DDL - 구조를 가지고 있는 -> 객체
객체)

뷰 - data 액세스 제한
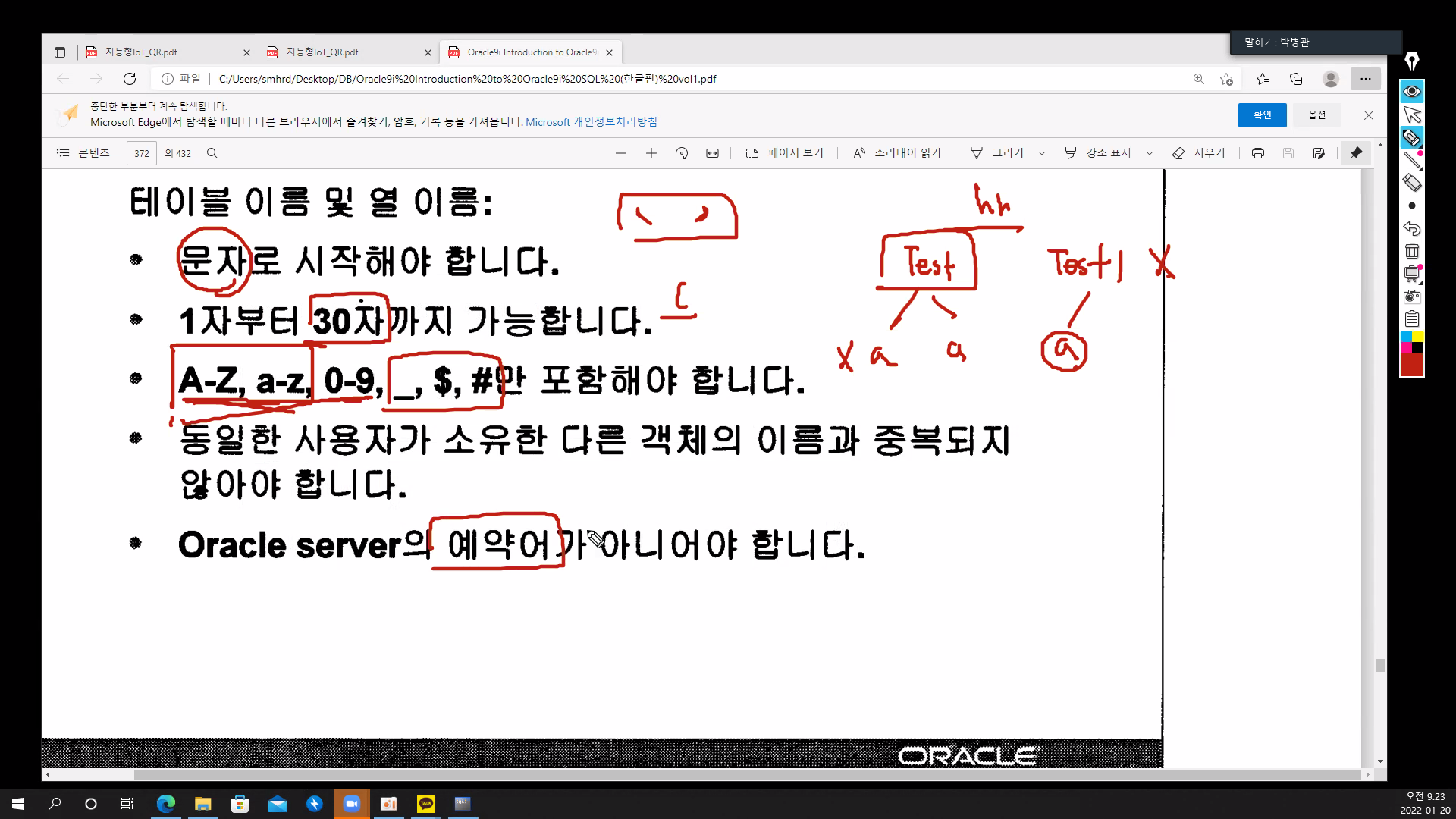
테이블 생성 (정확한 네이밍)
1. 테이블 이름
2. 컬럼(열) 이름
3. 컬럼 데이터 타입(유형),크기 확인후 값
예약어 -> 명령문 (select, from, where ...)
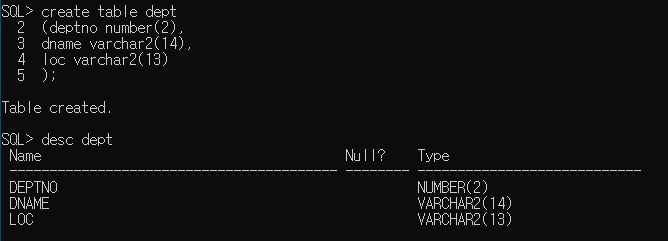
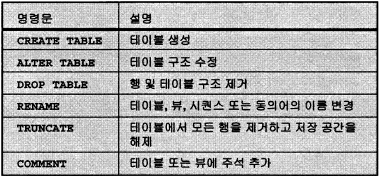
- 테이블 생성 - create
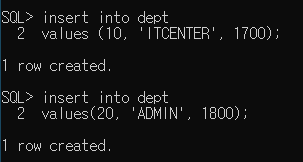
- 데이터 삽입 - insert
- 저장 - commit

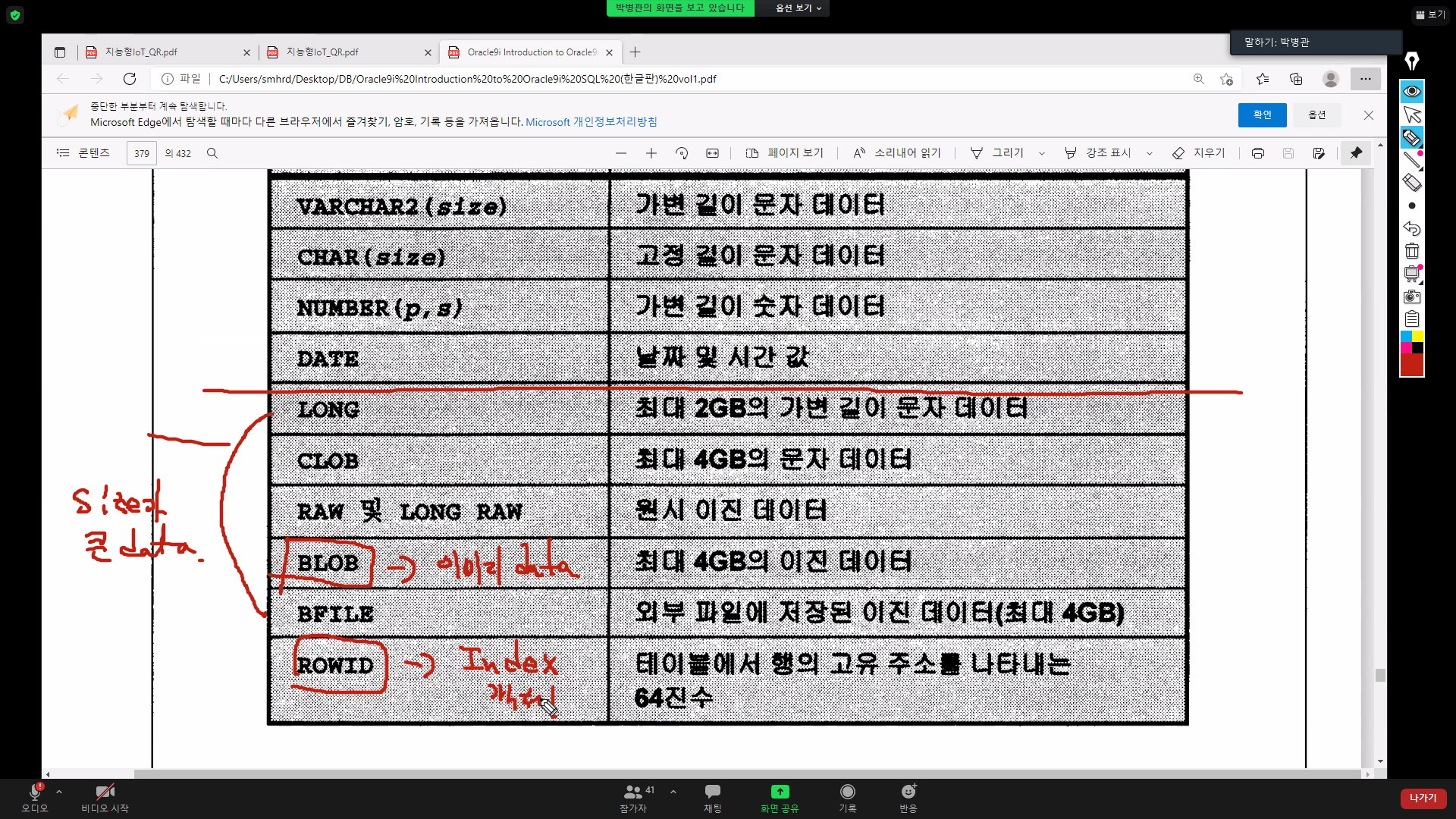
char(5) - 고정 - 미리공간을 만든다 (햄버거재료 미리깔아놓기)
varchar2(5) - 가변-데이터가 들어온만큼의 공간을 만든다 (햄버거주문 들어오고 확인후준비)
디스크조각모음 - 업데이트(삭제+삽입)하는중에 비어있는 디스크조각(블락)을 활용 못하고있는 공간을 재활용 - char에서 블락사용
트랜잭션 - 1번씩 쓰는것이 아니라 5번을 한번에 써서 I/O의 활용을 높여줘서 성능을 향상시킨다.
number - (-,0,+)
number(p) - (정수)
number(p,s) - (s는 소수점자리)
date - d/m/y (시차값이 적용되지않는다) 밀레니엄버그 1901년데이터-2001데이터
timestamp 시간/분/초 - hire_date timestamp
- create 서브쿼리 (원본테이블과 독립되어있어서 원본에서 데이터가 바뀌면 틀려진다)
ex) salary -> salary*12
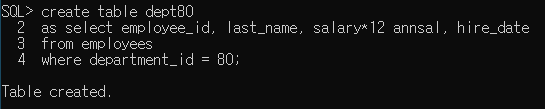
원래해야될작업

Alter table - 첫DB작업시 완벽한설계를 하기때문에 쓰이게된다면 DB가 완벽하지않다는걸 증명한다. (추가하면 원래있던 데이터보다 뒤로간다.)
insert - 열단위작업
알터테이블을 쓰고나서 null값에 데이터를 넣으려면 update를 써야한다.
drop - 삭제

Rename - 이름변경 (설계가 잘못되었다.)
- 삭제

drop, truncate => auto commit
create table, alter table 등 테이블생성과정중에 테이블이 중복이 되어 문제가 발생함
(pk,fk 설정을 해주어야함)
insert - column 무결성 (타입과 길이에 맞는 데이터만 저장되어야한다.)
pk,fk - 제약조건 무결성
- 제약조건 -> 테이블의 데이터 무결성을 보장하기위한 조건
-> 컬럼별로 설치(부여)
-> 한개의 컬럼에 여러개의 제약조건 부여
- not null - 반드시 값이 있어야함
- unique - 중복x , null값은 허용
- primary key - not null+unique 대표할수있는 pk는 1개라도 pk가 지정되어있어야함
- foreign key - 참조키(참조대상 col = pk,uk 지정되어있어야함)
- check - 사용자 정의 (sal>1000)
제약조건 지침
1) 제약조건에 이름을 지정하지않으면 sys_001 형식의 이름을 생성한다.
2) 제약 조건 생성시기
테이블이 생성될때, 또는 - create table 포함 같이 생성 (대부분)
테이블이 생성된 후에 - alter table 추가 (잘안씀)
constraint - 제약조건을 선언을 하겠다.
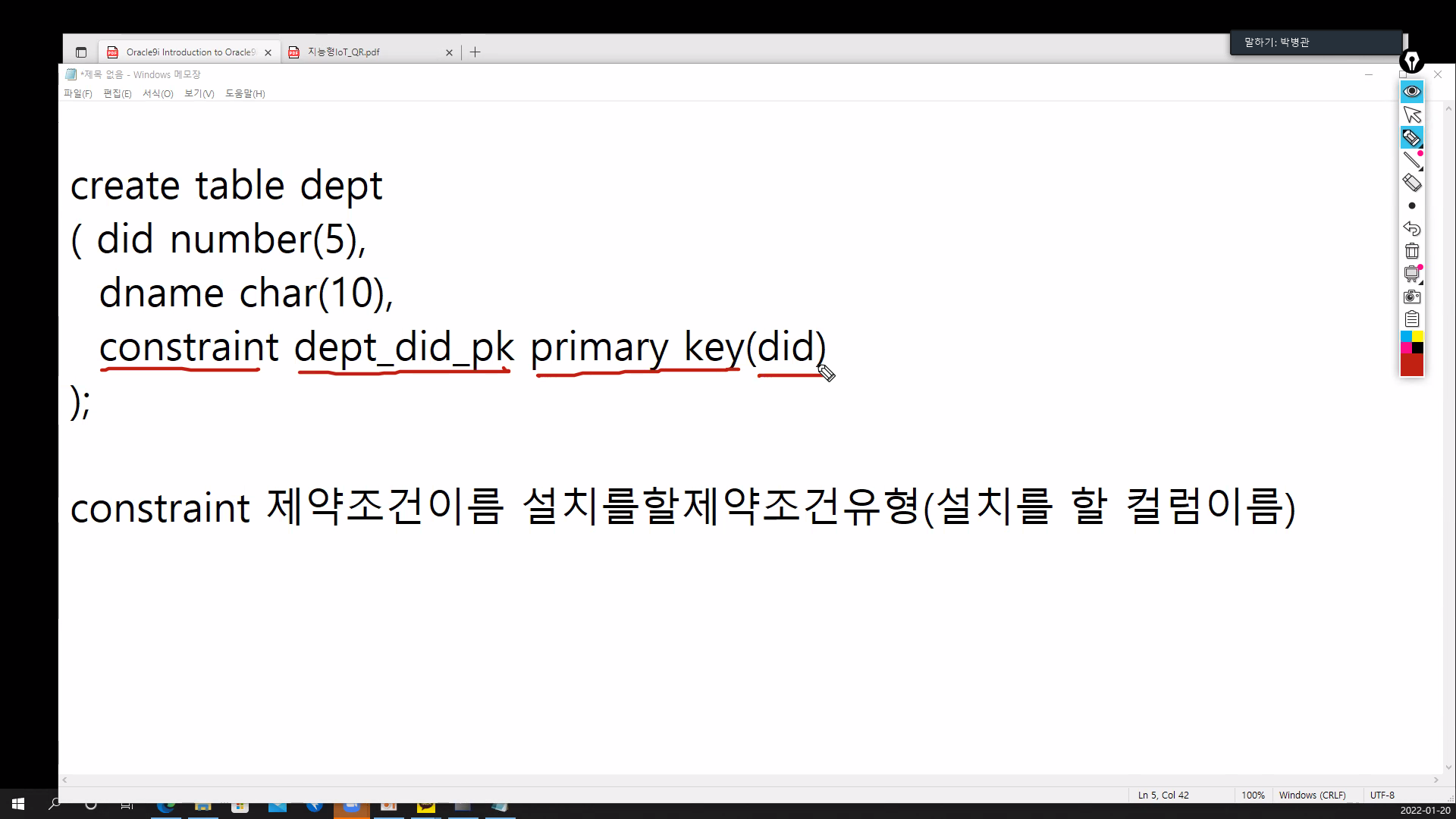 - table level설정 (컬럼을 먼저 선언을 하고, 별도로 제약조건 선언 설치할 컬럼의 이름이 마지막에 명시
- table level설정 (컬럼을 먼저 선언을 하고, 별도로 제약조건 선언 설치할 컬럼의 이름이 마지막에 명시
프라이머리키, 포린키, 유니크, 체크)(PK,FK,UK,CK)
 - column level설정(컬럼과 제약조건을 같이 명시, 컬럼이 앞에명시
- column level설정(컬럼과 제약조건을 같이 명시, 컬럼이 앞에명시
프라이머리키, 포린키, 유니크, 체크),낫널포함

포린키는 참조가 필요한데 설정할때
한행이 더해져서 References 참조할 테이블이름과 컬럼이름이 필요하다

emp 포린키가 dept 프라이머리키를 래퍼런스 종속적인 삭제를 방지한다.
dept emp
10번 a - 100 10번
종속적인 삭제방지를 삭제하는법
on delete cascade - 부모행과 참조 자식행이 같이 삭제
on delete set null - 부모행은 삭제, 자식행에는 참조값을 null로 대체한다.
check 제약조건 - 컬럼에 조건

1.create table 테이블이름
