자바로 코딩테스트를 준비하다보면 ArrayList나 Stack, Queue 등을 선언해서 쓰는 것을 많이 해봤을 것이다. 하지만, 문제를 풀다보면 각 문제에 맞는 자료구조의 종류들이 많다. 그래서 이번 기회에 Java Collection Framework를 정리해볼려고 한다.
1. Java Collection Framework란?
먼저, Java Collection Framework란 자바에서 널리 알려져 있는 자료 구조(Data Structure)들을 바탕으로 객체들을 효율적으로 추가, 삭제, 검색할 수 있도록 관련된 인터페이스와 클래스들을 java.util 패키지에 포함시켜 놓은 것을 말한다.
즉, 자료 구조의 형태들을 자바 클래스로 구현한 모음집이라고 보면 된다. 더 쉽게 생각하면 자바에서 C++의 STL 역할을 한다고 생각하면 쉬울 것이다. 이 컬렉션 프레임워크를 통해 자바 개발자들은 직접 자료구조를 직접 구현할 필요없이 이들을 인스턴스화시켜서 사용만 하면 된다.
1-1. 컬렉션 프레임워크의 이점
컬렉션 프레임워크는 다음과 같은 이점을 가진다.
- List, Queue, Set, Map 등의 인터페이스를 제공하고, 이를 구현하는 클래스를 제공하여 일관된 API를 사용할 수 있다.
- 가변적인 저장 공간을 제공한다. 이는 고정적인 저장 공간을 제공하는 배열과 대비되는 특징이라고 볼 수 있다.
- 개발자 스스로 자료구조, 알고리즘 등을 구현할 필요 없이, 이미 구현된 컬렉션 클래스를 목적에 맞게 선택해서 사용하면 된다.
- 제공되는 API의 코드는 검증되었으며, 고도로 최적화되어 있다.
1-2. 구성요소
컬렉션 프레임워크는 다음과 같이 크게 3가지 요소로 구성되어 있다.
-
인터페이스(Interfaces) : 각 컬렉션을 나타내는 추상 데이터에 대한 인터페이스(List, Set, Map, Queue 등). 클래스는 이 인터페이스를 구현하는 방식으로 작성되어 있기 때문에 상세 동작은 달라도 일관된 조작법으로 사용할 수 있다.
-
클래스(Classes) : 컬렉션 별 인터페이스의 구현(Implementation). 같은 List 컬렉션이더라도 개발자의 목적에 따라 ArrayList, LinkedList 등으로 상세 구현이 달라질 수 있다.
-
알고리즘(Algorithms) : 컬렉션이 제공하는 연산, 검색, 정렬, 셔플(Shuffle) 등에 대한 메서드.
이러한 특성을 가진 자바 컬렉션 프레임워크의 계층도는 아래와 같다.
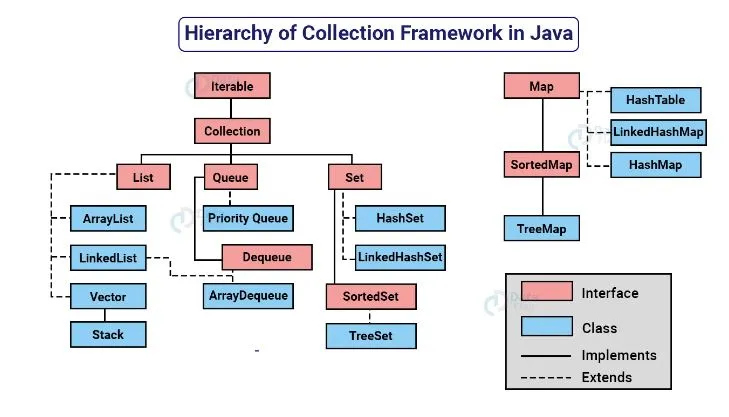
사실 컬렉션 프레임워크를 구성하는 인터페이스와 클래스의 종류는 정말 많다. 그래서 나는 코딩테스트에 주로 나오는 것들로 정리하고자 한다. 크게 List, Queue, Set, Map 인터페이스로 구성되어 있다고 생각하면 쉽다.
2. 배열, ArrayList
배열 (Array)
배열은 처음 선언할 때 크기가 결정된다. 즉, 크기가 정적이다. 만약 문제에서 데이터의 개수를 정확히 알 수 있다면 코드가 더 간결하고 속도가 더 빠른 배열을 사용하면 된다.
int[] arr1 = {1, 2, 4, 5, 3}; // 1차원 배열 선언 + 생성 + 초기화
int[] arr2 = new int[5]; // new 연산자를 사용해 배열 선언 후 생성
int[][] arr3 = {{1, 2, 3}, {4, 5, 6}}; // 2차원 배열 생성 (2행 3열)
System.out.println(arr[1][2]); // 6
// arr[1][2]에 저장된 값을 7로 변경
arr[1][2] = 7;
// 변경된 값을 출력
System.out.println(arr[1][2]); // 7
System.out.println(arr1.length); // arr1 배열의 전체 데이터 개수를 리턴 : 5
Arrays.sort(arr1); // arr1 배열의 모든 데이터 정렬하는 Arrays 클래스의 sort() 메서드 : [1, 2, 3, 4, 5]
System.out.println(Arrays.toString(arr1));
// 배열의 모든 데이터를 String으로 변환하는 Arrays 클래스의 toString() 메서드: [1, 2, 3, 4, 5]
ArrayList
자바에서 크기가 동적으로 변경되는 배열이 필요할 때는 ArrayList를 활용하면 된다. 실제로 코딩테스트 문제를 풀다보면 많이 활용된다.
List<String> list = new ArrayList<>();
List<String> list2 = new ArrayList<>();
// 요소 삽입
list.add("one");
// 특정 인덱스에 요소 삽입
list.add(0, "zero");
// 리스트 병합 (추가되는 리스트가 뒤로 온다)
list.addAll(list2);
// 특정 요소의 첫번째 인덱스 반환
list.indexOf("zero");
// 특정 요소의 마지막 인덱스 반환
list.lastIndexOf("zero");
// 특정 인덱스의 값 삭제
list.remove(0);
// 첫 번째 값 삭제
list.remove("one");
// 리스트 차집합
list.removeAll(list2);
// 리스트 교집합
list.retainAll(list2);
// 리스트 비우기
list.clear();
// 리스트 비어있는지 체크
list.isEmpty();
// 리스트 길이
list.size();
// 리스트 특정 요소 포함여부 체크
list.contains("one");
// 리스트에 다른 리스트 요소가 전부 포함되어 있는지 여부 체크
list.containsALL(list2);
// 람다식 사용하여 요소를 제거
list.removeIf(x -> x % 2 == 0) // list 에서 짝수인 수를 모두 제거
Array to List / List to Array / 배열 ↔ 리스트
프로그래머스 문제를 풀 때 많이 사용하는 패턴이다. 프로그래머스는 백준과 달리 리턴 값의 형태가 중요하기 때문에 이에 주의해 알고리즘을 구현해야 한다.
// 문자열 타입 배열을 List로 변환
String[] temp = {"apple", "banana", "lemon"};
List<String> list = new ArrayList<>(Arrays.asList(temp));
// List를 문자열 배열로 변환
List<String> list = new ArrayList<>();
String[] temp = list.toArray(new String[list.size()]);
// 정수 배열을 List로 변환
int[] temp = {1, 2, 3, 4};
List<Integer> list = new ArrayList<>(Arrays.asList(temp));
// List를 정수 배열로 변환
List<Integer> list = new ArrayList<>();
int[] temp = list.stream().mapToInt(x -> x).toArray();Collections 관련 메서드
int[] temp = {1, 2, 3, 10, 20};
List<Integer> list = new ArrayList<>(Arrays.asList(arr));
// 정수형 List 원소 중 최대, 최소값
Collections.max(list);
Collections.min(list);
// List 정렬
Collections.sort(list); // 오름차순 (ASC)
Collections.sort(list, Collections.reverseOrder()); // 내림차순 (DESC)
// List 뒤집기
Collections.reverse(list);
// List 내 원소의 개수 반환
Collections.frequency(list, 3);
// List 내 원소를 이진탐색을 이용해 찾기
Collections.binarySearch(list, 10); // 3
3. 스택 (Stack)
스택은 제일 나중에 넣은 데이터를 먼저 꺼낼 수 있는 자료구조이다. 즉, LIFO(Last In First Out)의 특성을 가진다.
Stack<Integer> stack = new Stack<>();
// 요소 추가
stack.push(1);
// 요소 제거 (꺼내기)
stack.pop();
// 스택 비우기
stack.clear();
// 스택 크기 체크
stack.size();
// 스택이 비어있는지 유무 확인
stack.empty();
// 스택에 요소가 존재하는지 확인
stack.contains(1);
// 스택 최상단 요소 확인. pop()과 다름
stack.peek();4. Queue (큐)
큐(Queue)는 먼저 들어간 데이터가 먼저 나오는 자료구조이다. 즉, 선입선출 또는 FIFO(First In First Out)의 특징을 가진다.
Queue<Integer> queue = new LinkedList<>();
// 큐에 요소 추가 (enqueue)
queue.add(1); // 문제 상황에서 예외 발생
queue.offer(2); // 문제 상황에서 false 리턴
// 큐에서 요소 제거 (dequeue)
queue.remove(); // 문제 상황에서 예외 발생
queue.pool(); // 문제 상황에서 null 리턴
// 큐 비우기
queue.clear();
// 큐의 최전방 요소 확인
queue.element(); // 문제 상황에서 예외 발생
queue.peek(); // 문제 상황에서 null 리턴 ArrayDeque
자바에서 제공하는 양방항 큐 (Double-ended queue) 구현체를 ArrayDeque라고 한다. Deque 인터페이스를 상속 받는다. 스택이나 큐로 사용하기에 적합하며, 동적 배열을 기반으로 하여 효율적인 성능을 제공한다.
1. 양방향 큐 : 앞쪽과 뒤쪽 모두에서 삽입과 삭제가 가능하다.
2. 빠른 성능 : ArrayDeque는 연결 리스트 기반의 LinkedList 보다 더 빠른 성능을 제공하는 경우가 많다.
3. 크기 제한 없음 : 내부 배열은 필요에 따라 자동으로 크기 조정
4. 단일 스레드 환경에서 사용해야 한다.
ArrayDeque<Integer> deque = new ArrayDeque<>();
// 삽입 메서드
deque.addFirst(10); // [10]
deque.addLast(20); // [10, 20]
deque.offerFirst(5); // [5, 10, 20]
deque.offerLast(25); // [5, 10, 20, 25]
// 삭제 메서드
deque.removeFirst(); // 제거: 5 → [10, 20, 25]
deque.removeLast(); // 제거: 25 → [10, 20]
deque.pollFirst(); // 제거: 10 → [20]
deque.pollLast(); // 제거: 20 → []
// 조회 메서드
deque.addLast(30); // [30]
deque.addLast(40); // [30, 40]
deque.getFirst(); // 반환: 30
deque.getLast(); // 반환: 40
deque.peekFirst(); // 반환: 30
deque.peekLast(); // 반환: 40
// 기타 메서드
deque.size(); // 반환: 2
deque.contains(30); // 반환: true
deque.isEmpty(); // 반환: false
deque.clear(); // [ ]
deque.isEmpty(); // 반환: true
deque.addLast(50); // [50]
deque.addLast(60); // [50, 60]
Object[] array = deque.toArray(); // [50, 60]
- 여기서
peek()은 맨 앞(혹은 맨 뒤) 요소를 반환만 하고 제거하지 않는다. - 반대로,
poll()은 맨 앞 (혹은 맨 뒤) 요소를 반환 후 제거한다.
ArrayDeque<Integer> deque = new ArrayDeque<>();
deque.addLast(10);
deque.addLast(20);
// peekFirst(): 앞 요소 반환 (제거x)
System.out.println(deque.peekFirst()); // 10
System.out.println(deque); // 10 20
// pollFirst(): 앞 요소 반환 후 제거
System.out.println(deque.pollFirst()); // 10
System.out.println(deque); // 20 LinkedList (연결 리스트)
LinkedList는 List 인터페이스와 Deque 인터페이스를 모두 구현하는 클래스이다. 즉, List 인터페이스와 Deque 인터페이스의 메서드를 모두 지원한다. 순차 저장과 삽입/삭제가 빠른 특징이 있다.
- 앞/뒤 추가/삭제는 O(1)
- 중간 접근/삭제/검색은 O(n)**
// LinkedList 선언
LinkedList<Integer> list = new LinkedList<>();
// 요소 추가 (List 메서드)
list.add(10); // [10]
list.add(1, 20); // [10, 20]
list.add(30); // [10, 20, 30]
// 요소 접근 및 수정
list.get(1); // 반환: 20
list.set(1, 25); // [10, 25, 30]
// 요소 삭제
list.remove(1); // 제거: 25 → [10, 30]
list.removeFirst(); // 제거: 10 → [30]
list.removeLast(); // 제거: 30 → []
// 앞/뒤 삽입 (Deque 메서드)
list.addFirst(5); // [5]
list.addLast(15); // [5, 15]
list.offerFirst(1); // [1, 5, 15]
list.offerLast(20); // [1, 5, 15, 20]
// 앞/뒤 요소 확인
list.getFirst(); // 반환: 1
list.getLast(); // 반환: 20
list.peekFirst(); // 반환: 1
list.peekLast(); // 반환: 20
// 앞/뒤 요소 제거
list.pollFirst(); // 제거 및 반환: 1 → [5, 15, 20]
list.pollLast(); // 제거 및 반환: 20 → [5, 15]
// 기타 메서드
list.size(); // 반환: 2
list.contains(15); // 반환: true
list.isEmpty(); // 반환: false
list.toArray(); // 배열로 변환: [5, 15]
list.clear(); // 모두 제거
list.isEmpty(); // 반환: truePriorityQueue (우선순위 큐)
우선순위 큐(PriorityQueue)는 Queue 인터페이스의 구현체 중 하나이다. 요소를 저장할 때 자동으로 우선순위를 부여하고, 요소를 꺼낼 때 우선순위가 가장 높은 요소부터 반환한다.
- 내부적으로 Heap(이진 트리) 구조를 사용해 효율적인 삽입/삭제 (O(log n))를 지원한다.
- 기본적으로 Comparable에 따라 우선순위를 매기며, Comparator를 지정하면 사용자 정의 하에 우선순위로 동작이 가능하다.
// 선언 (기본: 오름차순 정렬)
PriorityQueue<Integer> pq = new PriorityQueue<>();
// 요소 추가
pq.add(30); // [30]
pq.offer(10); // [10, 30]
pq.add(20); // [10, 30, 20]
// 우선순위 가장 높은 요소 조회 (제거X)
pq.peek(); // 반환: 10
// 우선순위 가장 높은 요소 제거 (제거O)
pq.poll(); // 제거: 10 → [20, 30]
// 가장 높은 요소 제거 (예외 발생 가능)
pq.remove(); // 제거: 20 → [30]
// 특정 요소 포함 여부 확인
pq.contains(30); // 반환: true
// 크기 확인
pq.size(); // 반환: 1
// 비어있는지 확인
pq.isEmpty(); // 반환: false
// 배열로 변환
Object[] arr = pq.toArray(); // [30]
// 모든 요소 제거
pq.clear(); // []
// Comparator를 사용한 내림차순 우선순위 큐
PriorityQueue<Integer> pqDesc = new PriorityQueue<>(Comparator.reverseOrder());
pqDesc.add(3); // [3]
pqDesc.add(1); // [3, 1]
pqDesc.add(2); // [3, 1, 2]
pqDesc.peek(); // 반환: 3
5. HashMap(해시맵), HashSet(해시셋)
HashMap
Map 인터페이스의 구현체이다(Map<K, V>). <key, value> 쌍의 특징을 가지고, value만 중복을 허용한다. 또한, null 허용과 관련해 key는 1개, value는 여러 개 가능하다. 또한, 순서를 보장하지 않는다. 해시 테이블을 기반으로 하여 평균 O(1)에 가까운 접근 시간을 제공해 주로 검색에 많이 쓰인다.
HashMap<Integer, String> hashMap = new HashMap<>();
// 요소 추가
hashMap.put(1, "딸기");
hashMap.put(2, "바나나");
hashMap.put(1, "사과"); // (1. "딸기")의 value가 "사과"로 대체됨
// 키에 해당하는 값 조회
hashMap.get(1);
hashMap.get(2);
// 키에 해당하는 값이 없으면 null을 반환한다.
hashMap.get(3);
// null 대신 기본 값을 반환할 수 있는 getOrDefault() 메서드
System.out.println(map.getOrDefault(1, "default value1")); // 1
System.out.println(map.getOrDefault(2, "defalut value2")); // 2
System.out.println(map.getOrDefault(3, "default value3")); // default value3
// 요소 삭제
hashMap.remove(1); // key가 1인 요소 삭제
// 전체 삭제
hashMap.clear();
// key 포함 여부 확인
hashMap.containsKey(1);
// value 포함 여부 확인
hashMap.containsValue("사과");
// key - value 출력
for (Integer key : hashMap.keySet()) {
System.out.prinlnt(key + " " + hashMap.get(key));
}
for (Entry<Integer, String> temp : hashMap.entrySet()) {
System.out.println(temp.getKey() + " " + temp.getValue());
}
HashSet
Set 인터페이스의 구현체이다(Set<E>). HashSet은 Key값만 저장하지만 HashMap과 달리 중복을 허용하지 않는다. 1개의 null 값을 허용하고, HashMap과 마찬가지로 순서를 보장하지 않는다. 내부적으로 HashMap을 사용하고, value는 dummy object이다. HashMap과 같이 평균적으로 O(1)에 가까운 검색 성능을 보장한다.
HashSet<Integer> hashSet = new HashSet<>();
HashSet<Integer> hashSet2 = new HashSet<>();
// 요소 추가
hashSet.add(1);
// 요소 삭제
hashSet.remove(1); // 값이 1인 요소 삭제
// 차집합
hashSet.removeAll(hashSet2);
// 교집합
hashSet.retainAll(hashSet2);
// 데이터 초기화
hashSet.clear();
// hashSet 사이즈 확인
hashSet.size();
// 특정 요소 포함 여부 확인
hashSet.contains(1);
// 요소 전체 출력
// Iterator 사용
Iterator tempIterator = hashSet.iterator();
while (tempIterator.hasNext()) {
System.out.println(tempIterator.next());
}
// for-each문 사용
for (String item : hashSet) {
System.out.println(item);
}이렇게 정리를 끝마쳤다. 사실, 컬렉션 프레임워크 종류가 워낙 방대하고, 내가 못 다룬 부분도 분명 있을 테지만 대부분 여기에 다룬 것 같다. 정리한다고 여러 블로그, 책, GPT를 참고해서 노션에 정리했지만 사실 귀찮아서(?) 미루고 또 미뤘지만 결국 정리에 성공했다....(정리하느라 너무 힘들긴 했다...ㅋㅋㅋ) 분명 틀린 부분도 있을텐데 계속 보면서 수정해야 할 것 같다. 자바 코딩테스트 공부에 도움이 되면 좋겠다!
참고
