1.select last_name, employee_id, manager_id
2 from employees;
숨겨진 테이블컬럼(관리자데이터)
employee m_id = mgr employee_id
자체참조의 첫값은 null값이다.
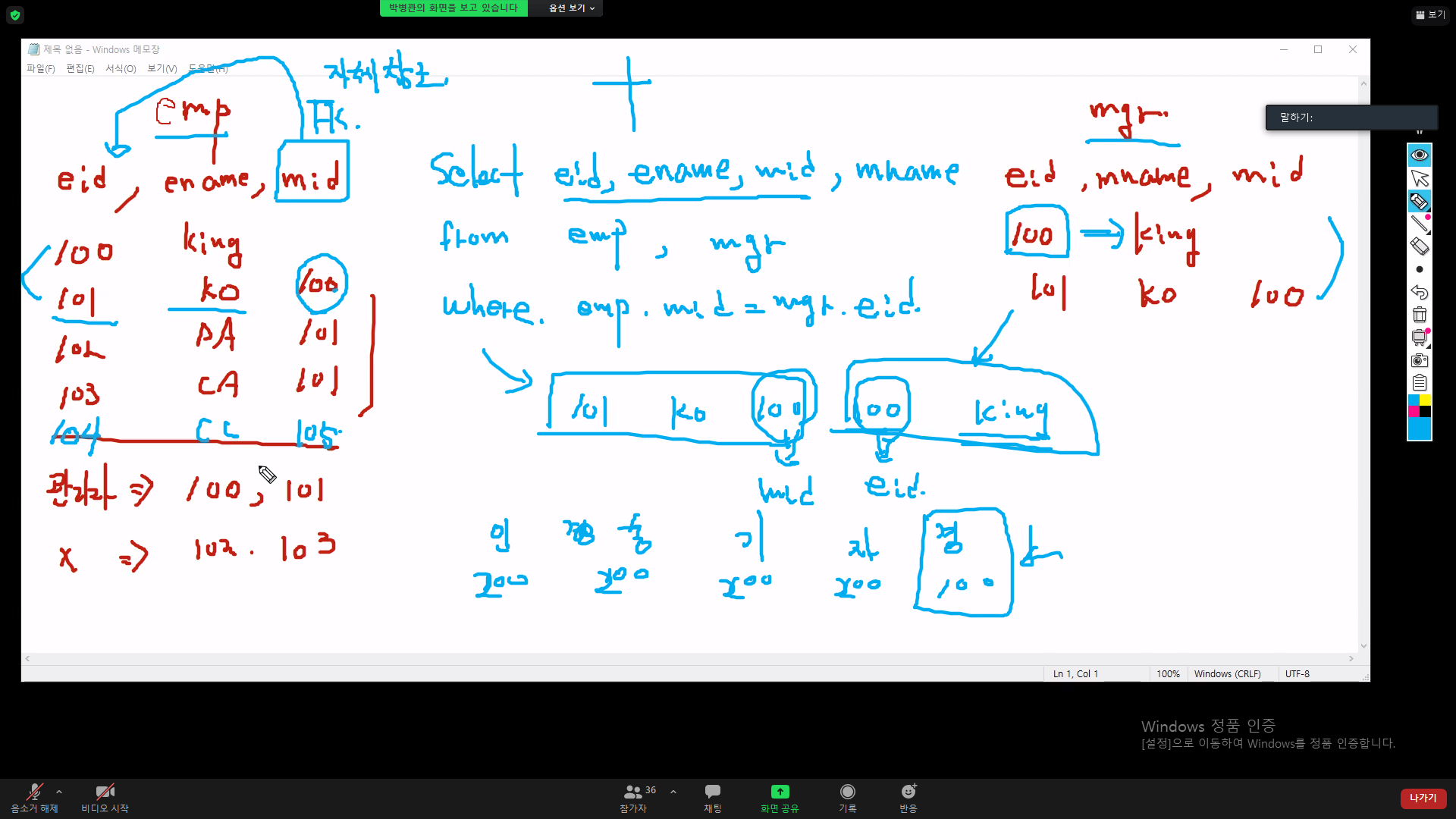
- select e.employee_id, e.last_name, e.manager_id, m.last_name
from employees e, employees m
where e.manager_id=m.employee_id
무조건 1개의 결과를 출력=함수
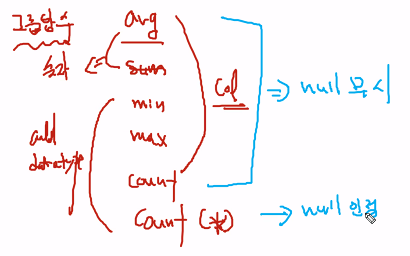
그룹함수 avg,sum,min,max
-함수를 이용할수있다(숫자o, 문자와날짜x)
avg,sum
select avg(salary), sum(salary)
2 from employees;
min,max는 숫자,문자,날짜를 전부사용할수있다.
count (clo) ->data기준
count (*) -> 행기준
그룹함수가 사용하는 두가지옵션
-all (언제나 포함되어있다)
-distinct
select distinct count(department_id)
from employees
괄호안에 디스트인크가 없으면 이미 출력된106이라는 숫자를 중복제거하기때문에 중복된게없어서 106이나온다.
그룹함수는 null값을 무시한다.
함수안에 함수가 포함한함수 - 중첩함수
select avg(nvl(commission_pct,0))
새로운 절 (where절과 order by절 사이에 명시한다.)
group by -> 그룹함수 사용시 그룹당 한개의 결과 ->그룹화 되지않은 컬럼의 data를 그룹화시켜주는 절
select a,b,c,sum(d)
group by a,b,c
count,sum앞에있는 a,b,c컬럼들은 그룹화를 꼭 시켜주어야한다.
where절은 행 에대한 조건 (우선실행)
avg,sum 그룹함수가 들어가있으면 실행불가
having은 그룹에대한 조건 (그룹by,그룹함수실행후)
무조건 그룹함수가 들어온다.
해빙은 웨어절과 오더바이절사이에 똑같이들어간다.
select distinct * column alias
from
where
group by
having
order by
1.각각의 절들이 어떤상황에 쓰이는지
1.select -> 출력(결과)
1.distinct - 1번만사용, 셀렉바로뒤, 뒤에모든컬럼영향, 중복제거,
1. * - all column
1. alias 컬럼다음위치 1개의 컬럼당1개의 1알리아스 3가지표시 에즈 공백 쌍따옴표
2.from 테이블명시, 여러개의 테이블 가져오는현상 =조인 n-1조인조건은 where절에 명시
똑같은 이름 column명시시 소유주를 정해주어야한다 from alias 많이씀
조인조건 1. equi - 데이터가 같게(pk,fk연결), non-equi - 데이터가 다를때, outer(어느한쪽에 더많을때사용 (+)삽입)
3.where
1.조건식명시(col 연산자 값)
2.값 명시 문자/날짜 ''
3.값 명시 테이블 저장된형식 그대로
1)단일비교 -> >,>=, <> 한개값비교
2)between A and B - 사이값(범위)
in - 복수연산자(똑같은 여러개 값)
like - 일부만 알때 %(문장전체),_(문자하나)
is null - null값을 찾을때
조건추가시
and-두가지 조건을 만족할때
or-둘중에 하나만 만족할때
- 그룹함수 - 그룹당 하나로 만들어줄때
avg , sum , min, max, count, count(*)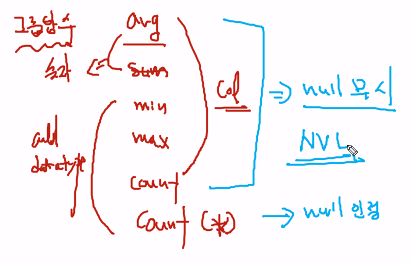
소그룹 제어 - 그룹화 되지않은 column 명시, 그룹화 작업을 해주어야함
5.having - group by절에서 그룹이 명시가 되어야 쓸수있다.(같이쓰인다.) 조건문을 쓸때쓴다
6.order by - 정렬을 할 col 1.ASC 디폴트(생략가능) 2.DESC 내림차순
nvl null값을 치환

