로그인 프로세스 이해
쿠키/세션 로그인
첫번째 로그인 역사
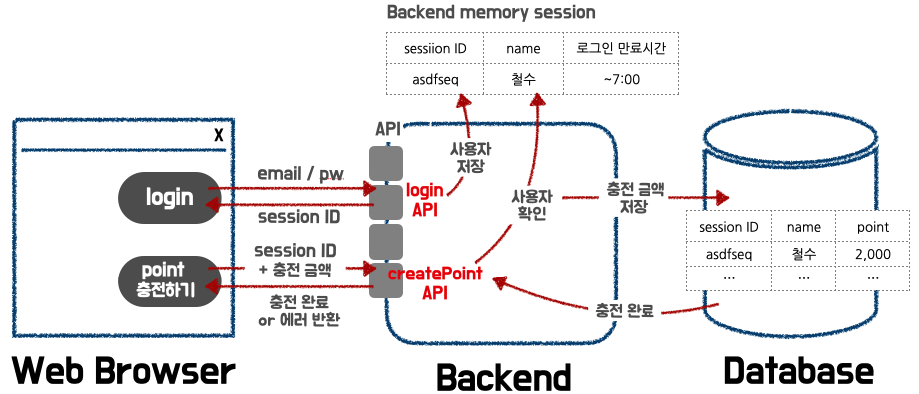
브라우저에서 특정 email과 password를 가지고 로그인을 하게되면
Backend로 loginAPI 요청이 날아가게 되고, Backend에서는 해당 유저를 Backend session에 저장한다.
그 후 특정한 session ID를 부여해서 브라우저로 보내준다.
이렇게 보내진 session ID는 어떤 상황에서 사용될까?
웹에는 로그인을 해야지만 사용 가능한 서비스들이 존재하는데, 이때 사용되는 API들이 존재한다.
예를 들어, 포인트 충전 API, 프로필 수정 API, 내가 쓴 게시글 조회 API 등등.. 먼저 로그인을 해야 할 수 있는 API 들은 많이있다.
그 중에서, 먼저 포인트 충전 API 로직을 알아보자
철수가 포인트 충전 버튼을 클릭하여 createPoint API가 Backend로 요청되었다.
요청을 할 때, 충전을 요청한 유저가 본인이 누군지 식별 할 수 있도록 session ID를 넣어서 포인트 충전 요청이 들어오게 된다.
요청을 받은 백엔드에서는 session ID를 확인하여 유저를 파악하는데 이때 로그인한 유저가 맞다면 해당 유저에 대한 충전 금액을 DB에 저장하고
로그인한 유저가 아니라면 즉, 사용자 확인 시 없는 session ID라면 로그인 하지 않은 유저이므로 “로그인 후 이용가능합니다” 라는 에러를 반환해준다.
이렇게 유저의 정보(ID)를 백엔드 서버로 받다보니 한번에 여러명의 정보를 받기엔 한계가 있다.
즉, 백엔드 서버로 동시 접속자가 많아질수록 백엔드 서버 메모리가 부족해지면서 서버가 버티질 못하게 되는 것이다.
이때, 이를 보완하기 위해서 백엔드 컴퓨터를 scale-up 해주어야 한다.
scale-up
: 컴퓨터의 성능( CPU, Memory 등)을 올려주는 것.
두번째 로그인 역사
이렇게 백엔드 컴퓨터의 성능을 올려주었음에도 불구하고 계속하여 동시 접속자 수가 많아질수록 여전히 서버에는 부하가 생긴다.
그래서 나온 방법으로 백엔드 컴퓨터를 복사하는 방법이 있다.
이 방법은 유저의 정보가 담기는 백엔드 컴퓨터를 여러 대로 복사해 서버의 부하를 분산시켜 준다.

여기서의 문제점은 컴퓨터를 복사할 때는 session까지
scale-out** 을 하지 않아 기존의 로그인 정보를 가지고 있던stateful상태인 백엔드 컴퓨터가 아니면 로그인 정보가 존재하지 않는다.
물론 session까지 scale-out을 할 수는 있지만, 그러면 결국 동일한 유저 정보에 대해 모든 백엔드 컴퓨터에 정보를 저장하게 되므로 결국 메모리 부족으로 서버가 터지는 동일한 상황이 생긴다.
따라서, stateless 상태로 백엔드 컴퓨터를 확장해야 한다.
scale-out
: 똑같은 성능의 컴퓨터를 추가하는 것.
stateful
: session에 로그인한 유저 정보를 저장하여 가지고 있는 상태
stateless
: session에 로그인한 유저 정보가 없는 상태
테이블 파티셔닝 이해 - 수평(샤딩)과 수직
세번째 로그인 역사
테이블 파티셔닝은 위의 session을 scale-out 해오지 못하는 문제점을 보완한 방법이며, 현재 많이 쓰이고 있는 방법 중 하나이다.
로그인 정보를 백엔드 session에 저장하는 것이 아니라 DB에 저장하는 방법이다.
하지만 결국 이것도 백엔드 서버의 부하가 Session이 아니라 DB로 옮겨진 것 뿐이기에 DB의 부하를 초래하는 것은 같다.
보안을 위해 DB를 복사하면 되지만, 사실 현실적인 이유로 DB를 복사하는 방법은 비용 문제가 발생하기 때문에 비효율적이다.
따라서 위의 문제점은 데이터를 나누면서 해결하게된다.


DB를 나누는 2가지 방법
- 수직으로 나누는 수직파티셔닝
- 수평으로 나누는 수평파티셔닝(샤딩)
API를 요청할 때 어느 백엔드 컴퓨터에 접속하여도 똑같은 요청 처리와 응답이 이루어진다.
수평 파티셔닝을 통해 DB를 나누어 저장하여 DB의 부하까지 분산하여 주었다.
DB에 저장할 때는 메모리 기반의 session 방식에서 디스크 기반의 token(DB에 저장되어 있는 유저의 ID) 방식으로 바뀌었다.

이렇게 저장된 특정 ID(토큰)을 다시 브라우저로 돌려준다.
돌려받은 토큰은 브라우저 저장공간에 토큰을 저장해두고 어떤 행동을 할때 토큰을 같이 보내주어 사용자가 누구인지 식별한다.
이 때, 문제점이 있다.
DB는 컴퓨터를 껐다 켜도 날아가지 않기 때문에 데이터들이 disk에 저장되는 장점이 있다.
하지만, 로그인할 때마다 DB에 가서 해당 유저를 파악해야 하는 즉, DB에서 데이터를 꺼내와야 한다.
DB에서 데이터를 꺼내 오는것을 DB를 긁는다고(scrapping) 표현한다.
따라서 DB는 디스크 기반으로 안전하지만 DB를 긁는 속도는 느립니다.
이를 해결하기 위한 방법으로 메모리 기반의 Redis 라는 DB에 저장하여 속도 문제를 해결했다.
Redis
: 메모리에 저장해두는 임시 데이터 베이스
Redis를 사용하면 컴퓨터 종료 시 데이터가 날아가는 문제가 있지만, Redis 메모리가 날아가지 않는 방식이 존재하기 때문에 적절히 조율해서 사용하는 것이 좋다.
JWT 토큰
네번째 로그인 역사
현재 많이 쓰이고 있는 방법 중 또 다른 하나로, JWT 토큰 방식이다.

JWT 토큰은 유저 정보를 담은 객체를 암호화를 통해 문자열로 만들어 암호화된 키(accessToken)를 브라우저로 전달한다.
브라우저는 받아온 암호화된 키를 브라우저 저장소에 저장해두었다가 유저의 정보가 필요한 API를 사용할 때,
API 요청과 함께 보내주게 되면, 해당 키를 백엔드에서 복호화해서 사용자를 식별한 후 접근이 가능하도록 해준다.
JWT 토큰에는 해당 토큰이 발급 받아온 서버에서 정상적으로 발급을 받았다는 증명을하는 signature를 갖고있다.
따라서 사용자의 정보를 DB를 열어보지 않고도 식별할 수 있는 것이다.
JWT 토큰의 구성
1. header : 토큰의 타입, 암호화시 사용한 알고리즘 정보
2. payload : 토큰 발행정보(누구인지, 언제 발행되었는지, 언제 만료될 것 인지)
3. signature : 토큰의 비밀번호
