머신러닝 3가지 방법
지도, 비지도, 강화
지도
과대적합
훈련데이터 특징/특성을 과하게 알려줘서 실전에 대해서 제대로 맞추지 못함(성능이 떨어짐)
(=모델을 훈련데이터에 과하게 맞추면)
과소적합
훈련데이터의 특징/특성이 부족하면 실전에 대해서 제대로 맞추지 못하는것
실전데이터를 충분히 넣어서 결과를 확인할때 과대적합이냐 과소적합이냐?
-> 그순간에는 훈련데이터로 받아들이고 결과를 보여준다. 문제가 생긴다면 실전데이터 자체문제
KNN(데이터 포인터들간의 거리계산(가까운것으로))
참고하는 갯수 제한 하이퍼파라미터(n_neighbors=1) (=k값)
k값이 작으면 => 복잡 => 과대적합
k값이 많으면 => 느슨 => 과소적합
비지도 학습(Unsupervised Learning)
(= 지도학습이랑 반대 ({fit}지도학습은 문제와 답이 있다))

1. 데이터에 대한 답(Label)이 없는상태 (=문제만 있는 경우)
2. 데이터의 숨겨진 특징, 구조, 패턴을 파악(=답을 구하는게 아니기 때문에)

강화학습(Reinforcement Learning)
(= 애완동물 훈련 앉아)

1. 지도학습과 비슷함(문제와 답이 존재) 하지만 완전한 답을 제공하진 않는다.
2. 더많은 보상을 얻을 수 있는 방향으로 행동을 학습(= 애완동물 훈련 앉아)
3. 주로 게임, 로봇 학습 많이사용
머신러닝의 과정

1. Problem Identification(문제정의(=타이타닉 생존자를 알고싶다!))
2. Data Collect(데이터 수집)
3. Data Preprocessing(데이터 전처리(=가공))
4. EDA(탐색적 데이터 분석) - 가공 후 몰랐던 특징,특성 파악가능
5. Model 선택, Hyper Parameter조정
6. Traning(학습)
7. Evaluation(평가) - 유의미한 결과를 얻을때까지
1.Problem Identification(문제정의)

2.Data Collect(데이터 수집)

3.Data Preprocessing(데이터 전처리)

4.EDA(탐색적 데이터분석)

5.Model 선택, Hyper Parameter조정

6.Model Training(학습)

7.Evaluation(평가)

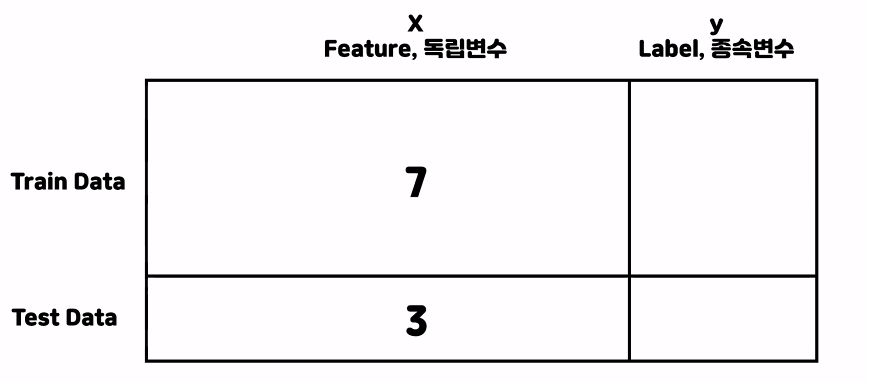
전체데이터에 7:3으로 배분해서 훈련과 테스트를 통해 훈련한다
전체데이터로 훈련을 하면 테스트는 전부 맞출수있다.
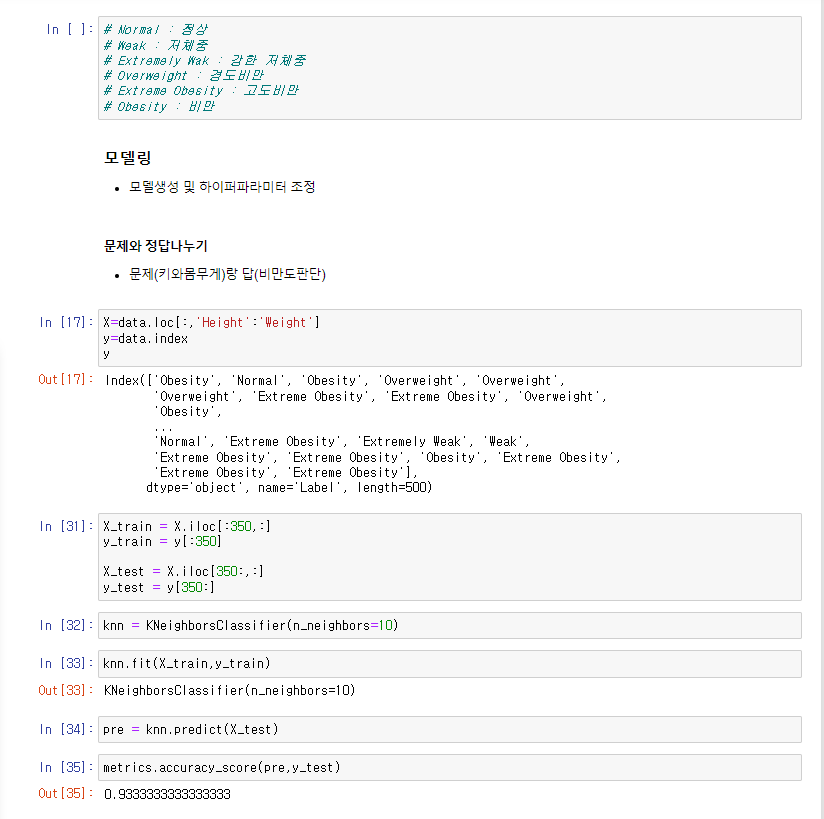
bmi_500 데이터가지고 문제해결


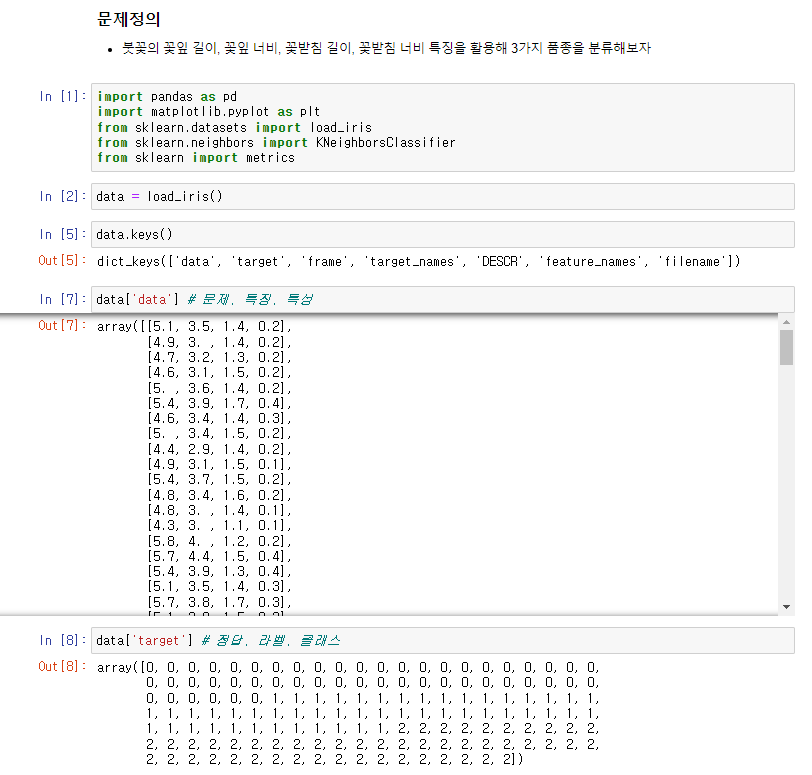
iris품종 분류

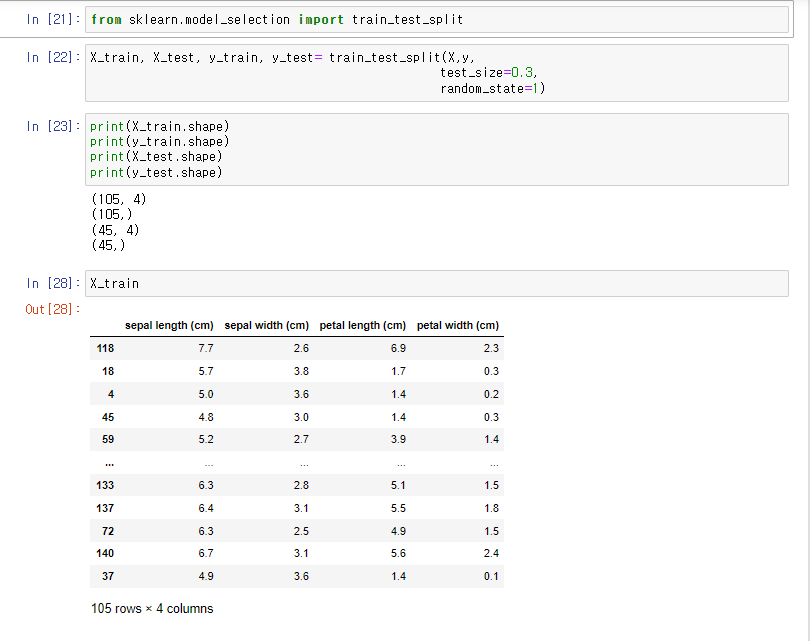
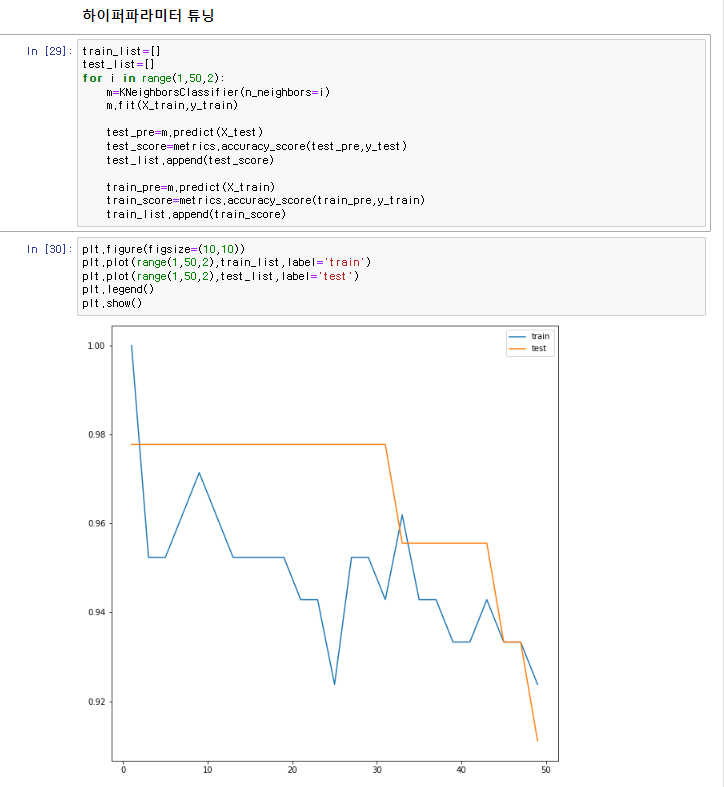
그래프 해석
일반화 = train데이터보다 test데이터가 정확도가 더 높아야하고 그 수치가 차이가 많이 안날때
train데이터가 test데이터보다 정확도가 더높을때 과대적합
train데이터와 test데이터 둘다 정확도가 낮을때 과소적합
