1. HAProxy란?

HAProxy는 TCP 및 HTTP 애플리케이션을 위한 고성능 오픈 소스 로드밸런서 이자 리버스 프록시이다.
HAProxy는 워크로드를 분산하고 웹사이트 및 애플리케이션 성능을 향상시킨다. 성능 향상에는 응답 시간 최소화 및 처리량 증가가 포함된다. GitHub 및 X(이전 Twitter)와 같이 트래픽이 많은 서비스는 HAProxy를 사용한다.
로드 밸런서는 컴퓨터, 네트워크, 디스크 드라이브 또는 중앙 처리 장치에 워크로드를 분산한다. 많은 Linux 배포판에 포함된 HAProxy는 소프트웨어 로드밸런싱 분야의 주요 표준 중 하나이다.
HAProxy는 오픈 소스이지만, HAProxy Technologies는 HAProxy Enterprise라는 상용 옵션을 제공한다. 이 제품에는 엔터프라이즈급 애드온, 전문가 지원 및 전문 서비스가 포함되어 있다.
HAProxy는 대형 서비스들이 요구하는 고성능 로드밸런싱 및 고가용성(High Availability)을 지원하는 소프트웨어 로드밸런서이다. 예를들어 GitHub는 HAProxy 기반으로 로드밸런싱 계층을 구성해 다양한 클라이언트 요청(HTTP, Git, SSH 등)을 처리하고 있으며, 고가용성, 부하분산, 연결 처리 능력 등이 핵심 요소였다.
또한 HAProxy는 아주 많은 동시 연결을 효율적으로 처리할 수 있고, CPU 및 메모리 사용도 최적화 되어 있는 구조이다. HAProxy의 고성능 로드밸런싱 및 고가용성에 대한 자세한 내용은 아래에 후술 하겠다.
1.1 배경
- HAProxy의 창시자 : Willy Tarreau(윌리 타-로)

2000년대 초, 운영팀이 다수의 HTTP/HTTPS 요청을 안정적으로 처리해야 했으나 당시 하드웨어 로드밸런서가 과부하에 반복적으로 실패하는 문제가 있었다. Willy Tarreau는 이전에 만든 프록시(Zprox)를 개조해 헤더 재작성 및 다중 포트 리스닝 기능을 추가했고, 2001년경 이 프록시가 HAProxy(High Availability Proxy)로 배포되기 시작했다.
이로써 다수 요청 분산과 복잡한 HTTP 검사가 필요한 환경에서 경량화된 소프트웨어 방식 로드밸런서를 사용할 수 있게 되었고, 결과적으로 대형 웹사이트 및 서비스 인프라에서 고가용성(HA) 및 부하분산(LB)의 핵심 요소로 자리잡았다.
1.2 HAProxy 특징
-
L4(전송계층) 및 L7(응용계층) 로드밸런싱 지원
-
상태 점검 및 고가용성(HA) 구성 가능
-
유연한 라우팅 및 제어 기능 (ACL, 콘텐츠 기반 분기 등)
-
SSL/TLS 종료 및 오프로딩, 보안 기능
-
운영 및 모니터링 지원
2. HAProxy 구성 요소
2.1 설정 파일의 주요 섹션
-
global섹션-
global섹션은 HAProxy 프로세스 전체에 적용되는 설정들을 정의하는 영역이다. -
시스템 전체에 영향을 미치는 설정들을 한 곳에 모아두면, 로드밸런서 프로세스의 전박적인 동작(로그, 사용자 권한, 최대 연결 수, 운영 모드 등)을 일관성 있게 관리할 수 있다.
-
예를들어
user/gorup을 지정해 루트 권한에서 탈피하도록 하거나,maxconn으로 전체 허용 동시 연결 수를 정하거나,status socket으로 런타임 API 소켓을 설정하거나, 로그 서버 주소나 SSL 인증서 기본 경로 등을 지정할 수 있다. -
trade off
- 프로세스 수준의 보안 및 자원 제한이 가능해져 안정성을 높일 수 있다.
- 전체 설정을 한 곳에서 관리하므로 중복 설정이 줄어들고 관리가 쉬워진다.
- 시스템이 시작할 때 이 설정을 먼저 적용되어, 뒤따르는 다른 섹션들이 이 기반 위에서 동작하게 된다.
- 다만, 전역 설정이 서비스 전체에 미치는 영향이 크기 때문에 잘못 설정 시 전체 시스템에 장애가 될 수 있다.
-
-
defaults섹션-
frontend나backend같은 여러 섹션에서 반복적으로 동일한 설정을 입력하는 것은 비효율적이고 오류 가능성이 높다. 때문에 공통 설정을 미리 지정해주면 관리 부담이 줄어든다. -
defaults섹션은 이후 나오는frontend및backend섹션들이 기본으로 상속받을 설정을 정의하는 영역이다. -
예를들어
mode http,timeout connect 10s,timeout client 30s,options httplog,maxconn 3000같은 항목을 설정해두면, 각frontend/backend에서 반복 입력하지 않아도 된다. -
또한 여러 개의
defaults섹션을 둘 수 있고, 특정 타입(HTTP 전용, TCP 전용 등) 설정을 나눠서 적용할 수도 있다. -
trade off
- 설정 파일이 간결해지고 가독성이 증가한다.
- 공통 설정을 한 곳에서 변경하면 해당 설정이 자동으로 반영되어 운영 효율이 증가한다.
- 섹션별로 개별 설정을 덮어쓸 수 있어서 유연성과 재사용성도 높아진다.
- 하지만, 상속 구조로 인해 "어느 설정이 어디서 적용되었는가?"라는 추적이 어려워져 디버깅이 복잡해질 수 있다.
-
-
frontend섹션-
클라이언트가 접속하는 곳(리스닝 포트, IP)를 정의하고, 어떤 요청을 어떤 백엔드로 보낼지 결정하는 역할이 필요하다.
-
frontend섹션은 HAProxy가 클라이언트 요청을 받아들이는 리스너(listener)를 정의하는 부분이다. -
주요 설정 예시로
bind :80또는bind *:443 ssl crt /etc/ssl/cert.pem등으로 리스닝 IP, 포트를 지정한다. -
또한
default_backend my_backend또는use_backend some_backend if { 조건 }형태로 요청을 어떤 백엔드로 보낼지 제어할 수 있다. -
trade off
- 클라이언트 요청 접점이 명확해져 서비스 진입 구조가 설계된다.
- 조건 기반으로 다양한 백엔드로 요청을 분기할 수 있어 트래픽 제어나 서비스별 분리가 쉬워진다.
- 프록시 역할을 수행하는 HAProxy가 실제 서버 앞단에서
어떤 요청을 어떤 그룹으로 보낼지결정하므로 운영 유연성이 높아진다. - 리스닝 및 라우팅 설정이 복잡해지면 구성 오류 가능서잉 높아지고 유지 보수 부담이 커진다.
-
-
backend섹션-
실제 요청을 처리할 서버 풀(pool)을 정의하고, 로드밸런싱 방식과 서버 상태 감시 등을 설정해야 안정적 서비스가 가능하다.
-
backend섹션은 하나 이상의 서버(웹서버, 애플리케이션 서버 등)를 묶어 요청을 분산 처리하는 서버 그룹을 정의한다. -
주요 설정 예시로
balance roundrobin또는balance leastconn으로 알고리즘 선택,server srv1 192.168.1.3:80 check형식으로 서버 등록 및 헬스체크 지정한다. -
또한
cookie,default-server,option httpchk등 추가 설정으로 세션 지속성이나 HTTP 기반 헬스체크르르 구성할 수 있다. -
trade off
- 서버풀을 정의함으로써 요청 분산이 가능해지고 개별 서버 부하를 줄일 수 있다.
- 헬스 체크가 설정되어 있으면 장애 서버로 트래픽이 가지 않아 서비스 안정성이 향상 된다.
- 로드밸런싱 알고리즘을 설정함으로써 트래픽 특성(짧은 요청 vs 긴 연결 등)에 맞게 최적화할 수 있다.
- 서버 풀 규모가 커지거나 알고리즘이 복잡해질 수록 설정, 모니터링 부담이 증가할 수 있다.
-
2.2 Load Balancing & Algorithm
HAProxy에서 제공하는 로드밸런싱의 특징과 자주 사용되는 알고리즘은 아래와 같다.
2.2.1 성능과 경량 설계
여러 벤치마크에서 HAProxy가 HTTP / TCP 요청 처리량(thoughtput)과 지연 시간(latency) 측면에서 매우 우수한 성능을 보였다는 보고가 있다. 예를들어 HAProxy uses ~ 50 MB 메모리, NGINX ~ 80 MB 등의 비교가 나온다.
HAProxy의 공식 블로그에서도 소프트웨어 로드밸런서이면서 최대 성능을 내도록 설계되었다.는 설명이 있다. 구성언어 및 기능이 로드밸런싱에 집중되어 있고, 웹 서버 ++ 로드밸런서 복합 기능을 갖춘 제품(NGINX)은 더 많은 기능을 갖지만 로드밸런싱 순수성에는 약간의 복잡성이 있을 수 있다.
전통적인 요청 하나당 스레드 하나 방식이 아니라, I/O event(읽기 가능, 쓰기 가능)만 감지하고 처리하는 방식(예시 : linux의 epoll 등)을 사용하여 스레드 전환 비용, 블로킹 대기로 인한 리소스 낭비를 최소화한다. 또한 HAProxy는 CPU 캐시 효율을 고려해 가능한 한 동일 코어에 연결을 붙인다.(stick to same CPU)는 설계를 갖고 있다.
실사용으로 수백 만 RPS(requests per second) 또는 100 Gbps 이상 트래픽 처리 등이 가능하다는 언급도 있다.
2.2.2 세밀한 라우팅 및 알고리즘 지원
HAProxy는 많은 로드밸런싱 알고리즘 및 프로토콜(L4/L7)을 지원하고, ACL(조건문), 콘텐츠 기반 라우팅, 세션 지속성(sticky session) 등 고급 제어 기능에 강점을 가지고 있다.
2.2.3 배포 유연성 및 오픈소스 우위
HAProxy는 오픈 소스로 시작했으며, 소프트웨어 중심(load-balancerd만의 역할)에 집중된 설계이다. 따라서 Hardwere Appliance 기반의 기능이 덧붙여진 제품들과 비교했을 때 사용자가 필요한 대로 튜닝 가능하다.는 점이 강조된다.
2.2.4 HAProxy 대표 알고리즘
아래는 HAProxy에서 자주 사용하는 알고리즘들이다.
-
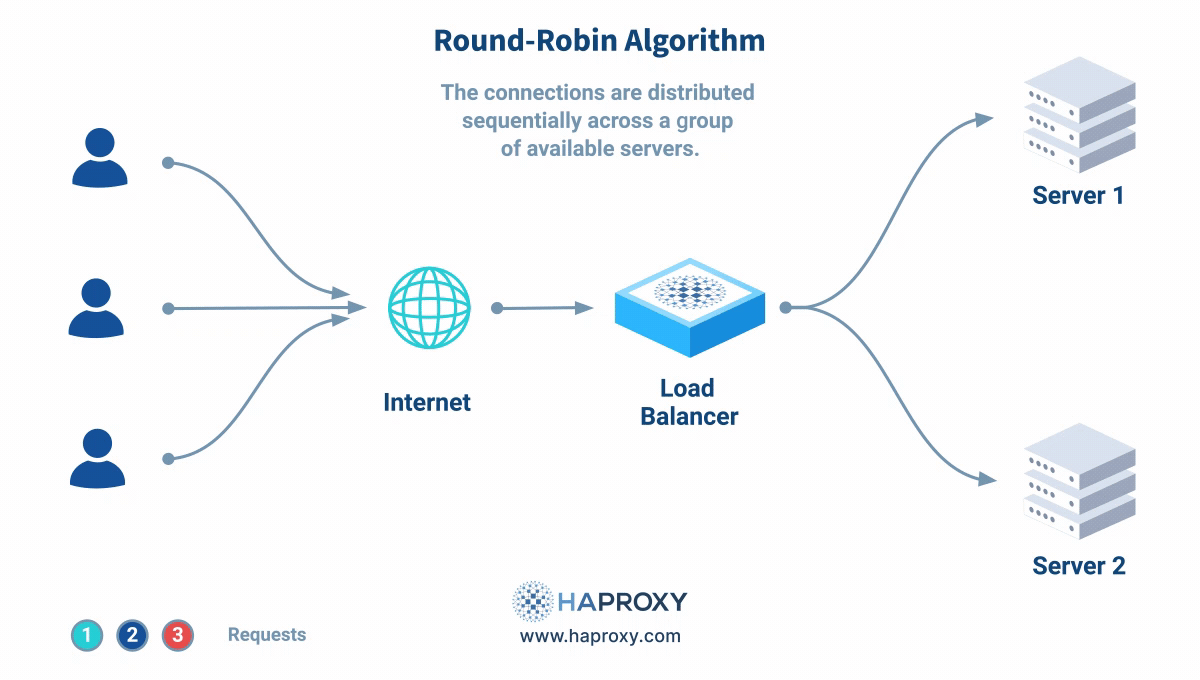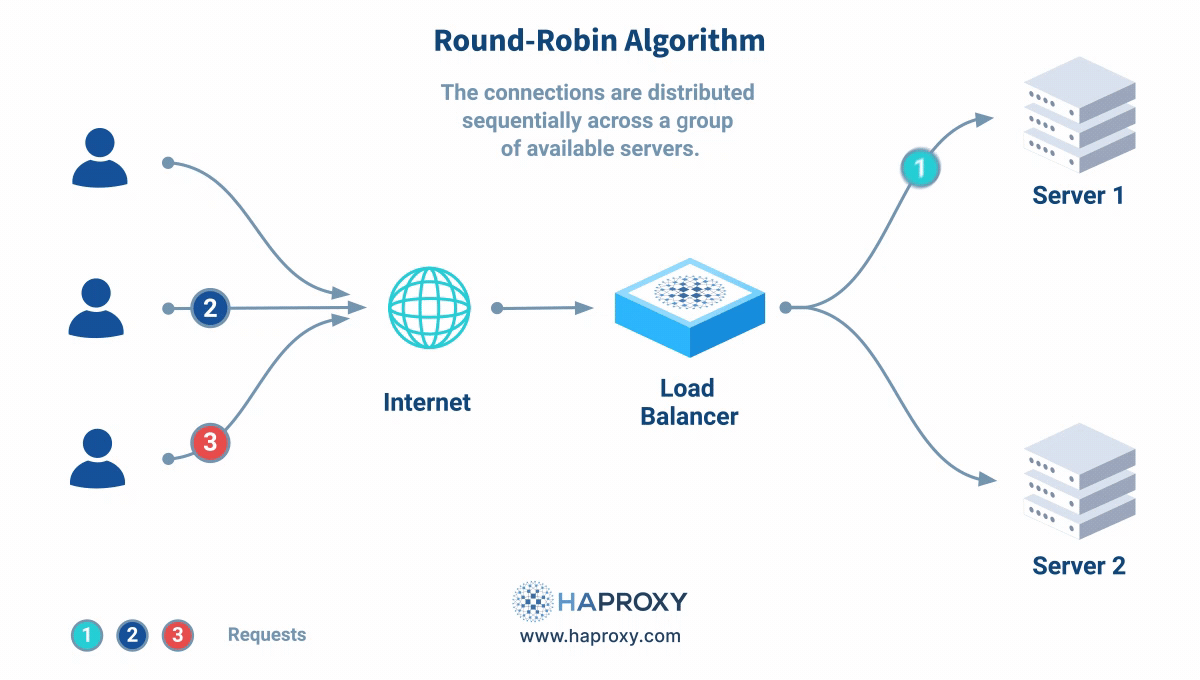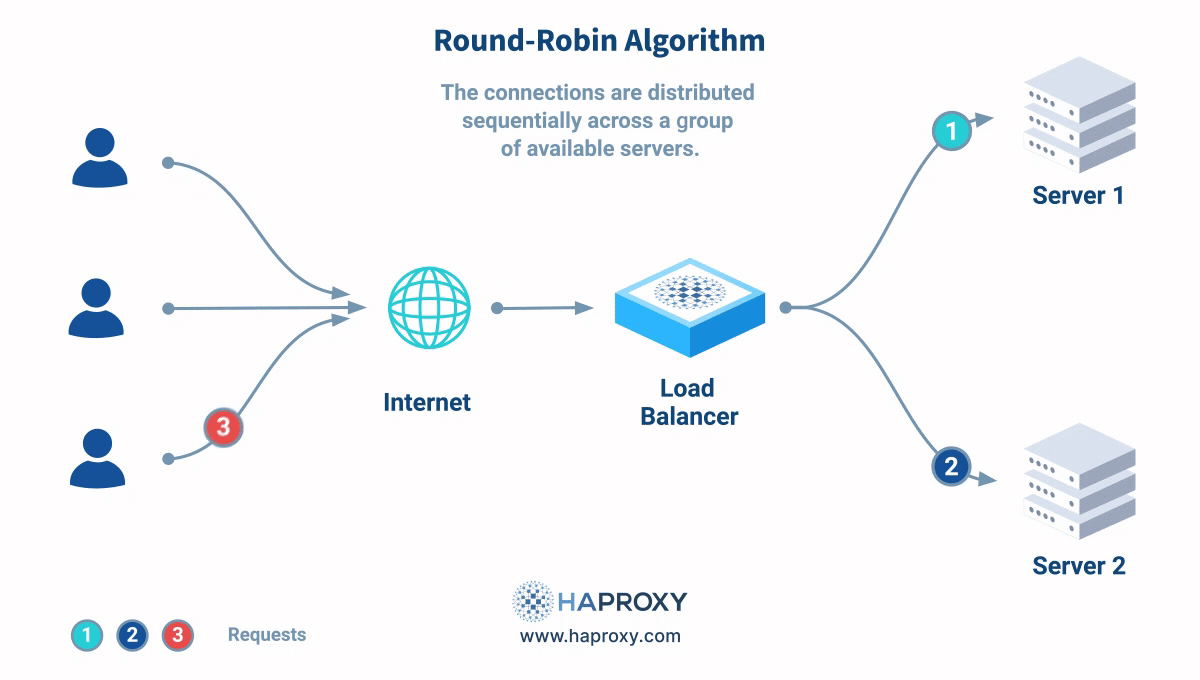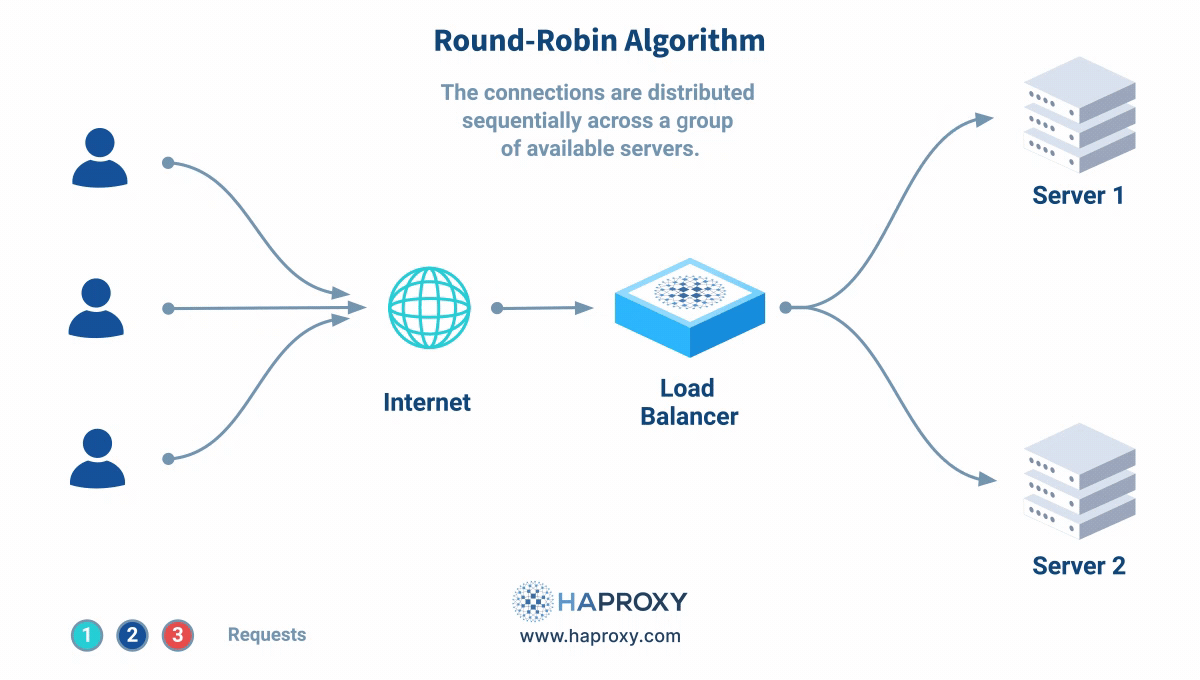
roundrobin
서버들을 순서대로 돌아가며 요청을 분배하는 방식으로서, 알고리즘의 기본값이다. -
leastconn
현재 활성 연결 수가 가장 적은 서버에 요청을 보낸다. 세션 길이나 연결 지속 시간이 긴 트래픽에 적합하다. -
source
클라이언트 IP 주소 등을 해싱하여 항상 같은 서버로 연결이 가도록 하는 방식(세션 지속성 확보용)이다.
2.2.5 Trade Off
HAProxy는 높은 처리량과 낮은 지연 시간을 확보할 수 있어 트래픽이 많거나 응답시간이 중요한 서비스에 유리하다. 고급 알고리즘, 라우팅 기능 덕분에 복잡한 트래픽 흐름(예시 : 다양한 서비스, API, 모바일/웹 분리 등)에도 유연하게 대응이 가능하다.
하지만 HAProxy의 구성 및 튜닝 난이도가 상대적으로 높을 수 있으며, 설정이 복잡하고 학습곡선이 있다는 점을 참고하길 바란다.
2.3 ACL(Access Control List) & Content-based Routing)
2.4 Session Persistence & Sticky Sessions
2.5 Health Check & Monitoring
2.6 고가용성(HA)
2.7 Event-driven, Non-blocking I/O
2.8 다계층 프로토콜 지원 (L4/L7)
3. HAProxy 동작 원리