Query 튜닝
쿼리 튜닝
🔗 Test DB SQL 파일 🔗
- 이곳에서 테스트용 대용량 DB를 받을 수 있다.
🔗 예시 확인 할 참고 블로그 🔗
- 이곳에서 보다 자세한 정보와 파라미터 정보를 확인할 수 있다.
1. 쿼리 튜닝이란?
데이터베이스에서 쿼리의 성능을 최적화하는 과정으로 시스템의 구성, 인덱스(Index)의 사용, 쿼리의 구조 등을 파악하고 최적화하여 소요되는 시간과 리소스를 최소화하고 쿼리의 처리 속도를 빠르게 만들어 주는 작업이다.
즉 쿼리의 속도를 최대한 빠르게 해주는 작업이라고 볼 수 있다.
2. 왜 필요한가?
- Compuware의 웹 성능 사업부의 Gomez - 3초 동안 기다리게 되면 사용자의 40%가 사이트를 이탈
- 월마트(Walmart)는 페이지 속도를 100ms까지 개선하면 수익이 1% 증가한다는 사실을 발견
웹 페이지의 속도 저하는 의심할 부분의 굉장히 많다. 백엔드 코드에서 시간이 오래 걸릴 가능성도 있고, 프론트 코드의 렌더링이 최적화 되어 있지 않을수 있다.
그렇다고 백엔드 코드와 프론트 코드에서 잘 해주겠지~ 라는 마인드를 가질 수는 없는 노릇이다.
3. 쿼리 실행 계획
우리는 쿼리 실행 계획을 보고 DB엔진이 어떻게 해당 SQL문을 실행할지 확인할 수 있다. 실행 계획을 보는 방법은 아래와 같다.
-
Explain문 (DESC, DESCRIBE)
빨간색으로 표시된 아이콘을 누르거나 명령어를 통해서 확인할 수 있다.
- Explain Analyze이란? : https://dev.mysql.com/blog-archive/mysql-explain-analyze/ MySQL 8.0에 추가되어 실제 쿼리를 실행하여 실제 코스트와 실제 소요 시간을 표시
- 예시 테이블 🔗 SQL 파일, 참고 블로그 🔗
-
사원 테이블(300,024 행)

-
사원출입기록 테이블(356,258 행)

-
- Explain문 실행 결과
SELECT (SELECT e.이름 FROM 사원 AS e WHERE e.사원번호 = 10001) AS 이름, (SELECT d.부서명 FROM 부서 AS d WHERE d.부서번호 = (SELECT dm.부서번호 FROM 부서사원_매핑 AS dm WHERE dm.사원번호 = 10001)) AS 부서명, (SELECT dm.시작일자 FROM 부서사원_매핑 AS dm WHERE dm.사원번호 = 10001) AS 시작일자;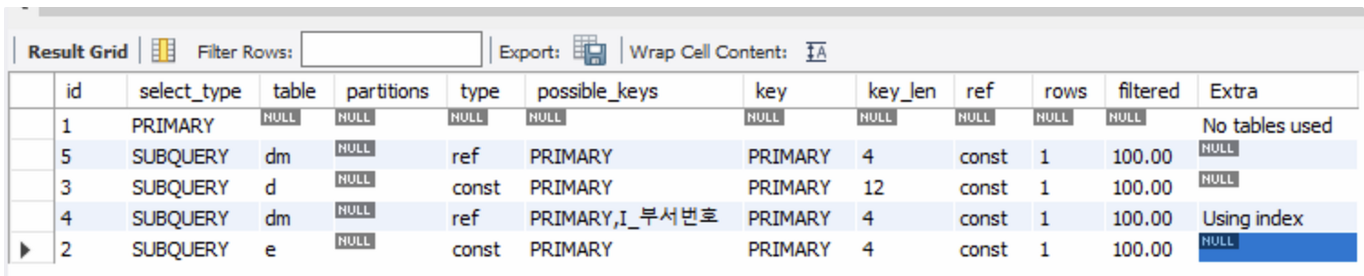
- Explain Analyze이란? : https://dev.mysql.com/blog-archive/mysql-explain-analyze/ MySQL 8.0에 추가되어 실제 쿼리를 실행하여 실제 코스트와 실제 소요 시간을 표시
실행 결과를 확인하면 다양한 것들이 나온다. 각자의 의미는 아래와 같다.
- Explain 문 Columns
| 구분 | 설명 |
|---|---|
| id | SQL문에서 몇 번째 SELECT문인지를 구분하는 번호 |
| select_type | select에 대한 타입 |
| table | 참조하는 테이블 이름 |
| type | MySQL 서버가 테이블의 레코드를 어떤 방식으로 찾을지 정보를 나타내는 컬럼 |
| possible_keys | 조회시 DB에서 사용할 수 있는 인덱스 리스트 |
| key | 실제로 사용한 인덱스 |
| key_len | 실제로 사용할 인덱스의 길이 |
| ref | 액세스 조건(참조 조건)에 사용된 컬럼 |
| rows | 쿼리 실행 시 조사하는 행 |
| extra | 추가 정보 |
- type의 종류들
이 컬럼 중에서 가장 중요하다고 생각되는 type에 관하여 작성했다.구분 설명 system 테이블에 단 한 개의 데이터만 있는 경우 const SELECT에서 PK 혹은 Unique Key를 조회하는 경우로 한 건의 데이터 조회한 경우 eq_ref 조인 시 드라이빙 테이블이 드리븐 테이블 접근하여 고유 인덱스나 기본 키를 사용하여 단 1건의 데이터를 조회한 경우 ref 조인 할 때 JOIN 순서에 상관없이 사용, 데이터 접근 범위가 2개 이상 또는 WHERE 절의 비교 연산자가 있을 경우 ref_or_null ref 와 같지만 null 이 추가되어 검색되는 경우 index_merge 두 개의 인덱스가 병합되어 검색이 이루어지는 경우 unique_subquery IN 절 안의 서브쿼리에서 Primary Key가 오는 특수한 경우 index_subquery unique_subquery와 비슷하나 Primary Key가 아닌 인덱스인 경우 range 테이블 내 연속적인 범위 내에서 인덱스를 사용하여 원하는 데이터를 추출하는 경우 index 인덱스를 처음부터 끝까지 찾아서 검색하는 경우 (인덱스 풀 스캔) all 테이블을 처음부터 끝까지 검색하는 경우 (테이블 풀 스캔)
그렇다고 나머지가 중요하지 않은 것은 아니다. 추가 정보는 글 맨 위의 게시글을 보면 좋다.
4. 쿼리 튜닝의 방법
-
인덱스 생성
인덱스는 데이터베이스 내의 테이블에서 특정 컬럼에 대한 검색을 빠르게 수행할 수 있게 한다.
-
예시
-
인덱스 없이 조회
SELECT * FROM 사원출입기록 where 사원번호 = 278318;- Explain Analyze

- Execution Plan
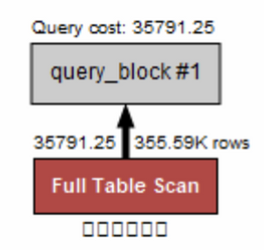
풀 테이블 스캔이다. 그림이 빨간색인 것에서부터 좋지 않는 느낌을 풍긴다. 테이블 전체를 스캔하는 것으로 코스트가 너무나도 높음을 확인할 수 있다. - Explain Analyze
-
인덱스로 조회
```sql # CREATE INDEX idx_test ON 사원출입기록2 (사원번호); SELECT * FROM 사원출입기록2 USE INDEX (idx_test) where 사원번호 = 278318; ```- Explain Analyze

- Execution Plan
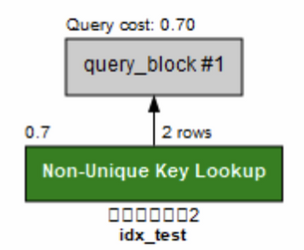
안덱스 스캔이다. 그림이 빨간색에서 초록색으로 바뀌었다. 참으로 안정감이 드는 색이다.. 풀 테이블 스캔에 비해서 코스트가 매우 줄어들었다.
 위의 사진은 실행에 걸린 시간이다. 위에는 인덱스 사용, 아래는 미사용이다.
유의미한 차이가 있음을 확인할 수 있다.
위의 사진은 실행에 걸린 시간이다. 위에는 인덱스 사용, 아래는 미사용이다.
유의미한 차이가 있음을 확인할 수 있다.
- Explain Analyze
-
-
-
서브쿼리보다는 조인문 사용
일반적으로 서브쿼리보다는
조인이 성능이 더 좋다.(차이 없다고 합니다!)- 예시
- 서브쿼리
SELECT (SELECT e.이름 FROM 사원 AS e WHERE e.사원번호 = 10001) AS 이름, (SELECT d.부서명 FROM 부서 AS d WHERE d.부서번호 = (SELECT dm.부서번호 FROM 부서사원_매핑 AS dm WHERE dm.사원번호 = 10001)) AS 부서명, (SELECT dm.시작일자 FROM 부서사원_매핑 AS dm WHERE dm.사원번호 = 10001) AS 시작일자; - 조인
SELECT e.이름 AS 이름, d.부서명, dm.시작일자 FROM 사원 AS e JOIN 부서사원_매핑 AS dm ON e.사원번호 = dm.사원번호 JOIN 부서 AS d ON dm.부서번호 = d.부서번호 WHERE e.사원번호 = 10001;서브쿼리 조인 0.00043950 0.00036950 0.00031250 0.00029650 0.00031300 0.00029625 0.00031325 0.00031525 0.00030625 0.00029850 0.00031475 0.00029925 0.00031075 0.00030175 0.00032100 0.00029525 0.00030875 0.00029950 0.00031175 0.00029725 0.00032515 0.00030690
- 서브쿼리
- 예시
-
쿼리의 최적화 (WHERE 절 최적화)
WHERE 절을 최적화하여 쿼리의 실행 속도를 높일 수 있다.
- 예시
- 사원번호가 1100X인 사원 검색
-
SELECT * FROM 사원 WHERE SUBSTRING(사원번호,1,4) = 1100 # like 같은거 성능 저하! AND LENGTH(사원번호) = 5 -
SELECT * FROM 사원 WHERE 사원번호 BETWEEN 11000 AND 11009 # 범위가 인덱스- 결과
풀 테이블 스캔이 일어났다. 전체를 뒤져서 앞자리가 1100으로 시작하고 5자리의 사원번호를 찾기 때문이다.인덱스 범위 스캔이다. 이는 범위를 지정했기 때문에 인덱스를 사용해서 11000~11009만을 찾기 때문에 풀테이블 스캔이 일어나지 않기 때문이다.
- 예시
이처럼 Where절에 조건을 어떤 방식으로 넣느냐에 따라서도 쿼리의 실행이 달라지고 성능에 크게 차이가 난다.
5. 추가적인 쿼리 성능 향상법
-
인덱스 재구성
인덱스 생성 후 Insert, Update, Delete를 반복하다보면 트리의 한쪽이 무거워져 전체적으로 트리의 깊이가 깊어지기 때문에 성능이 저하된다. 따라서 인덱스를 재구성하는 작업이 필요할 수 있다.
-
쿼리 캐싱: DB시스템에서 제공하는 쿼리 캐싱 기능. 캐싱은 자주 실행되는 쿼리의 결과를 메모리에 저장하여 쿼리 반복 실행의 필요성을 줄인다.
- 하지만.. MySQL 8.0에서는 쿼리 캐싱을 지원하지 않음. 심각한 확장성의 문제과 병목 현상이 너무나 심하기 때문.. → 관련 문서
- 하지만.. MySQL 8.0에서는 쿼리 캐싱을 지원하지 않음. 심각한 확장성의 문제과 병목 현상이 너무나 심하기 때문.. → 관련 문서
-
데이터 파티셔닝: 파티셔닝은 쿼리 실행 중에 데이터베이스가 관련 파티션만 검색하거나 액세스할 수 있도록 한다.
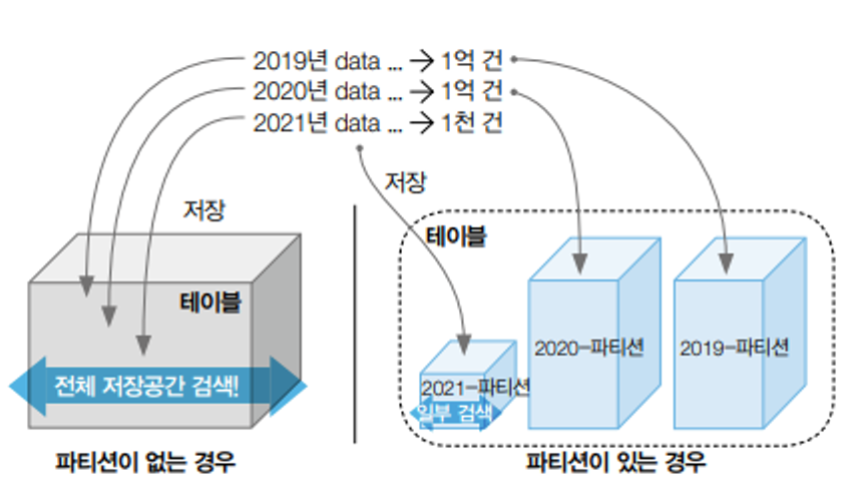
-
쿼리 힌트: 데이터베이스 시스템에서 제공하는 쿼리 힌트 또는 지시문을 사용하여 쿼리 실행 계획을 직접 설정한다.
-
예
select * from 사원출입기록 where 출입문 = 'A'; select * from 사원출입기록 ignore index(I_출입문) where 출입문 = 'A';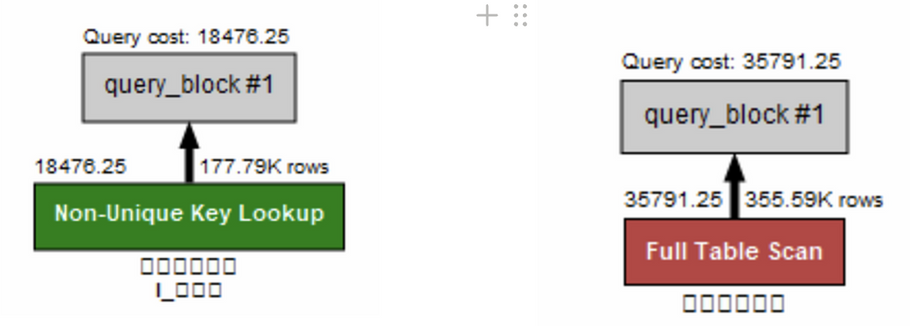
-
결과

이는 인덱스를 약 34만개의 데이터 중에 17만개를 읽어오는 쿼리문이기 때문인데 테이블에서 찾아야하는 데이터의 수가 많은 경우는 오히려 인덱스의 사용이 성능을 저하시킨다는 것을 확인할 수 있다. ``` -
DB는 항상 최선의 실행계획을 수립하지는 않는다...
-
-
발표 영상
때에 따라 인덱스가 독이 될 수 있는 것처럼 쿼리 튜닝에 확실하게 정해진 답이 있는 것은 아닌것 같다.
언제나 이것이 최선인지, 다른 방법은 없는지 고민하고 또 고민을 하는 것이 중요한 것으로 생각이 든다...
그것이 쿼리문과 DB를 공부해야하는 이유가 아닐까,,
