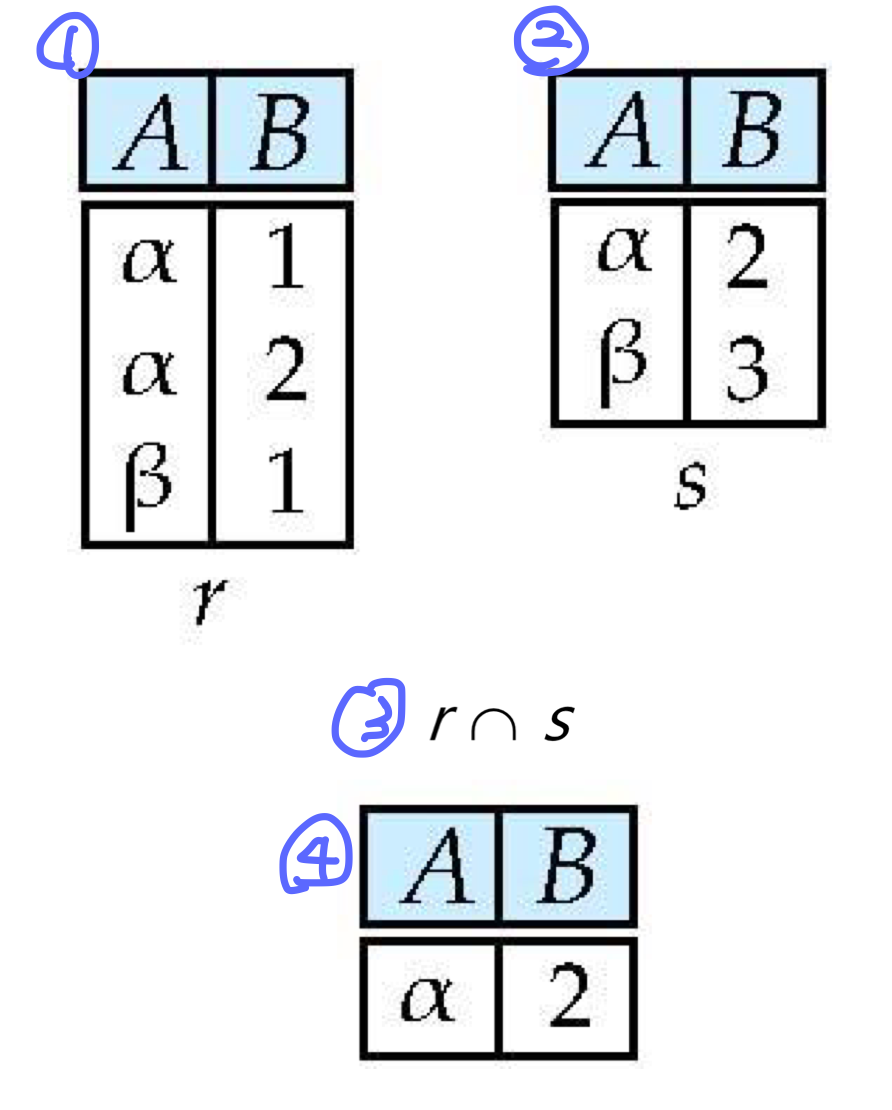
교집합 연산자이다. 1번 테이블과 2번테이블에서 공통된 튜플만 추출하는 과정이다. 따라서 1개의 튜플을 가지고 있는 4번 이 output으로 나오게 된다.
2. Natural Join 연산자 (⋈)
algebra 연산자 중 가장 까다로운 연산자라고 할 수도 있다!
Cartesian product 연산자를 사용할 때 스키마의 속성이 같다면 새로운 이름을 Remnaming 해준다고 하였는데 Natural Join 연산자를 사용한다면 같은 이름의 속성을 같은 속성이라고 판단하여 합치는 것이다.
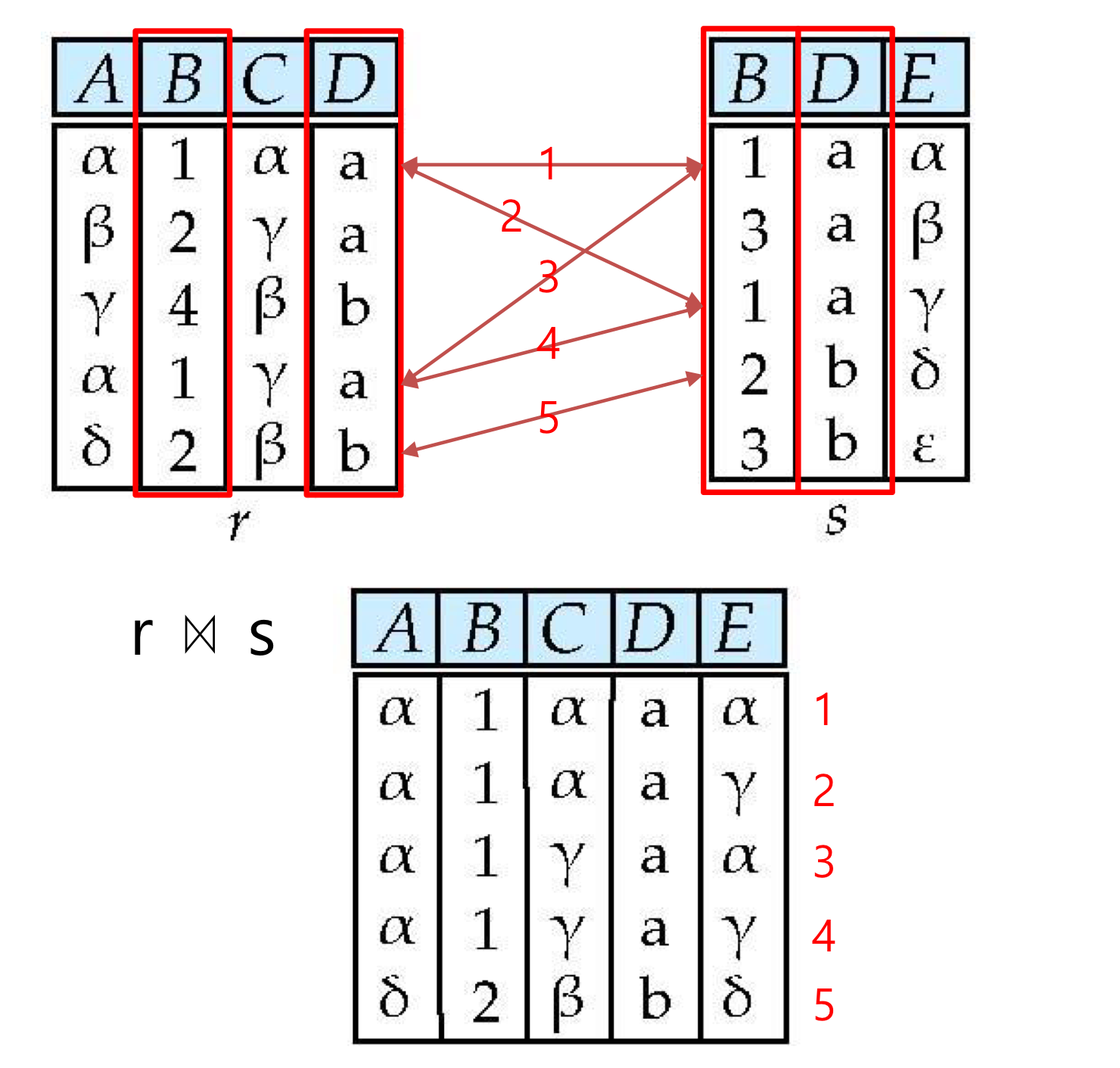
1. 피연산자의 스키마를 살펴보고 같은 속성을 찾는다.
2. 공통된 스키마가 일치하는 경우에만 튜플을 생성할 수 있다.첫번째로 r과 s의 스키마를 살펴보았을 때 같은 속성은 B와 D가 있다.
그리고 두개가 같은 값을 가지고 있는지 확인한다.
r의 맨 윗줄의 값과 s의 1,3줄의 값이 일치하기 때문에 합쳐서 하나의 튜플을 만들 수 있다. r의 두번째줄과는 s의 값들 중 일치하는게 없기 때문에 새로운 튜플을 만들지 못한다.
이처럼 반복하여 아래와 같은 테이블을 생성할 수 있고 해당 테이블이 natural join 연산자의 output이 된다.
여기서 잠깐!☝🏻 ⋈는 순서가 중요하지 않다!!
σ(dept_name = "Comp.Sci."(instructor ⋈ teaches ⋈ course )위에서 만약 ⋈ 되는 순서가 바뀌어도 결과값은 달라지지 않는다.
1+1+3 = 3+1+1 은 교환법칙이 성립되는 것과 같은 의미이다.
3.Theta Join(⋈θ)
SQL의 대부분은 세타조인이라고도 할 수 있듯이 많이 사용되고 있다.
의미는 어렵지 않은데 Cartesian product 와 Select 를 섞은 것이다.

4. Outer Join
Natural Join의 확장판인 연산자이다. Natural Join의 경우 스키마를 하나의 집합으로 만드는데 그 과정에서 속성에 해당하는 값이 같지 않다면 해당 튜플을 무시 하지만, Outer Join 에서는 같지 않아도 결과를 보여준다
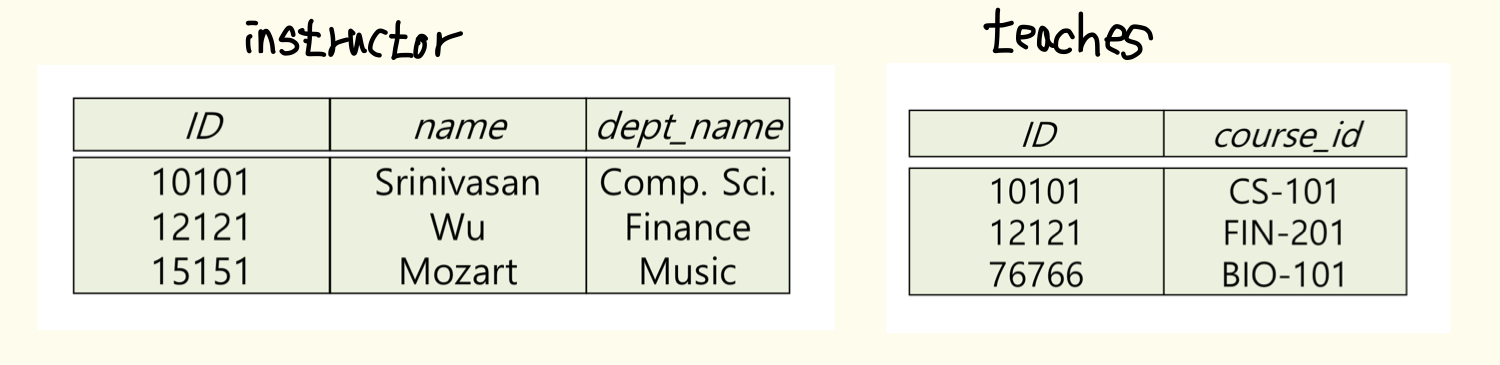
위와 같은 테이블이 2개가 있을 때, 만약 Natural Join을 하게 된다면
공통된 속성인 ID의 값이 '10101' , '12121' 인 튜플이 합쳐져 총 2개의 튜플로 구성된 테이블이 만들어질 것 이다.
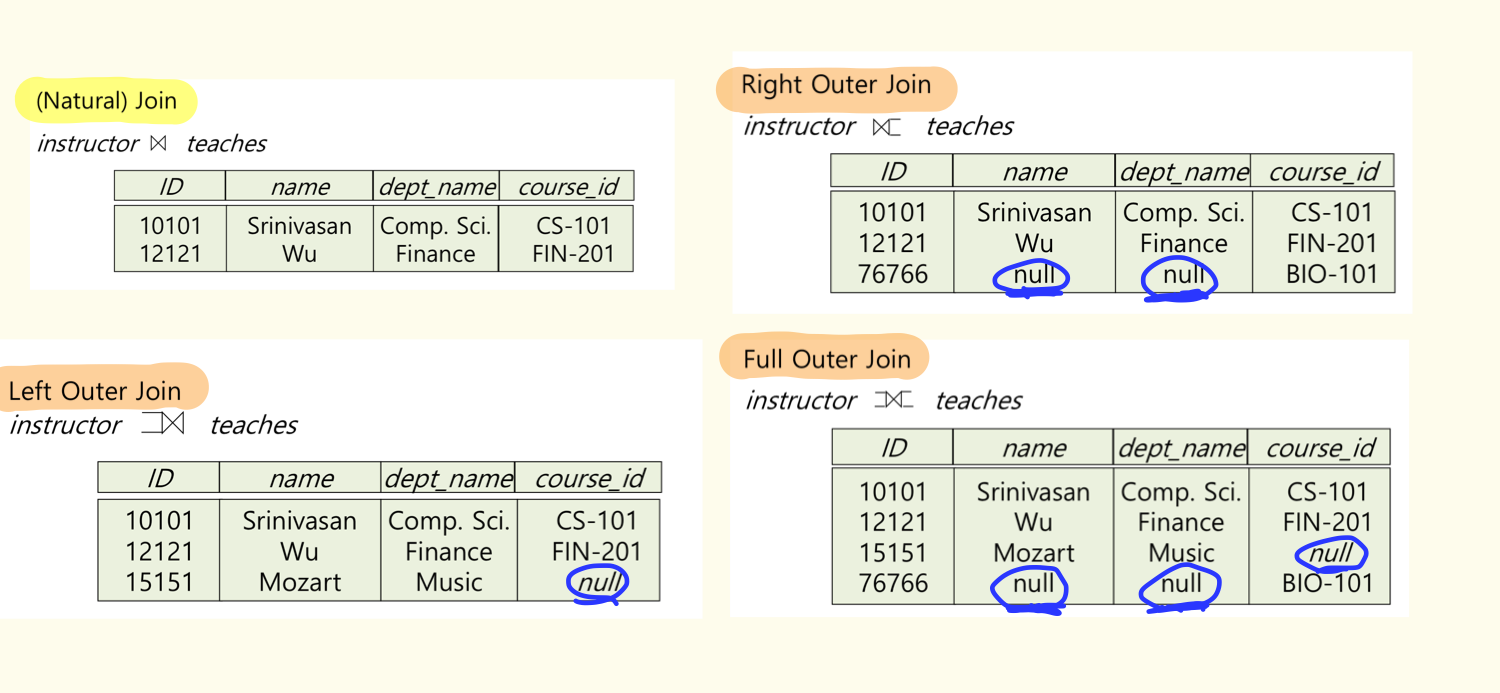
하지만 Outer Join 을 사용하면 Right Left Full 를 사용하여 왼쪽 또는 오른쪽 또는 모든 테이블의 튜플을 전부 가지고 하나의 테이블을 만들 수가 있다!
만약 속성에 해당하는 값이 존재하지 않는다면 의미를 알 수 없는 Null 값을 해당 속성의 값으로 넣어주면 된다.
🤷🏻♀️Null은 무슨 의미인가요?!
query에서 null은 알려지지 않은 값, 알 수 없는 값일 때 사용하는 값이라는 의미로 사용된다.
- Null로 산술연산을 하면?
null * 1 = null
null + 3 = null
null - 10 = null
null / 4 = null
!!!! null로 산술연산을 하면 무조건 Null이 나오게 된다.
2. Null로 비교연산을 하면?
1 < null = unknown
null >= 10 = unknown
여기서 중요한 개념이 하나 나오는데 null 을 가지고 비교연산을 하게 되면 특별한 값인 unkonown 이 나오게 된다. 원래 비교연산을 통해서는 true false 두 가지의 값만 나오게 되는데 하나의 값이 더 나오게 된다.

unknown의 논리연산은 위와 같다.
하지만
만약 select 연산을 했을 때 값이 unknown이 나온다면 해당 값은 참인지 거짓인지 알지 못하는데 그걸 참이라고 해버린다면 거짓이라고 제외했을 때보다 더 잘못된 정보이게 될 수 있어서
select연산자에서 unknown는 flase의미로 사용된다.
5.Assignment (←)
복잡하고 긴 연산을 편리하게 쓰기위해 사용되는 연산자 이다.
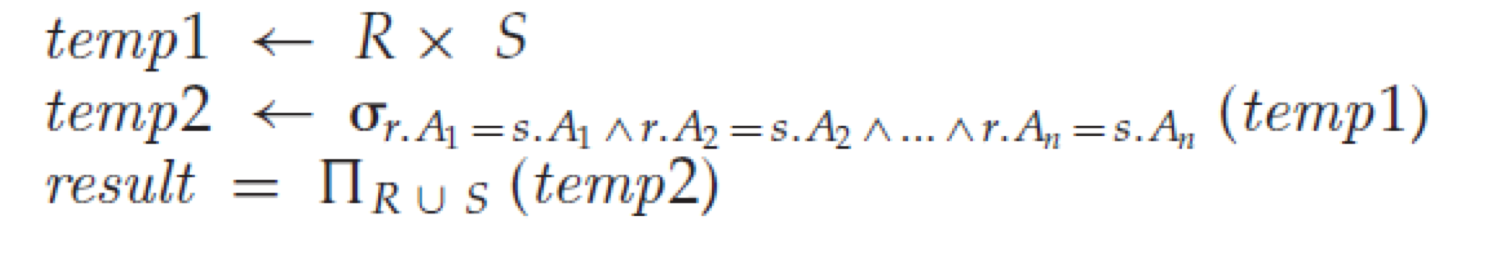
👐🏻 Extended 확장된 연산자
추가적인 연산자들은 기본적인 연산자들로 표현을 할 수 있는 연산자들이다.
하지만
기본적인 연산자로도 표현할 수 없지만 필요한 연산자들을 확장된 연산자로 지정하여 만들었다.
1. Generalized Projection
확장된 프로젝션으로 사용되는데 속성값에 산술연산을 할 수 있다
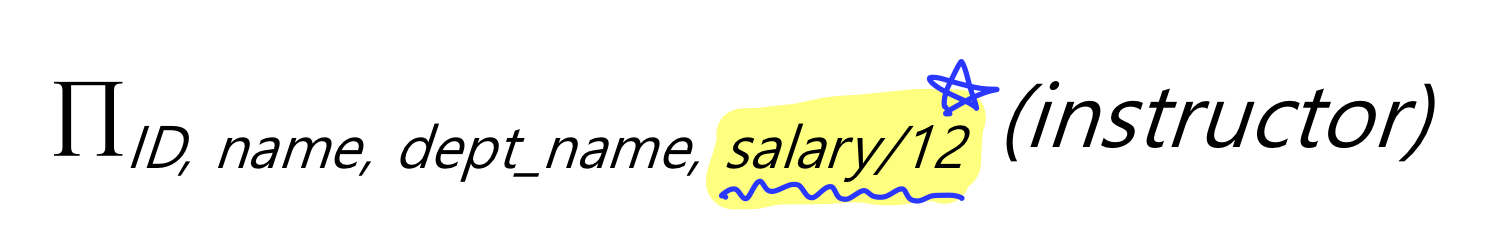
원하는 속성값을 뽑아낼 때, 산술 연산을 적용시켜서 값들을 가져올 수 있다.
2. Aggregation 집계함수
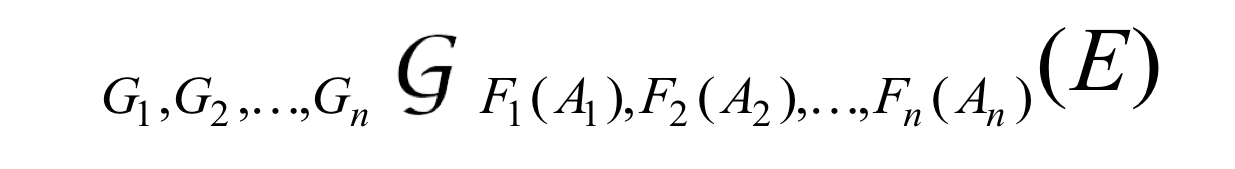
집계함수의 정의는 위와 같다.
E : Relation = table
각각의 Fi() : 집계함수
각각의 Ai : 속성이름
각각의 Gi : 그룹화(묶을) 속성의 리스트 ( 없어도 되고 있어도 됨)집계 함수의 종류에는 avg min max sum count가 있다.
이론적인 설명은 모두 마쳤으니 예를 보면서 설명하는 것이 훨씬 이야기가 잘 될 것이다!!
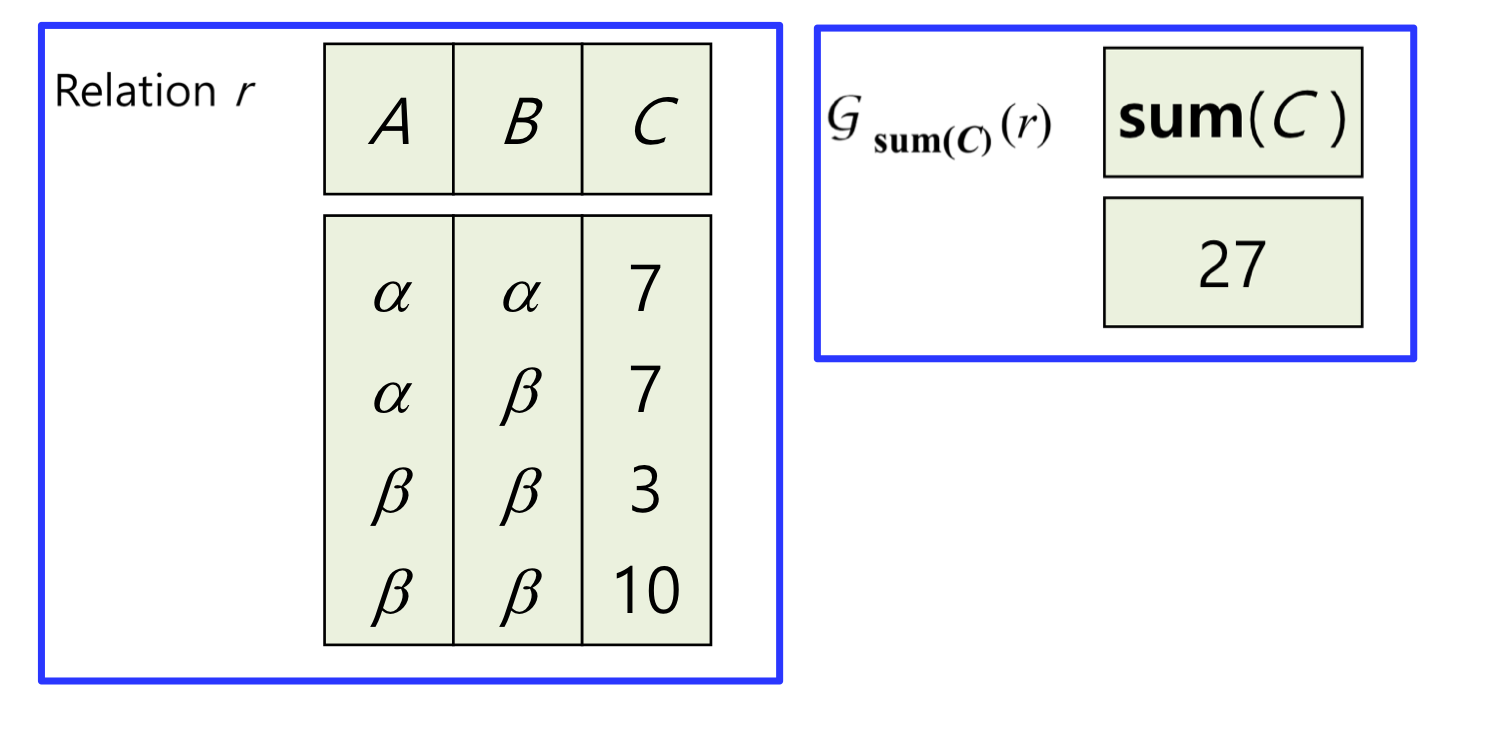
Relation r이 왼쪽일 때 그룹화를 하지않고 집계함수 sum(C)를 통해서 C의 속성들을 값들을 다 합쳐서 오른쪽과 같은 테이블을 만들 수 있다.
속성의 값은 집계함수의 이름 그대로 적용된다.
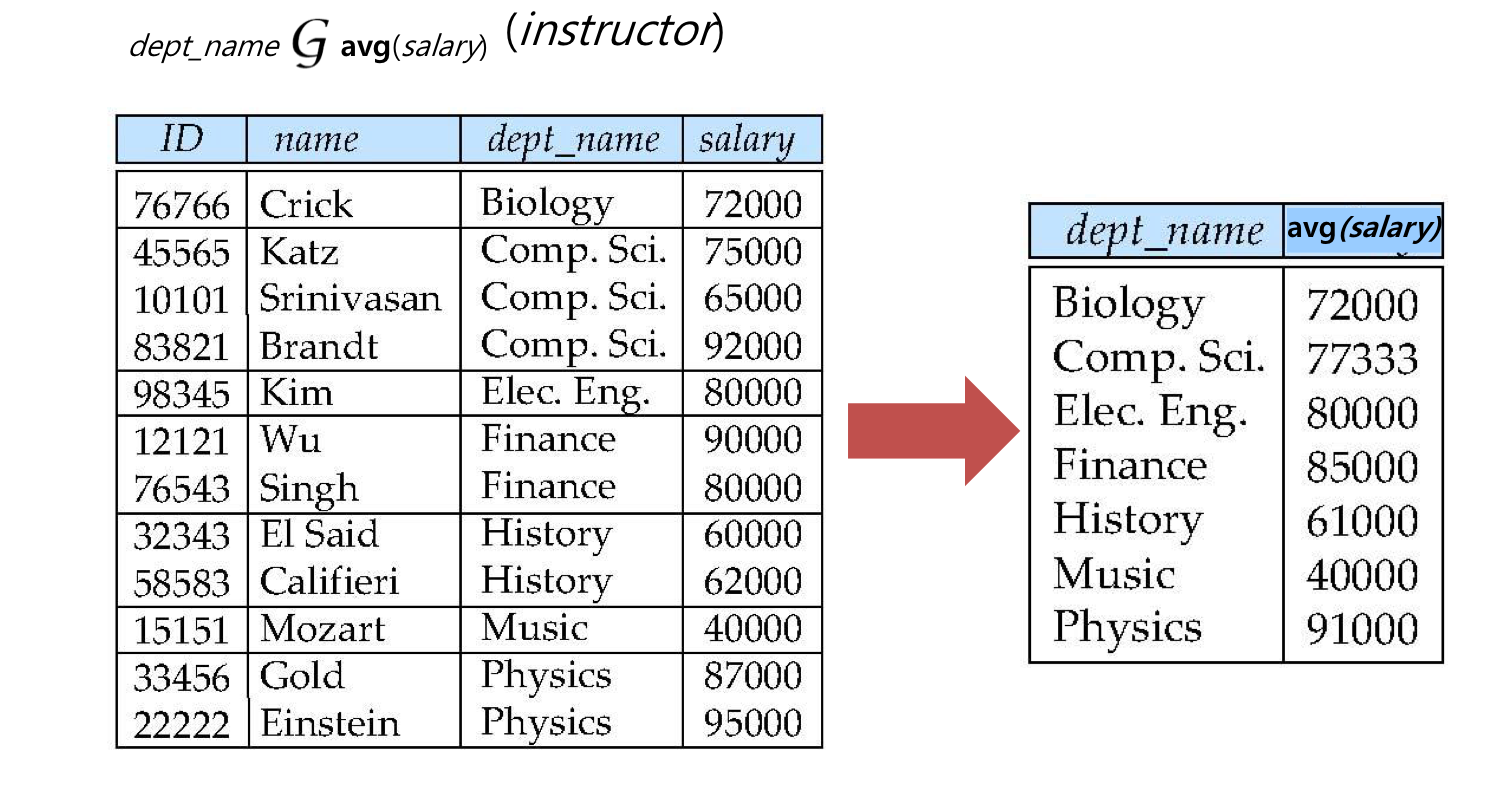
다른 예로 그룹화를 적용했었을 때는 위처럼 결과가 나온다.
dept_name을 기준으로 그룹을 묶어서 집계함수를 적용하면 된다.
위와 같은 경우는 dept_name을 기준으로 salary 속성의 평균값을 구해 하나의 테이블을 만들게 된다.
rename!

위에서는 속성의 이름을 집계함수 그대로하게 되는데 rename 연산을 통해서 속성값을 새로 지정해도 되지만 as 를 통해서 새로운 속성의 이름을 지정할 수도 있다.
distant!!
집계 함수 뒤에 distant를 적는다면 중복을 제거한다는 의미이다.
count-distinct 라고 작성한다면 중복을 제거하여 갯수를 센다는 의미로 사용된다.
위 글은 공부하며 작성한 글이므로 내용상의 오류가 있을 수 있습니다.
잘못된 부분은 덧글로 이야기 해주세요😀
