
02. 파이썬스러운 코드
프로퍼티, 속성(Attribute)과 객체 메서드의 다른 타입들
public, private와 같은 접근 제어자를 가지는 다른 언어들과는 다르게 파이썬 객체의 모든 속성과 함수는 public이다. 즉 호출자가 객체의 속성을 호출하지 못하도록 할 방법이 없다.
엄격한 강제사항은 아니지만 파이썬에는 변수명 지정과 관련하여 몇 가지 네이밍 컨벤션이 있다. 그 중에 하나로 밑줄로 시작하는 속성은 private 속성을 의미한다는 것이 있는데, 외부에서 호출되지 않기를 기대한다는 의미이다.
파이썬에서의 밑줄
파이썬에서 밑줄을 사용하는 몇 가지 규칙과 구현 세부 사항들을 살펴보자
앞서 언급했듯이 기본적으로 객체의 모든 속성은 public이다.
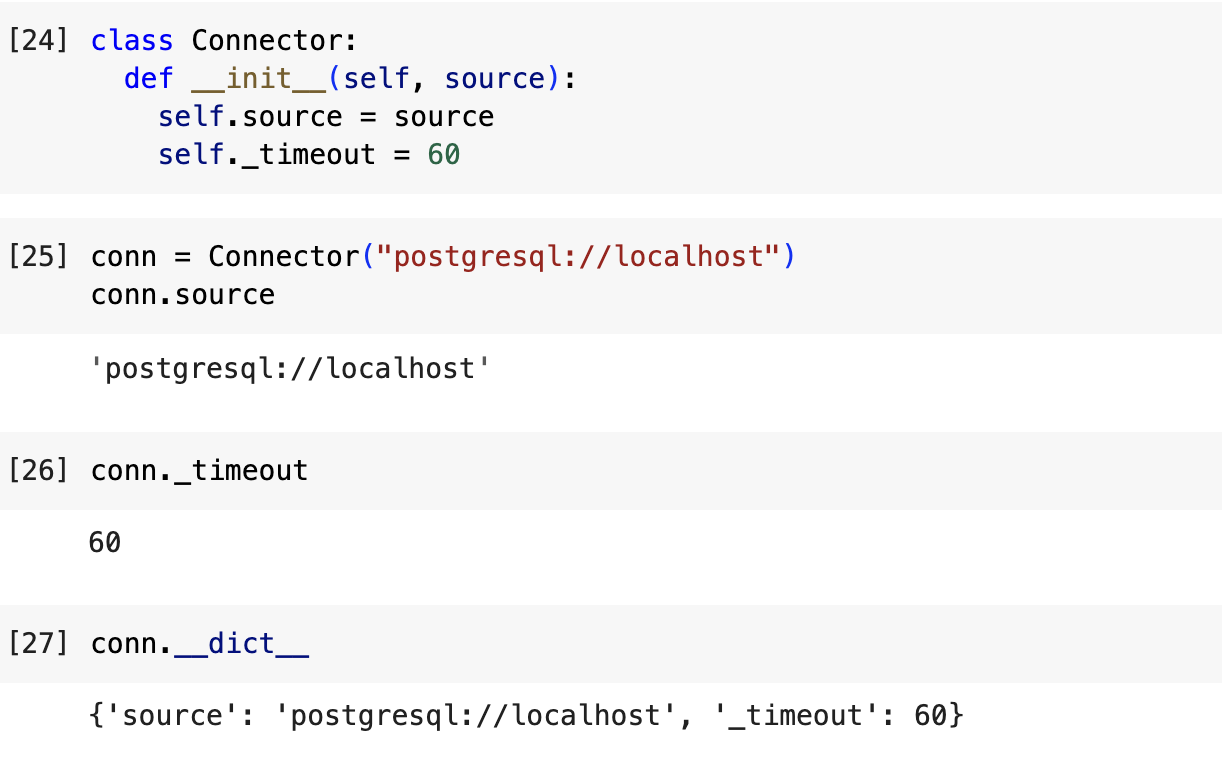
여기서 Connector 객체는 source 파라미터를 사용해 생성되며 source와 timeout이라는 두 개의 속성을 가진다. 전자는 public이고 후자는 private이다. 그러나 예제와 같이 두 속성 모두 접근 가능하다.
코드를 해석해보면 _timeout은 connector 자체에서만 사용되고 호출자는 이 속성에 접근하지 않아야 한다. 즉 timeout 속성은 내부에서만 사용하고 바깥에서는 호출하지 않을 것이므로 외부 인터페이스를 고려하지 않고 언제든 안전하게 리팩토링할 수 있다.
클래스는 외부 호출 객체와 관련된 속성과 메서드만을 노출해야 한다. 즉 객체의 인터페이스로 공개하는 용도가 아니라면 모든 멤버는 접두사로 하나의 밑줄을 사용하는 것이 좋다.
너무 많은 내부 메서드와 속성을 사용하는 것은 해당 클래스가 너무 많은 일을 하고 있고 단일 책임 원칙을 준수하지 않았다는 신호일 수 있다. 이는 일부 책임을 다른 클래스로 추출해야 함을 의미할 수 있다.
밑줄 두 개를 사용하여 private로 만들 수 있다고들 하지만, 이것은 name mangling(이름 맹글링)으로 이중 밑줄을 사용한 변수의 이름을
_<class_name>__<attribute-name>형태로 변경하는 것이다.
만약_timeout을__timeout으로 변경했으면,conn._Connector__timeout으로 접근이 가능하다.
반대로 객체의 일부 속성을 public으로 공개하고 싶은 경우에 대해서는 프로퍼티를 사용한다.
프로퍼티
일반적으로 객체 지향 설계에서는 도메인 엔티티를 추상화하는 객체를 만든다. 이러한 객체는 어떤 동작이나 데이터를 캡슐화할 수 있다. 그리고 종종 데이터의 정확성이 객체를 생성할 수 있는지 여부를 결정한다. 다시 말하면, 일부 엔티티는 데이터가 특정 값을 가질 경우에만 존재할 수 있고, 잘못된 값을 가진 경우에는 존재할 수 없다.
이것이 유효성 검사 메서드를 만드는 이유이다. 파이썬에서는 프로퍼티를 사용하여 이러한 setter와 getter 메서드를 더 간결하게 캡슐화할 수 있다.
아직 이해가 어렵지만 예제를 통해서 살펴보면 이해하기가 쉽다.
일반적으로 데이터를 읽어주는 메서드를 getter, 데이터를 변경해주는 메서드를 setter라고 한다.
이해한바로는 private 객체를 읽거나 변경할 일이 생길 때, getter와 setter를 이용하여 일종의 데이터 검사를 하는 방식이라 이해함. 일반적으로는 setter에서 유효성 검사를 실시함.
@property 데코레이터로 먼저 해당 객체에 대한 정의를 진행하고 후에 @<객체이름>.setter 또는 .getter 데코레이터로 유효성 검사를 실시할 수 있다.
프로퍼티 예제
좌표 값을 처리하는 지리 시스템을 생각해보자. 위도와 경도는 특정 범위에서만 의미가 있다. 해당 범위를 벗어나는 좌표는 존재할 수 없다. 좌표를 나타내는 객체를 생성할 수 있지만, 어떤 값을 사용할 때는 항상 허용 가능한 범위 내에 있는지 확인해야 한다. 이런 경우 프로퍼티를 사용할 수 있다.
class Coordinate:
def __init__(self, lat: float, long: float) -> None:
self._latitude = self._longitude = None
self.latitude = lat
self.longitude = long
@property
def latitude(self) -> float:
return self._latitude
@latitude.setter
def latitude(self, lat_value: float) -> None:
if lat_value not in range(-90, 90 + 1):
raise ValueError(f"유효하지 않은 위도 값: {lat_value}")
self._latitude = lat_value
@property
def longitude(self) -> float:
return self._longitude
@longitude.setter
def longitude(self, long_value: float) -> None:
if long_value not in range(-180, 180 + 1):
raise ValueError(f"유효하지 않은 경도 값: {long_value}")
self._longitude = long_value여기에서 프로퍼티는 latitude와 longitude를 정의하기 위해 사용했다. 이렇게 함으로 private 변수에 저장된 값을 반환하는 별도의 속성을 만들었다. 더 중요한 것은 사용자가 다음과 같은 방법으로 이러한 속성 중 하나를 수정하려는 경우이다.
coordinate.latitude = <new-latitude-value> # #longitude에 대해서도 동일하게 수정 가능@latitude.setter 데코레이터로 선언된 유효성 검사 로직이 자동으로 호출되며 명령문의 오른쪽에 있는 값 <new-latitude-value>이 파라미터로 전달된다.
객체의 모든 속성에 대해 get, set 메서드를 작성할 필요는 없다. 대부분의 경우 일반 속성을 사용하는 것으로 충분하다. 속성 값을 가져오거나 수정할 때 특별한 로직이 필요한 경우에만 프로퍼티를 사용하자.
위 예제에서는 내부 데이터를 일관성 있고 투명하게 관리하기 위해 프로퍼티가 어떻게 도움이 되는지 살펴보았다.
때로는 객체의 상태나 내부 데이터에 따라 어떤 계산을 하고 싶은 경우가 있을 수도 있다. 이런 경우에도 프로퍼티가 좋은 선택이다.
예를 들어, 특정 포맷이나 데이터 타입으로 값을 반환해야 하는 객체가 있는 경우 프로퍼티를 사용할 수 있다. 이전 예제에서 소수점 이하 네 자리까지의 좌표 값을 반환하기로 했다면 값을 읽을 때 호출되는 @property 메서드에서 반올림하는 계산을 만들 수 있다.
# 이전 예제
class Coordinate:
...
@property
def latitude(self) -> float:
return round(self._latitude, 4)프로퍼티는 명령-쿼리 분리 원칙(command and query separation - CC08)을 따르기 위한 좋은 방법이다. 명령-쿼리 분리 원칙은 객체의 메서드가 무언가의 상태를 변경하는 커맨드이거나, 무언가의 값을 반환하는 쿼리이거나 둘 중에 하나만 수행해야지 둘 다 동시에 수행하면 안 된다는 것이다.
즉 메서드는 한 가지만 수행해야 한다. 작업을 처리한 다음 상태를 확인하려면 메서드를 분리해야 한다.
보다 간결한 구문으로 클래스 만들기
파이썬에는 객체의 값을 초기화하는 일반적인 보일러플레이트 코드가 있다.
보일러플레이트 : 모든 프로젝트에서 공통적으로 반복해서 사용되는 코드
__init__ 메서드에 객체에서 필요한 모든 속성을 파라미터로 받은 다음 내부 변수에 할당하는 것 일반적으로 다음과 같은 형태로 작성한다.
def __init__(self, x, y, ...):
self.x = x
self.y = y파이썬 3.7부터는 dataclasses 모듈을 사용하여 위 코드를 훨씬 단순화할 수 있다.
dataclasses 모듈은 @dataclass 데코레이터를 제공한다. 이 데코레이터를 클래스에 적용하면 모든 클래스의 속성에 대해서 마치 __init__ 메서드에서 정의한 것처럼 인스턴스 속성으로 처리한다.
@dataclass 데코레이터를 사용하면 __init__ 메서드를 자동으로 생성하므로 또 다시 __init__ 메서드를 구현할 필요가 없다.
또한 dataclasses 모듈은 field라는 객체도 제공한다. 이 field 객체는 해당 속성에 특별한 특징이 있음을 표시한다. 예를 들어 속성 중 하나가 리스트처럼 변경 가능한 데이터 타입인 경우 __init__에서 비어 있는 리스트를 할당할 수 없고 대신에 None으로 초기화한 다음에 인스턴스마다 적절한 값으로 다시 초기화를 해야 한다. mylist = [] 처럼 할당하면 에러가 발생한다.
여기서 field 객체를 사용하면 default_factory 파라미터에 list 객체를 전달하여 초기값을 지정할 수 있다. default_factory에 전달되는 객체는 호출 가능한 객체(callable)이어야 하고, 초기화 시 특별한 값을 지정하지 않는다면 비어 있는 인자와 함께 해당 객체를 호출한다.
mylist = field(default_factory=list)와 같이 지정하면 속성이 있고 아이템이 없는 상태로 초기화된다.
위와 같이
@dataclass를 사용하면 객체 초기화 시 mylist 값을 따로 지정하지 않았다면, mylist = list() 처럼 데코레이터가 초기화 해준다.
예제 : R-Trie 자료 구조에 대한 노드 모델링
R-Trie 자료 구조와 알고리즘은 문자열에 대한 빠른 검색을 위해 사용되는 구조와 알고리즘이다.
이 자료 구조는 현재의 문자를 나타내는 value와 다음에 나올 문자를 나타내는 next 배열을 가지고 있다.
next 배열의 각 원소는 다음 노드에 대한 참조 값이다.(linked list와 비슷) 예를 들어, a로 시작하는 단어 집합을 표현하려는 경우 value에 a가 저장되고 next_에는 이어지는 문자의 종류별로 R-Trie노드에 대한 참조가 저장된다.
from typing import List
from dataclasses import dataclass, field
R = 26
@dataclass
class RTrieNode:
size = R
value: int
next_: List["RTrieNode"] = field(default_factory=lambda: [None] * R)
def __post_init__(self):
if len(self.next_) != self.size:
raise ValueError(f"리스트(next_)의 길이가 유효하지 않음")먼저 R-Trie를 영어 알파벳으로 정의하기 위해 R=26으로 정의했다. 이제 단어들의 정보를 저장하려면 next_ 배열에서 다음 문자를 나타내는 위치에 해당 알파벳 노드의 참조 값을 저장하면 된다.
첫 번째 속성인 size는 어노테이션이 없으므로 일반적인 클래스 속성으로 처리된다. 즉 모든 객체가 값을 공유한다. 이렇게 하는 것이 헷갈린다면, size = field(init=False) 와 같은 방법으로 할 수도 있지만 위와 같이 하는 것이 더 간결하다.
size 다음에는 어노테이션을 가진 두 개의 다른 속성이 있다.
첫 번째 value는 정수형이지만 기본 값은 가지고 있지 않다. 따라서 객체 생성 시 반드시 값을 정해줘야 한다.
두 번째 next_는 변경 가능한 list 타입의 속성이며 field 객체를 사용해 초기값을 지정하고 있다. 여기서는 R 크기 만큼의 슬롯을 가진 배열로 초기화하고, 각 배열의 아이템은 모두 None 값을 갖는다.
정리하자면
@dataclass데코레이터를 사용하면__init__메서드에서 모든 변수의 이름을 반복해서 작성하는 번거로움 없이 간편하게 데이터 클래스를 만들 수 있다.
복잡하게 유효성 검사를 하거나 특별한 변환을 하지 않는 데이터를 저장하려는 경우 이러한 데이터 클래스가 좋은 대안이 될 수 있다. 다만, 어노테이션이 데이터 변환을 해주지는 않는다는 점을 명심하라고 저자는 말한다.
예를 들어 float 타입이거나 integer 타입이어야만 한다면 __init__ 메서드 안에서 이 변환을 해야 한다. 어노테이션만을 사용해서 데이터 클래스로 구현하면 나중에 발견하기 힘든 미묘한 오류를 일으킬 수 있다.
아마도 데이터 컨테이너나 래퍼 클래스의 용도로 사용되는 모든 경우에 데이터 클래스가 유용할 것이다. 네임드튜플이나 네임스페이스의 대안을 찾고 있다면 데이터 클래스를 고려해보자
이터러블 객체
파이썬에는 기본적으로 반복 가능한 객체가 있다. 예를 들어 list, tuple, set, dict은 특정한 형태의 데이터를 보유할 수 있을 뿐만 아니라 for 루프를 통해 반복적으로 값을 가져오는데 사용될 수도 있다. 그러나 이러한 내장 반복형 객체만 for 루프를 사용할 수 있는 것은 아니다. 나만의 반복 로직을 가진 이터러블을 직접 만들 수 있다. 이터러블은 __iter__ 매직 메서드를 구현한 객체, 이터레이터는 __next__ 매직 메서드를 구현한 객체를 말하기 때문에 두 메서드를 자체적으로 구현하면 나만의 반복 로직을 가지는 객체를 만들 수 있다.
python의 반복은 iterable 프로토콜이라는 자체 프로토콜을 사용해 동작한다.
for e in myobject:형태로 객체를 반복할 수 있는지 확인하기 위해 파이썬은 고수준에서 다음 두 가지를 차례로 검사한다.
1. 객체가__next__,__iter__메서드 중 하나를 포함하는지 여부
2. 객체가 시퀀스이고__len__,__getitem__을 모두 가졌는지 여부
이터러블 객체 만들기
객체를 반복하려고 하면 파이썬은 해당 객체의 iter()함수를 호출한다. 이 함수가 처음으로 하는 것은 해당 객체에 __iter__ 메서드가 있는지를 확인하는 것이다. 만약 있으면 __iter__ 메서드를 실행한다.
from datetime import timedelta
class DateRangeIterable:
"""자체 이터레이터 메서드를 가지고 있는 이터러블 """
def __init__(self, start_date, end_date):
self.start_date = start_date
self.end_date = end_date
self._present_day = start_date
def __iter__(self):
return self
def __next__(self):
if self._present_day >= self.end_date:
raise StopIteration()
today = self._present_day
self._present_day += timedelta(days=1)
return today
이 객체는 한 쌍의 날짜를 통해 생성되며 다음과 같이 해당 기간의 날짜를 반복하면서 하루 간격으로 날짜를 표시한다.
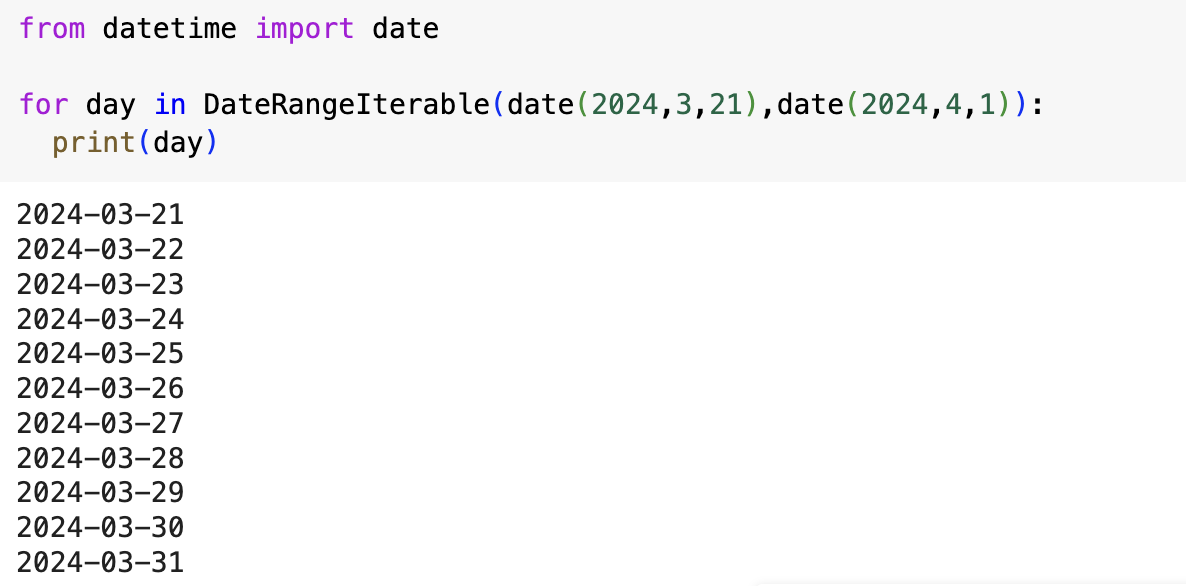
for loop는 앞서 만든 객체를 사용해 새로운 반복을 시작한다. 이제 파이썬은 iter()함수를 호출하고 iter()함수는
__iter__매직 메서드를 호출한다.__iter__는 self를 반환하고 있으므로 객체 자신이 이터러블임을 나타내고 있다. 따라서 루프의 각 단계에서마다 자신의 next() 함수를 호출 ->__next__호출 -> 더 이상 생산할 것이 없을 경우 파이썬에게 StopIteration 예외를 발생시키는 방식으로 for 루프가 작동한다.
마치며
이번 장을 통해서 프로퍼티와 데이터클래스 데코레이터를 통해서 public, private를 python에서 구현하는 방식과 클래스의 init을 간결하게 작성하는 방법을 배우고 iterator를 만드는 방법까지 배울 수 있었다. 이를 통해 더욱이 파이썬스러운 코딩이 가능해질 것이라 기대한다.
