❓ 결정 트리란 무엇인가?
결정 트리는 지도 학습(Supervised Learning) 모델의 하나로, 나무(Tree) 구조를 활용하여 데이터를 분석하고 예측 또는 분류 규칙을 만드는 알고리즘입니다. 이름 그대로 결정(Decision) 규칙들을 나무(Tree) 형태로 시각화하여 표현합니다.
주요 용도
결정 트리는 크게 두 가지 문제를 해결하는 데 사용합니다!
- 분류(Classification): 데이터가 어떤 범주(클래스)에 속하는지 예측합니다. 예를 들어, 이메일이 스팸인지 아닌지, 대출 신청자의 신용도가 좋은지 나쁜지를 판단할 수 있습니다.
- 회귀(Regression): 연속적인 숫자 값을 예측합니다. 예를 들어, 주택 가격이나 다음 분기 매출액을 예측하는 데 활용할 수 있습니다.
구조
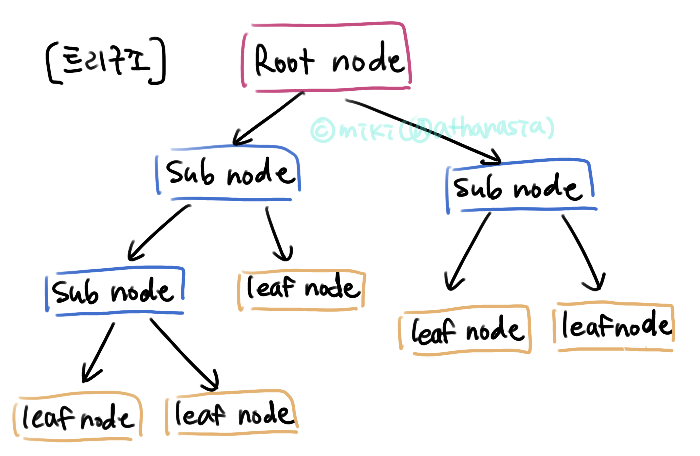
결정 트리는 다음과 같은 핵심 구성 요소로 이루어져요.
- 뿌리 노드 (Root Node): 트리의 최상단 시작점으로, 전체 데이터를 포함합니다.
- 중간 노드 (Internal Node / Decision Node): 데이터의 특정 특성(feature)에 대한 질문을 나타냅니다. 이 질문에 따라 데이터가 여러 하위 그룹으로 나뉩니다.
- 가지 (Branch / Edge): 중간 마디의 질문에 대한 답변을 나타내며, 다음 마디로 연결됩니다.
- 잎 노드 (Leaf Node / Terminal Node): 트리의 최하단 끝점으로, 최종 예측 결과를 나타냅니다. 더 이상의 데이터 분할이 일어나지 않습니다.
⚙️ 작동 방식
- 규칙 학습: 결정 트리는 학습 데이터로부터 "만약 ~라면 ~이다"(if-then) 형태의 규칙을 자동으로 학습합니다. 각 마디에서는 데이터를 가장 잘 구분할 수 있는 특성과 기준점을 찾습니다. 이때, 정보 이득(Information Gain), 지니 불순도(Gini Impurity) 등을 최적화하는 방향으로 진행하게 됩니다.
- 예측: 새로운 데이터가 주어지면, 뿌리 마디부터 시작해 각 중간 마디의 질문에 따라 해당 가지를 따라갑니다. 최종적으로 잎 마디에 도달하면, 그 마디의 예측값을 결과로 사용합니다.
🤔 예시
Q. 오늘 테니스를 칠까? 🎾
-> 이 질문에 대한 트리의 구조 ⬇️
- 뿌리 마디: 날씨는 어떤가?
- 가지 1 (맑음): 중간 마디 → 습도는 어떤가?
- 가지 1-1 (높음): 잎 마디 → 테니스를 치지 않는다.
- 가지 1-2 (보통): 잎 마디 → 테니스를 친다.
- 가지 2 (흐림): 잎 마디 → 테니스를 친다.
- 가지 3 (비): 잎 마디 → 테니스를 치지 않는다.
이처럼 결정 트리는 연속된 질문과 답변을 통해 최종 결론에 도달하는 과정을 명확히 보여줍니다. 이는 결정 트리의 주요 장점인 "이해와 해석이 용이하다"는 특징을 잘 보여주는 예시에요.
결정 트리는 독립적으로 사용되기도 하지만, 랜덤 포레스트(Random Forest)나 그래디언트 부스팅(Gradient Boosting)과 같은 더 강력한 앙상블(Ensemble) 모델의 기본 요소로도 널리 활용됩니다.
📌 결정트리의 장단점
✅ 결정 트리의 장점
- 이해와 해석이 용이하며 시각화가 쉽습니다
- 트리 구조를 통해 의사결정 과정이 명확하게 표현되어, 각 단계별 결정과 그 결과를 직관적으로 파악할 수 있습니다.
- 비전문가도 트리를 보면서 "왜 이런 결과가 나왔는지" 비교적 쉽게 이해할 수 있습니다.
- 데이터 전처리 요구가 비교적 적습니다
- 수치형 데이터의 정규화(normalization)나 스케일 조정과 같은 복잡한 전처리 과정이 다른 알고리즘에 비해 덜 필요하거나 필요하지 않은 경우가 많습니다. ex. 원-핫 인코딩(One-Hot Encoding)
- 결측값(missing values)이 있어도 어느 정도 처리가 가능하며, 특성 선택(feature selection)이 중요하지 않은 경우 별도의 과정 없이도 작동할 수 있습니다.
- 수치형 및 범주형 변수를 모두 처리할 수 있습니다
- 입력 특성(피처)이 연속적인 수치형이든 불연속적인 범주형이든 구분 없이 사용할 수 있어 다양한 유형의 데이터셋에 적용 가능합니다.
- 비선형(non-linear) 관계 모델링이 가능합니다
- 결정 트리는 특정 데이터 분포에 대한 가정을 하지 않는 비모수적(non-parametric) 모델이므로, 데이터가 선형 관계를 가지지 않을 때도 높은 유연성을 발휘하여 복잡한 패턴을 학습할 수 있습니다.
- 특성 선택이 자동화되며 중요도 파악이 용이합니다
- 트리를 구성하는 과정에서 중요한 특성이 자동으로 상위 노드에 배치되는 경향이 있으며, 어떤 특성이 분기에 큰 영향을 미치는지 파악하기 쉬워 중요한 변수를 선별하는 데 도움이 됩니다.
❌ 결정 트리의 단점
- 과적합(Overfitting)의 위험이 높습니다
- 훈련 데이터에 과도하게 최적화되어, 트리가 너무 깊고 복잡해지면 새로운 데이터에 대한 일반화 성능이 떨어질 수 있습니다.
- 이를 방지하기 위해 가지치기(pruning), 최대 깊이 제한(max depth) 등의 규제가 필요합니다.
- 데이터의 작은 변화에 민감하여 불안정할 수 있습니다 (불안정성)
- 훈련 데이터에 약간의 변화만 생겨도 트리 구조가 크게 달라질 수 있어 모델의 안정성이 낮을 수 있습니다.
- 최적의 트리 구조를 찾는 것이 항상 보장되지는 않습니다
- 결정 트리는 각 단계에서 국소적으로 최적인 결정을 내리는 탐욕적(greedy) 알고리즘을 사용합니다. 이로 인해 전체적으로 최적인 전역 최적 해(global optimum)를 찾지 못할 수도 있습니다.
- 복잡한 문제에서의 성능 제한 및 경계면 표현의 한계가 있습니다
- 단순한 규칙 기반의 축 평행 분할(axis-parallel split)로 인해, 데이터 분포가 복잡하거나 경계선 근처의 데이터에 대해서는 오차가 클 수 있고, 복잡한 패턴을 제대로 학습하지 못할 수 있습니다.
- 연속적인 값을 예측하는 회귀 문제에서는 계단 형태의 예측을 만들어 부드러운 예측이 어렵습니다.
- 이러한 단점을 보완하기 위해 랜덤 포레스트, 그래디언트 부스팅과 같은 앙상블 기법을 활용하는 경우가 많습니다.
- 균형 잡히지 않은 데이터(imbalanced data)에 취약할 수 있습니다
- 특정 클래스의 데이터가 다른 클래스에 비해 현저히 많거나 적을 경우, 다수 클래스에 편향된 예측을 하는 경향이 나타날 수 있습니다.
- 대용량 데이터셋 처리 시 계산 비용이 높을 수 있습니다
- 데이터의 양이 매우 많거나 특성의 수가 많을 경우 트리를 구축하는 데 많은 계산 자원이 필요할 수 있습니다.
💡 결정 트리 장단점 표 요약
| 구분 | 장점 🌿 | 단점 🍂 |
|---|---|---|
| 해석성 | 이해 및 시각화 용이 | - |
| 전처리 | 정규화/스케일링 불필요 | - |
| 유연성 | 수치형/범주형 모두 가능, 비선형 처리 | 복잡한 경계 처리 한계 |
| 안정성 | - | 데이터 변화에 민감 (불안정) |
| 학습 구조 | 특성 중요도 파악 가능 | 전역 최적 보장 어려움 |
| 일반화 | - | 과적합 위험 높음 |
| 계산 효율 | - | 대규모 데이터 시 자원 소모 큼 |

변방의 개발자