
JPA 영속성 컨텍스트(Persistence Context)
-
정의
- JPA(Java Persistence API)는 자바 플랫폼에서 객체 지향 프로그래밍과 관계형 데이터베이스 사이의 차이를 메우기 위한 표준 ORM 기술 사양이다.
- 영속성 컨텍스트는 이러한 JPA 운영의 핵심이 되는 논리적 영역으로, 엔티티를 영속 상태로 저장하고 관리하는 가상의 데이터베이스 역할을 수행한다. 애플리케이션과 물리적인 데이터베이스 사이에서 객체의 생명주기를 완벽하게 제어하는 환경이라고 이해할 수 있다.
-
사용하는 이유
- 서비스 운영의 핵심은 데이터의 정합성과 안정적인 보존이다. 영속성 컨텍스트를 활용하면 비즈니스 로직을 수행하는 동안 객체의 상태 변화를 실시간으로 추적하고, 이를 가장 최적화된 시점에 데이터베이스에 반영할 수 있다.
- 또한, 반복적인 SQL 작성 업무를 획기적으로 줄여 개발 생산성을 높이는 동시에, 객체 지향적인 설계를 유지하면서도 관계형 데이터베이스의 강력한 기능을 모두 활용하기 위해 사용한다.
-
핵심 역할 및 특징
-
1차 캐시
-
영속성 컨텍스트 내부에 존재하는 메모리 저장소로, 엔티티의 식별자(@Id)를 키(Key)로, 엔티티 객체 자체를 값(Value)으로 보관한다.
-
동일한 트랜잭션 범위 내에서는 '단기 기억 장치' 역할을 수행하여 데이터베이스와의 통신 횟수를 비약적으로 줄인다.
-
동작 원리
- 1차 캐시 확인
- 애플리케이션에서 특정 엔티티를 조회하면, JPA는 가장 먼저 영속성 컨텍스트 내의 1차 캐시에서 해당 식별자를 가진 데이터가 있는지 확인한다.
- 캐시 히트 (Cache Hit)
- 찾고자 하는 데이터가 캐시에 이미 존재한다면, 데이터베이스에 쿼리를 날리지 않고 메모리에 있는 객체를 즉시 반환한다. (성능 이득 및 객체 동일성 보장)
- 캐시 미스 (Cache Miss)
- 캐시에 데이터가 없다면 그제야 데이터베이스에 SELECT 쿼리를 전달하여 데이터를 조회한다.
- 캐시 저장 및 반환
- 데이터베이스에서 가져온 데이터를 즉시 1차 캐시에 저장(영속화)하여 관리 상태로 만든 뒤, 사용자에게 반환한다. 이후부터 해당 데이터 조회는 2번(캐시 히트) 과정으로 처리된다.
- 1차 캐시 확인
-
-
영속 엔티티의 동일성(Identity) 보장
-
영속성 컨텍스트는 동일한 트랜잭션 내에서 조회하는 엔티티의 '참조 값'이 동일함을 보장한다. 이는 우리가 자바의
List나Map에서 객체를 꺼낼 때와 똑같은 원리로 작동한다. -
보장 가능한 이유
- 1차 캐시의 인스턴스 보관
- 영속성 컨텍스트 내부의 1차 캐시는 엔티티의 식별자(@Id)를 키로 하여 '이미 생성된 객체 인스턴스'를 그대로 들고 있다.
- 동일 인스턴스 반환
- 동일한 식별자로 조회를 요청하면, JPA는 데이터베이스를 다시 뒤지거나 새로운 객체를 생성하지 않고, 1차 캐시에 저장된 기존 객체의 메모리 주소(참조값)를 그대로 넘겨준다.
- 참조 비교(==)의 일치
- 결과적으로 두 번의 조회로 얻은 변수
a와b는 메모리 상의 같은 지점을 가리키게 된다. 따라서a == b비교 시 항상true가 반환되며, 애플리케이션 전반에서 데이터의 일관성이 깨지지 않도록 보호한다.
- 결과적으로 두 번의 조회로 얻은 변수
- 1차 캐시의 인스턴스 보관
-
영속 엔티티의 동일성(Identity)을 보장해야하는 이유
- 자바의 객체 지향 패러다임과 데이터베이스의 관계형 모델 사이의 간극을 좁히고, 트랜잭션 내에서 데이터의 신뢰할 수 있는
단일 진실 공급원(Single Source of Truth)을 제공하기 위함이다. - 상세 내용
- 데이터 정합성(Consistency)의 근간
- 만약 동일한 DB 행에 대해 서로 다른 두 객체가 생성된다면, A 객체를 수정해도 B 객체는 예전 상태를 유지하게 된다. 이 경우 어떤 객체를 기준으로 DB에 반영해야 할지 판단할 수 없는 데이터 불일치 오류가 발생한다.
- 비즈니스 로직의 단순화 및 안전성
- 개발자가 식별자(ID)를 일일이 비교하는 번거로운 로직을 짤 필요가 없다. 자바의 기본 비교 연산자(==)만으로 두 객체가 같은지 확신할 수 있어 코드의 가독성이 높아지고 논리적 오류가 줄어든다.
- 애플리케이션 레벨의 REPEATABLE READ 제공
- 데이터베이스의 격리 수준(Isolation Level)이 낮더라도, 영속성 컨텍스트 덕분에 한 트랜잭션 내에서는 항상 같은 상태의 객체를 조회할 수 있다. 이는 복잡한 계산 로직 중에 데이터가 변하는 것을 방지하는 강력한 보호막이 된다.
- 메모리 자원 및 가비지 컬렉션 최적화
- 동일한 데이터를 위해 중복된 객체 인스턴스를 생성하지 않으므로 메모리 낭비를 방지한다. 이미 존재하는 객체를 재사용함으로써 시스템 전체의 부하를 줄이는 효과가 있다.
- 데이터 정합성(Consistency)의 근간
- 자바의 객체 지향 패러다임과 데이터베이스의 관계형 모델 사이의 간극을 좁히고, 트랜잭션 내에서 데이터의 신뢰할 수 있는
-
-
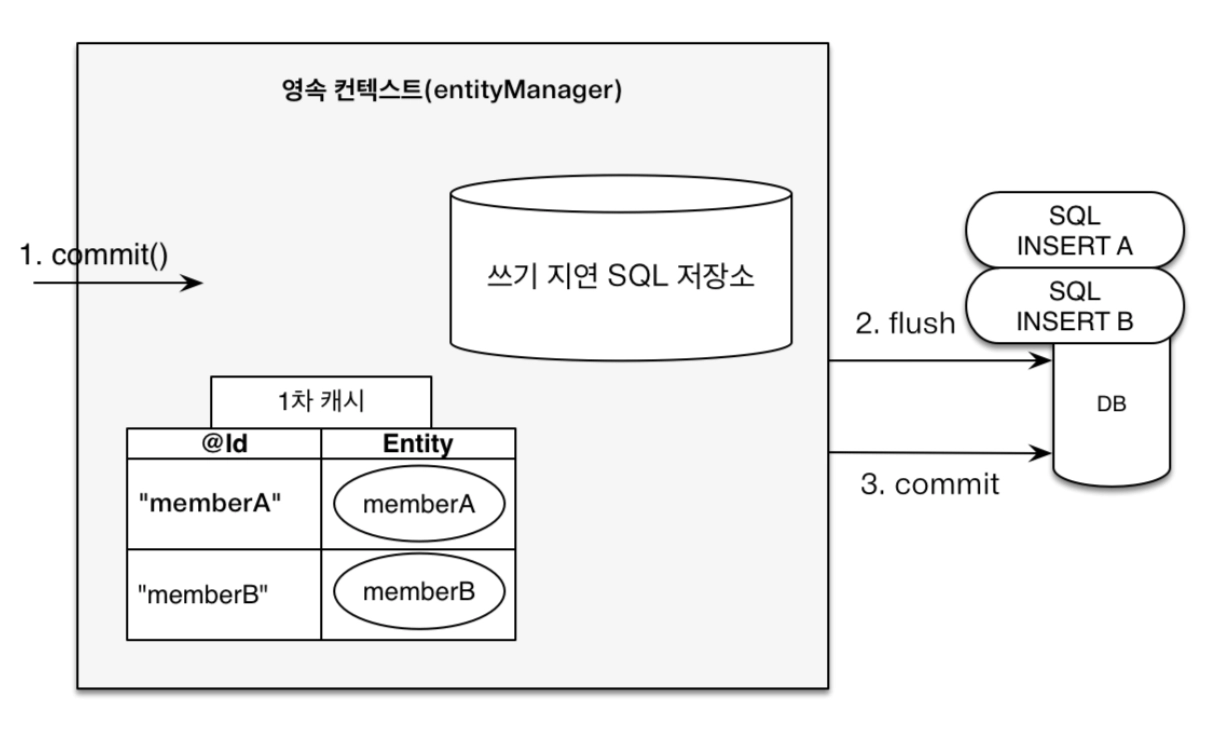
트랜잭션을 지원하는 쓰기 지연 (Transactional Write-behind)
-
엔티티의 생성, 수정, 삭제 요청이 발생할 때마다 즉시 데이터베이스에 쿼리를 보내지 않고, 영속성 컨텍스트 내부의 '쓰기 지연 SQL 저장소'에 차곡차곡 모아두었다가 트랜잭션이 커밋되는 순간 한꺼번에 실행하는 기술이다.
-
동작 원리
- 영속화 및 SQL 생성
em.persist(entity)와 같은 명령이 실행되면, 엔티티는 1차 캐시에 저장됨과 동시에 해당 작업을 수행하기 위한 SQL(INSERT, UPDATE, DELETE 등)이 생성된다.
- 쓰기 지연 SQL 저장소에 보관
- 생성된 SQL은 즉시 데이터베이스로 전송되지 않고, 영속성 컨텍스트 내부에 있는 별도의 쿼리 저장소에 쌓인다.
- 비즈니스 로직 연속 수행
- 쿼리를 보내고 응답을 기다리는 대기 시간 없이 다음 자바 로직을 즉시 수행한다. 이 과정에서 여러 개의 엔티티를 조작하더라도 모든 쿼리는 저장소에 계속 누적된다.
- 플러시(Flush) 및 일괄 처리
- 트랜잭션을 커밋(
tx.commit())하는 순간, JPA는 저장소에 모인 모든 쿼리를 데이터베이스에 한꺼번에 보낸다(Batching).
- 트랜잭션을 커밋(
- 트랜잭션 확정
- 모든 쿼리가 성공적으로 전송된 후 데이터베이스의 트랜잭션이 최종적으로 커밋되어 데이터가 영구적으로 반영된다.
- 영속화 및 SQL 생성
-
-
-
변경 감지(Dirty Checking)
-
엔티티의 필드값이 변경되면 이를 자동으로 감지하여 트랜잭션 종료 시점에 업데이트 쿼리를 실행한다. 개발자가 명시적인 수정 명령(update 등)을 내리지 않아도 데이터의 최신 상태를 유지하며, 객체 지향적인 프로그래밍을 가능하게 한다.
-
동작 원리
- 스냅샷(Snapshot) 생성
- 엔티티가 영속성 컨텍스트에 처음 들어온 시점(데이터베이스에서 조회하거나 새로 저장된 시점)의 상태를 그대로 복사하여 별도의 저장소인 스냅샷에 보관한다.
- 엔티티 데이터 수정
- 비즈니스 로직을 수행하면서 자바 객체의 필드 값을 변경한다. 이때 영속성 컨텍스트는 실시간으로 감시하는 것이 아니라, 객체의 참조 값만 가지고 있는다.
- 플러시(Flush) 호출
- 트랜잭션이 커밋되거나 수동으로 플러시가 호출되면, 영속성 컨텍스트는 현재 엔티티의 상태와 보관해두었던 초기 상태인 스냅샷을 일일이 비교한다.
- 변경 사항 확인 및 SQL 생성
- 비교 결과 값이 달라진 부분이 있다면 수정을 위한 UPDATE SQL을 생성하여 쓰기 지연 SQL 저장소에 보낸다. 만약 변경된 내용이 없다면 아무런 쿼리도 생성하지 않는다.
- 데이터베이스 반영
- 쓰기 지연 저장소에 담긴 수정 쿼리들이 데이터베이스로 전송되어 최종적으로 데이터가 업데이트된다.
- 스냅샷(Snapshot) 생성
-
-
지연 로딩(Lazy Loading)
-
실제 객체가 사용되는 시점까지 데이터 조회를 늦추는 기법이다. 연관된 데이터를 즉시 조회하지 않고 가짜 객체(Proxy)로 대체해 두었다가, 실제 데이터가 필요한 순간에만 DB를 조회하여 성능을 최적화한다.
-
동작 원리
- 프록시(Proxy) 객체 생성
- 엔티티를 조회할 때 연관된 엔티티 자리에 실제 데이터 대신 가짜 객체인 '프록시'를 채워 넣는다. 이 프록시는 실제 클래스를 상속받아 만들어진 껍데기 객체로, 겉모습은 실제 객체와 동일하다.
- 초기화 대기 상태
- 프록시 객체는 내부에 실제 객체의 참조(Target)를 보관할 공간을 비워둔 채로 영속성 컨텍스트에 머문다. 이때까지는 데이터베이스에 추가적인 쿼리가 발생하지 않는다.
- 데이터 접근 시도
- 비즈니스 로직에서 연관된 엔티티의 메서드(예: member.getName())를 호출하여 실제 값을 사용하려는 시도를 하면, 프록시 객체는 영속성 컨텍스트에 실제 데이터가 필요하다고 알린다.
- 영속성 컨텍스트의 DB 조회
- 영속성 컨텍스트는 1차 캐시를 확인하고 데이터가 없다면 데이터베이스에 SELECT 쿼리를 날려 실제 엔티티 객체를 생성한다.
- 프록시 초기화 및 데이터 반환
- 생성된 실제 엔티티를 프록시 내부의 참조(Target)에 연결한다. 이제 프록시는 자신을 호출한 요청을 실제 엔티티에게 전달하여 데이터를 반환한다. 이후부터는 이미 연결된 실제 객체를 사용하여 성능을 유지한다.
- 프록시(Proxy) 객체 생성
-
-
영속성 컨텍스트 핵심 역할의 이점 및 실무 적용 사례
-
1차 캐시 (First-level Cache)
- 이점
- 데이터베이스와의 물리적 통신 횟수를 획기적으로 줄여 시스템 응답 속도를 향상시킨다. 동일한 트랜잭션 내에서는 메모리상의 객체를 재사용하므로 불필요한 네트워크 비용을 제거한다.
- 실무 예시
- 사용자의 마이페이지를 구성할 때, 상단 프로필 영역과 하단 활동 내역 영역에서 각각 유저 정보를 조회하더라도 실제 DB 조사는 최초 1회만 발생하며, 이후 로직은 메모리에서 즉시 데이터를 참조하여 처리 속도를 극대화한다.
- 이점
-
영속 엔티티의 동일성(Identity) 보장
- 이점
- 같은 식별자를 가진 객체의 참조 주소값이 동일함을 보장하여 데이터 불일치(Stale Data) 문제를 원천 차단한다. 복잡한 비즈니스 로직 내에서 객체를 주고받아도 데이터의 정합성이 유지된다.
- 실무 예시
- 복잡한 금융 결제 시스템에서 '계좌' 객체를 여러 검증 메서드에 인자로 전달할 때, 각 메서드에서 수정된 잔액 정보가 동일한 인스턴스에 실시간으로 반영되어 최종 결제 시점에 정확한 합산 결과를 얻을 수 있다.
- 이점
-
트랜잭션을 지원하는 쓰기 지연 (Transactional Write-behind)
- 이점
- 쿼리를 모아 한꺼번에 전송하는 배치(Batch) 처리가 가능해져 데이터베이스 부하를 분산시킨다. 특히 DB 락(Lock) 점유 시간을 최소화하여 대규모 접속 환경에서의 병목 현상을 효과적으로 해소한다.
- 실무 예시
- 쇼핑몰 관리자가 1,000개의 상품 가격을 동시에 일괄 변경할 때, 1,000번의 수정 쿼리를 하나씩 보내지 않고 트랜잭션 종료 시점에 한 번에 전송하여 시스템의 가용성을 확보하고 처리량을 증대시킨다.
- 이점
-
변경 감지 (Dirty Checking)
- 이점
- 개발자가 별도의 업데이트 쿼리를 작성하거나 관리할 필요가 없어 코드의 가공 및 유지보수가 간결해진다. '수정 명령 누락'으로 인한 비즈니스 오류를 방지하여 개발 생산성과 안정성을 동시에 확보한다.
- 실무 예시
- 회원 정보 수정 페이지에서 이메일 주소만 바꿨을 때, 개발자가 "수정" 버튼에 대응하는 SQL을 일일이 만들지 않아도 객체의 필드 값 변경만으로 DB의 해당 행(Row) 정보가 자동 갱신되는 관리 도구에 활용된다.
- 이점
-
지연 로딩 (Lazy Loading)
- 이점
- 연관된 모든 데이터를 한 번에 가져오는 무거운 조회를 방지하여 애플리케이션의 초기 로딩 성능과 메모리 효율을 최적화한다. 실제 데이터가 필요한 순간에만 네트워크 통신을 발생시킨다.
- 실무 예시
- 배달 앱의 주문 목록 화면에서 주문 날짜와 총액 같은 기본 정보는 즉시 보여주고, 사용자가 특정 주문의 '상세 보기' 버튼을 눌러 하위 메뉴 리스트를 확인할 때 비로소 관련 데이터를 추가 조회하는 성능 최적화 기법에 적용된다.
- 이점
-
-
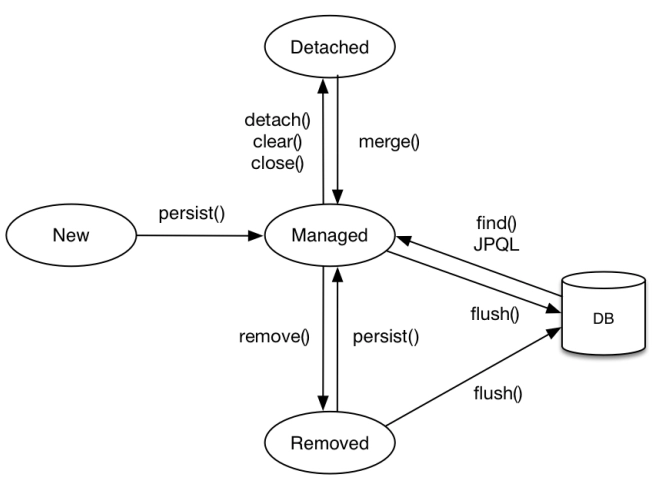
동작 원리 및 엔티티 생명주기 (Entity Lifecycle)
-
비영속 (New/Transient)
- 상세 설명
- 객체를 생성했지만 아직 데이터베이스 및 영속성 컨텍스트와는 아무런 관련이 없는 순수한 자바 객체 상태이다. 영속성 컨텍스트가 제공하는 1차 캐시, 변경 감지 등의 기능을 전혀 활용할 수 없으며 단지 메모리 상에만 존재한다.
- 특징
- 식별자(ID)값이 존재하지 않을 수 있으며, 이 상태에서 객체를 수정하더라도 데이터베이스에는 어떠한 영향도 미치지 않는다.
- 상세 설명
-
영속 (Managed)
- 상세 설명
- em.persist()를 호출하거나 조회를 통해 엔티티가 영속성 컨텍스트의 통제권 안에 들어온 상태이다. 이때부터 엔티티는 영속성 컨텍스트가 관리하는 '영속 객체'가 되며 1차 캐시에 등록된다.
- 특징
- 등록되는 시점에 최초 상태의 복사본인 스냅샷이 생성된다. 트랜잭션 종료 시 이 스냅샷과 현재 상태를 비교하여 변경 사항을 찾아내는 변경 감지(Dirty Checking)의 대상이 된다.
- 상세 설명
-
준영속 (Detached)
- 상세 설명
- 영속성 컨텍스트가 관리하던 엔티티가 어떤 사유로 인해 관리 대상에서 제외된 상태이다. 영속성 컨텍스트가 닫히거나(close), 초기화되거나(clear), 명시적으로 특정 엔티티를 분리(detach)할 때 발생한다.
- 존재 이유 (Why Detached?)
- 메모리 관리 및 자원 최적화: 영속성 컨텍스트가 모든 객체를 무한정 관리하면 메모리 부하가 발생하므로, 작업이 끝난 객체는 관리 목록에서 떼어내어 자원을 회수한다.
- 계층 간 데이터 전달: 서비스 계층에서 조회가 끝난 데이터를 컨트롤러나 뷰 계층으로 보낼 때, 더 이상 DB 연결을 유지할 필요가 없는 상태로 만들어 안전하게 데이터를 전달하기 위해 활용한다.
- 데이터 보존: 관리 대상은 아니지만 식별자를 가지고 있으므로, 나중에 다시 영속 상태로 병합(Merge)하여 수정한 내용을 DB에 반영할 수 있는 유연성을 제공한다.
- 상세 설명
-
삭제 (Removed)
- 상세 설명
- 엔티티를 데이터베이스에서 삭제하기로 마킹한 상태이다. 영속성 컨텍스트에서 해당 엔티티를 제거하며, 트랜잭션이 커밋되는 순간 실제 물리적인 DELETE 쿼리가 전송된다.
- 특징
- 삭제된 엔티티는 가급적 재사용하지 않는 것이 권장되며, 로직상 객체 자체가 소멸되는 절차의 시작점이다.
- 상세 설명
-
플러시 (Flush)
- 상세 설명
- 영속성 컨텍스트의 변경 내용을 실제 데이터베이스에 동기화하는 핵심 과정이다. 영속성 컨텍스트를 비우는 것이 아니라, 메모리의 논리적 상태를 DB의 물리적 상태와 일치시키는 작업이다.
- 동작 순서
- 변경 감지가 동작하여 영속 상태의 모든 엔티티를 스냅샷과 비교한다. 수정된 엔티티가 발견되면 수정 쿼리를 생성하여 쓰기 지연 SQL 저장소에 등록한다. 마지막으로 저장소의 모든 쿼리를 데이터베이스로 한꺼번에 전송한다.
- 상세 설명
-
-
JPA 엔티티 생명주기 제어 메서드 상세 분석
-
엔티티 등록 및 관리 (Registration)
- persist()
- 역할: 비영속(New) 상태의 객체를 영속(Managed) 상태로 전환한다.
- 설명: "이 객체를 이제부터 관리해달라"고 영속성 컨텍스트에 요청하는 명령이다. 호출 시 1차 캐시에 저장되며, 삭제(Removed) 상태인 객체에 호출하면 다시 관리 상태로 복구시킨다.
- persist()
-
관리 대상 제외 및 분리 (Severance)
- detach()
- 역할: 특정 엔티티만 준영속(Detached) 상태로 전환한다.
- 설명: 해당 엔티티에 대한 영속성 컨텍스트의 모든 관리(변경 감지 등)를 중단한다.
- clear()
- 역할: 영속성 컨텍스트를 완전히 초기화한다.
- 설명: 현재 관리 중인 모든 엔티티를 한꺼번에 준영속 상태로 만든다. 작업실의 책상을 깨끗이 비우는 것과 같다.
- close()
- 역할: 영속성 컨텍스트를 종료한다.
- 설명: 관리하던 모든 엔티티가 준영속 상태가 되며, 해당 컨텍스트가 점유하던 자원을 모두 반납한다.
- detach()
-
상태 복구 및 병합 (Re-linking)
- merge()
- 역할: 준영속(Detached) 상태의 엔티티 정보를 사용하여 새로운 영속 상태의 엔티티를 반환한다.
- 설명: 외부에서 수정되어 돌아온 객체의 값을 영속성 컨텍스트 안의 객체에 덮어씌울 때 사용한다. (주의: 전달한 객체가 영속화되는 것이 아니라, 영속화된 '새로운' 객체가 반환된다.)
- merge()
-
데이터 삭제 (Deletion)
- remove()
- 역할: 영속 상태의 엔티티를 삭제(Removed) 상태로 전환한다.
- 설명: 데이터베이스에서 해당 데이터를 삭제하기로 마킹하는 단계이다. 실제 물리적 삭제는 트랜잭션이 완료되는 시점에 발생한다.
- remove()
-
데이터 조회 (Retrieval)
- find() / JPQL
- 역할: 데이터베이스(DB)에서 데이터를 찾아 영속(Managed) 상태로 가져온다.
- 설명: 식별자로 직접 찾거나(find), 쿼리 언어를 통해 조건에 맞는 데이터를 검색(JPQL)하여 영속성 컨텍스트의 관리 하에 둔다.
- find() / JPQL
-
데이터 동기화 (Synchronization)
- flush()
- 역할: 영속성 컨텍스트의 변경 내용을 데이터베이스에 물리적으로 반영한다.
- 설명: 쓰기 지연 저장소에 쌓인 쿼리들을 DB로 전송한다. 트랜잭션 커밋 시 자동으로 호출되지만, 필요에 따라 명시적으로 호출하여 즉시 동기화할 수 있다.
- flush()
-
-
트레이드 오프
- 조회 효율성 vs 메모리 부하
- 1차 캐시를 통해 조회 성능을 획기적으로 높일 수 있지만, 하나의 트랜잭션에서 관리하는 엔티티의 양이 방대해질 경우 서버의 메모리 점유율이 급격히 상승할 수 있다.
- 개발 생산성 vs 내부 복잡도 이해
- SQL을 직접 다루지 않아 개발 속도가 매우 빨라지는 장점이 있는 반면, 영속성 컨텍스트의 복잡한 동작 메커니즘을 정확히 이해하지 못하면 원인을 알 수 없는 성능 저하나 데이터 불일치 문제에 직면할 수 있다.
- 추상화의 이점 vs 세밀한 제어의 어려움
- 표준화된 인터페이스를 통해 데이터베이스 교체가 용이해지지만, 특정 벤더에 최적화된 복잡한 쿼리나 대량의 배치 처리를 수행할 때는 직접 SQL을 다루는 것보다 성능 최적화가 까다로울 수 있다.
- 조회 효율성 vs 메모리 부하
-
주의 사항
- 엔티티 매니저의 스레드 안전성
- 엔티티 매니저는 스레드 간에 절대 공유해서는 안 된다. 여러 스레드가 동시에 접근할 경우 영속성 컨텍스트의 상태가 오염되어 예측 불가능한 데이터 손상이 발생할 수 있다.
- N+1 문제 및 지연 로딩 예외
- 연관 관계 조회 시 의도치 않게 수많은 쿼리가 발생하는 N+1 문제를 방지하기 위해 페치 조인을 적절히 사용해야 한다. 또한 준영속 상태에서 연관 데이터를 참조할 때 발생하는 예외 상황을 철저히 관리해야 한다.
- 병합(Merge) 기능의 위험성
- merge()는 준영속 상태의 엔티티를 다시 영속화할 때 모든 필드값을 덮어쓰는 특징이 있다. 만약 준영속 객체의 특정 필드가 비어 있다면 기존 데이터가 유실될 수 있으므로, 실무에서는 변경 감지를 통한 부분 수정을 권장한다.
- 대량 데이터 처리 최적화
- 수만 건 이상의 데이터를 한꺼번에 처리할 때는 영속성 컨텍스트에 메모리가 과부하되지 않도록 주기적으로 flush()와 clear()를 수행하여 작업대를 비워주어야 한다.
- 식별자 생성 전략에 따른 차이
- IDENTITY 전략을 사용할 경우 데이터베이스에 저장해야만 식별자를 얻을 수 있으므로, 예외적으로 쓰기 지연이 작동하지 않고 즉시 저장 쿼리가 실행된다는 점을 설계 시 고려해야 한다.
- 엔티티 매니저의 스레드 안전성
JPA Cache 체계
JPA Cache는 어떻게 관리될까?
1차 캐시 (First-level Cache)
- 정의
- 영속성 컨텍스트 내부에 존재하는 엔티티 저장소이다.
- 역할
- 트랜잭션이 유지되는 동안 한 번 조회한 객체를 메모리에 보관한다.
- 똑같은 데이터를 다시 요청하면 DB에 가지 않고 메모리에서 즉시 반환하여 동일성을 보장한다.
스냅샷 (Snapshot)
- 정의
- 엔티티가 영속성 컨텍스트에 처음 들어온 시점의 상태 복사본이다.
- 역할
- 변경 감지(Dirty Checking)의 기준점이 된다.
- 트랜잭션이 끝날 때 현재 객체의 상태와 이 스냅샷을 비교하여, 바뀐 부분이 있다면 자동으로 업데이트 쿼리를 생성한다.
쓰기 지연 SQL 저장소 (Action Queue)
- 정의
- 실행될 SQL 쿼리들을 모아두는 임시 대기 큐이다.
- 역할
- 엔티티를 수정하거나 삭제할 때 즉시 DB로 보내지 않고 이곳에 쌓아둔다.
- 트랜잭션이 커밋되는 순간(Flush) 모여있던 쿼리들을 한꺼번에 보냄으로써 네트워크 비용을 최적화한다.
프록시 (Proxy)
- 정의
- 실제 객체 대신 들어가는 가짜 대역 객체이다.
- 역할
- 지연 로딩(Lazy Loading)을 가능하게 하는 핵심 장치이다.
- 연관된 데이터가 실제로 사용되는 시점까지 DB 조회를 미루다가, 데이터가 필요한 순간에만 진짜 데이터를 채워 넣는다.
2차 캐시 (Second-level Cache)
- 정의
- 애플리케이션 전체에서 공유되는 공용 캐시 영역이다.
- 역할
- 1차 캐시가 트랜잭션이 끝나면 사라지는 것과 달리, 애플리케이션이 종료될 때까지 유지된다.
- 여러 사용자가 공통으로 자주 조회하는 데이터를 담아두어 DB 부하를 획기적으로 줄인다.
구성 요소 간의 관계 요약
| 요소 | 관리 범위 | 주요 이점 |
|---|---|---|
| 1차 캐시 | 트랜잭션 단위 | 객체 동일성 보장, 재조회 성능 향상 |
| 스냅샷 | 트랜잭션 단위 | 변경 사항 자동 감지 (개발 편의성) |
| 쓰기 지연 저장소 | 트랜잭션 단위 | 네트워크 통신 최적화 (Batch 처리) |
| 프록시 | 객체 단위 | 불필요한 데이터 로딩 방지 (메모리 절약) |
| 2차 캐시 | 애플리케이션 단위 | 전역적인 DB 부하 감소 |
캐시 체계 비교 일람
| 구분 | JPA 캐시 (1차/2차) | Redis (전역 캐시) | MySQL 캐시 (버퍼 풀) |
|---|---|---|---|
| 위치 | 애플리케이션 내부 (Java 메모리) | 애플리케이션 외부 서버 | 데이터베이스 서버 내부 |
| 데이터 형태 | 자바 객체 (Entity) | 키-값 (다양한 데이터 구조) | 데이터 페이지 (파일 블록) |
| 공유 범위 | 해당 서버 내부만 공유 | 모든 서버가 공통으로 공유 | 해당 DB를 쓰는 요청만 공유 |
| 관리 주체 | 개발자 및 ORM 프레임워크 | 개발자가 직접 로직 설계 | DB 엔진이 알아서 관리 |
