
파이썬 클린 코드
03. 좋은 코드의 일반적인 특징
상속
객체 지향 소프트웨어를 디자인할 때, 가장 일반적으로 사용되는 개념은 "상속"이다. 보통 필요한 클래스들의 계층 구조를 만들고 각 클래스가 구현해야 하는 메서드를 결정하는 것으로부터 개발을 시작한다.
상속은 강력한 개념이지만 부모 클래스를 확장하여 새로운 클래스를 만들 때마다 부모와 강하게 결합된 새로운 클래스가 생긴다는 점이다. 소프트웨어를 설계할 때, 결합력(coupling)을 최소한으로 줄이는 것이 중요하다.(그래야 유지보수가 쉽기 때문이다.)
상속을 가장 많이 사용하는 이유는 코드의 재사용 기능이다. 코드의 재사용을 염두에 두어야 하지만 단지 부모 클래스에 있는 메서드를 공짜로 얻을 수 있기 때문에 상속을 하는 것은 좋지 않은 생각이라 말한다. 코드를 재사용하는 올바른 방법은 여러 상황에서 동작 가능하고 쉽게 조합할 수 있는 응집력 높은 객체를 사용하는 것이다.
상속이 좋은 선택인 경우
파생 클래스를 만드는 것은 양날의 검이 될 수 있으므로 주의해야한다. 부모 클래스의 메서드를 공짜로 전수 받을 수 있는 장점과 불필요하게 너무 많은 기능을 추가하게 되는 단점이 공존한다.
새로운 하위 클래스를 만들 때, 클래스가 올바르게 정의되고 있는지를 확인하고 싶다면 상속된 모든 메서드를 실제로 사용할 것인지 생각해보는 것이 좋다. 만약 대부분의 메서드를 필요로 하지 않고 재정의하거나 대체해야 한다면 다음과 같은 이유로 설계상의 실수라고 할 수 있다.
- 상위 클래스는 잘 정의된 인터페이스 대신 막연한 정의와 너무 많은 책임을 가졌다.
- 하위 클래스는 확장하려고 하는 상위 클래스와 적절한 세분화가 아니다.
상속을 잘 사용한 좋은 예는 다음과 같다. public 메서드와 속성을 인터페이스로 잘 정의한 클래스가 있다. 그리고 이 클래스와 같은 기능을 하지만 일부 기능을 수정하거나 새로운 것을 추가하고 싶어서 상속을 한 경우다.
인터페이스 정의는 상속의 또 다른 좋은 예이다.어떤 객체에 인터페이스 방식을 강제하고자 할 때 세부 구현을 하지 않은 기본 추상 클래스를 만들고, 실제 이 클래스를 상속하는 하위 클래스에서 적절한 구현을 하도록 하는 것이다.
마지막으로 다른 사용 예는 Exception이다. 파이썬 표준 예외는 Exception에서 파생되는 것을 알 수 있는데, 이것은 except Exception:같은 일반 구문을 통해 모든 에러를 catch할 수 있게 해준다. 이는 모든 예외가 Exception에서 상속받은 클래스라는 것이다.
파이썬에서 상속이 좋은 선택인 경우 3가지를 살펴봤다. 정리하자면,
1. 클래스와 같은 기능을 하지만 일부 기능을 수정하거나 새로운 것을 추가하고 싶은 경우
2. 세부 구현이 없는 기본 추상 클래스를 만들고, 실제 이 클래스를 상속하는 하위 클래스에서 적절한 구현을 하는 경우
3. 파이썬 Exception의 경우상속 기능을 요약하면 파생된 클래스는 부모 클래스와 유사한 기능을 전문화 했거나, 부모 클래스보다 좀 더 구체화된 추상화를 해야 한다.
상속 안티패턴
부모 클래스는 새롭게 파생된 클래스의 public 선언의 일부를 담당한다. 왜냐하면 부모 클래스의 public 메서드가 그대로 자식 클래스로 상속되기 때문이다. 이러한 이유로 자식 클래스의 public 메서드는 부모 클래스에서 정의한 것과 일관성을 가져야한다.
예를 들어, BaseHTTPRequestHandler를 상속 받은 클래스가 handle() 메서드를 구현했다면 이것은 부모 메서드를 오버라이딩한 것이므로 일관성에 아무 문제가 없고, HTTP 요청과 관련된 것으로 보이는 메서드가 추가되었다면, 부모 자식 간에 일관성을 갖고 있다고 생각할 수 있다. 하지만, 예를 들어 process_purchase()와 같은 HTTP와 무관해 보이는 메서드가 추가 되었다면 이것은 올바른 상속이라고 볼 수 없다.
앞으로 살펴볼 예제로 도메인 문제를 해결하기 위해 만든 자료 구조를 그대로 객체로 활용하는 경우를 살펴볼텐데, 이는 파이썬의 전형적인 안티패턴을 보여준다.
예제
여러 고객에게 다양한 정책을 적용하는 보험 시스템을 생각해보자. 먼저 이후 처리를 하기 전에 정책을 적용하려는 대상의 고객 정보를 메모리로 불러와야 한다. 새로운 고객 정보를 저장하고, 변경된 정책을 반영하고, 일부 데이터를 수정하는 등의 기본적인 연산이 필요하다. 또한 어떤 작업 중에 정책이 변경되면 해당 트랜잭션에 묶이 고객들에게 변경사항을 반영할 수 있도록 배치 작업 또한 지원해야 한다.
필요한 데이터 구조를 생각해 보면 특정 고객의 정보에 상수 시간에 접근할 수 있어야 한다. 따라서 policy_transaction[customer_id]처럼 구현하는 것이 멋진 인터페이스처럼 보인다. 이런 점을 생각하면 subscriptable 객체, 딕셔너리 타입의 객체를 상속받는 것이 좋아보인다.
잘못된 예
import collections
from datetime import datetime
class TransactionalPolicy(collections.UserDict):
"""잘못된 상속의 예시"""
def change_in_policy(self, customer_id, **new_policy_data):
self[customer_id].update(**new_policy_data)
이렇게 클래스를 설계하면 cusomer_id로 고객의 정보를 조회할 수 있다.

이렇게 처음 원했던 기능을 구현하게 됐다. 그렇지만 비용 측면에서 살펴보면 문제를 확인할 수 있다.
dir(policy)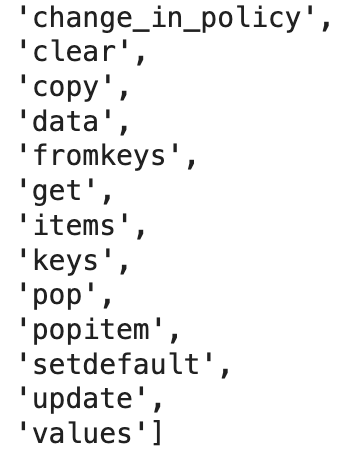
이 클래스에는 불필요한 수많은 메서드가 포함되어 있다.(UserDict에 있는 메서드들...)
이 디자인에는 적어도 두 가지의 주요 문제점을 볼 수 있다.
-
잘못된 계층 구조
- 기본 클래스에서 새 클래스를 만드는 것은 말 그대로 그것이 개념적으로 확장되고 세부적인 것이라는 것을 의미한다.
TransactionalPolicy라는 이름만 보고 딕셔너리 타입이라는 것을 알기가 어렵다. 사용자가 객체의 public 인터페이스를 통해 노출된 public 메서드들을 확인하게 되면 전문화가 잘못 되었다고 생각할 것이다.
- 기본 클래스에서 새 클래스를 만드는 것은 말 그대로 그것이 개념적으로 확장되고 세부적인 것이라는 것을 의미한다.
-
결합력(coupling) 문제
TransactionalPolicy는 이제 딕셔너리의 모든 메서드를 포함한다.TransactionalPolicy에pop()또는items()와 같은 메서드들은 실제로 필요하지 않다. 이것들은 public 메서드들이므로 이 인터페이스의 사용자는 부작용이 있을지도 모르는 이 메서드들을 호출할 수 있다. 게다가 딕셔너리 타입을 확장함으로써 얻는 이득도 별로 없다.
이것이 구현 객체를 도메인 객체와 혼합할 때 발생하는 문제이다. 딕셔너리는 특정 유형의 작업에 적합한 객체 또는 데이터 구조로서 다른 데이터 구조와 마찬가지로 트레이드오프가 있다. TransactionalPolicy는 특정 도메인의 정보를 나타내는 것이므로 해결하려는 문제의 일부분에 사용되는 엔티티여야만 한다.
동일한 계층에 자료구조를 구현한 것과 도메인 클래스를 혼합해서 사용하지 말자
이러한 구현 클래스는 새롭거나 보다 구체적인 기능을 구현하는 경우에만 사용해야 한다. 위 예시에서는 좀 더 구체적이거나, 약간 수정된 딕셔너리가 필요할 때에만 딕셔너리를 확장해야 했다. 동일한 논리 구조로 도메인 클래스에 대해서도 적용된다.
해결책
올바른 해결책은 컴포지션을 사용하는 것이다. TransactionalPolicy자체가 딕셔너리가 되는 것이 아니라 딕셔너리를 활용하는 것이다. 딕셔너리를 private 속성에 저장하고 __getitem__()으로 딕셔너리 proxy를 만들고 나머지 필요한 public 메서드를 추가적으로 구현하는 것이다.
class TransactionalPolicy:
"""컴포지션을 사용한 리팩토링 예제 """
def __init__(self, policy_data, **extra_data):
self._data = {**policy_data, **extra_data}
def change_in_policy(self, customer_id, **new_policy_data):
self._data[customer_id].update(**new_policy_data)
def __getitem__(self, customer_id):
return self._data[customer_id]
def __len__(self):
return len(self._data)이 방법은 개념적으로 정확할 뿐만 아니라 확장성도 뛰어나다. 현재 딕셔너리인 데이터 구조를 향후 변경하려고 해도 인터페이스만 유지하면 사용자는 영향을 받지 않는다. 이는 결합력을 줄이고 파급 효과를 최소화하며 보다 나은 리팩토링을 허용하고 코드를 유지 관리하기 쉽게 만든다.
파이썬 다중상속
파이썬은 다중 상속을 지원한다. 다중 상속 역시 양날의 검이다. 다중 상속이 어떻게 동작하는지, 복잡한 계층구조에서 메서드의 호출은 어떻게 결정되는지 살펴보며, 다중 상속을 이해해보도록 하자.
메서드 결정 순서(MRO)
다중 상속에서 모호해지는 것은 두 개의 부모 클래스가 같은 이름의 메서드를 가진 경우 어떤 메서드를 사용해야 할지 모호해지는 문제가 있다. 다음 예시를 통해서 다중 상속 구조를 살펴보자
class BaseModule:
module_name = "top"
def __init__(self, module_name):
self.name = module_name
def __str__(self):
return f"{self.module_name} : {self.name}"
class BaseModule1(BaseModule):
module_name = "module_1"
class BaseModule2(BaseModule):
module_name = "module_2"
class BaseModule3(BaseModule):
module_name = "module_3"
class ConcreteModuleA12(BaseModule1, BaseModule2):
"""1과 2 확장"""
class ConcreteModuleB23(BaseModule2,BaseModule3):
"""2와 3 확장 """{kind=link}
출력 결과와 충돌이 발생하지 않았다. 파이썬은 MRO라는 알고리즘을 통해 인 문제를 해결한다.
믹스인(mixin)
믹스인은 코드를 재사용하기 위해 일반적인 행동을 캡슐화해 놓은 부모 클래스이다. 일반적으로 믹스인 클래스 자체만으로는 유용하지 않고, 믹스인 클래스만 확장하는 경우에도 큰 의미가 없다. 왜냐하면 믹스인 클래스는 대부분 다른 클래스의 메서드나 속성과 결합하여 사용되기 때문이다. 보통은 다른 클래스와 믹스인 클래스를 다중 상속하고, 믹스인 클래스의 메서드와 속성을 다른 클래스에서 활용한다.
예시
문자열을 받아서 하이픈(-)으로 구분된 값을 반환하는 파서를 생각해보자.
class BaseTokenizer:
def __init__(self, str_token):
self.str_token = str_token
def __iter__(self):
yield from self.str_token.split("-")

여기까지는 매우 직관적이다. 이제 기본 클래스를 변경하지 않고 값을 대문자로 변환해보자. 이는 간단한 예제로 새로운 클래스를 만들 수도 있지만 많은 클래스가 이미 BaseTokenizer를 확장했고 모든 클래스를 바꾸고 싶지는 않다고 해보자. 이러한 변환 작업을 처리하는 계층 구조에 새로운 클래스를 만들어서 mix할 수 있다.
class UpperIterableMixin:
def __iter__(self):
return map(str.upper, super().__iter__())
class Tokenizer(UpperIterableMixin, BaseTokenizer):
passTokenizer는 믹스인안에서 __iter__를 호출하고 __iter__는 다시 super() 메서드를 호출하여 변환을 마친 다음 BaseTokenizer에 전달한다. 이때는 이미 대문자를 전달하기 때문에 원하는 결과를 얻어낼 수 있다.
상속에 대해서는 응집력과 결합력의 키워드가 중요하다.
함수와 메서드의 인자
파이썬은 여러 가지 방법으로 함수의 인자를 받도록 정의할 수 있으며 사용자도 여러 가지 방법으로 인자를 제공할 수 있다. 또한 업계에서 널리 사용되고 있는 인자 정의에 대한 관행이 있다.
인자는 함수에 어떻게 복사되는가
파이썬은 항상 모든 인자를 값에 의해 전달(pass by value) 해야 한다. 함수에 값을 전달하면 함수의 서명에 있는 변수에 할당하고 나중에 사용한다. 함수는 파라미터의 데이터 타입에 따라 값을 변경하기도 하고 변경하지 않기도 한다. 만약 변경 가능한(mutable)객체를 전달했는데 함수 안에서 값을 변경했다면, 실제로 파라미터의 내용이 변경되는 부작용이 발생한다.
예시
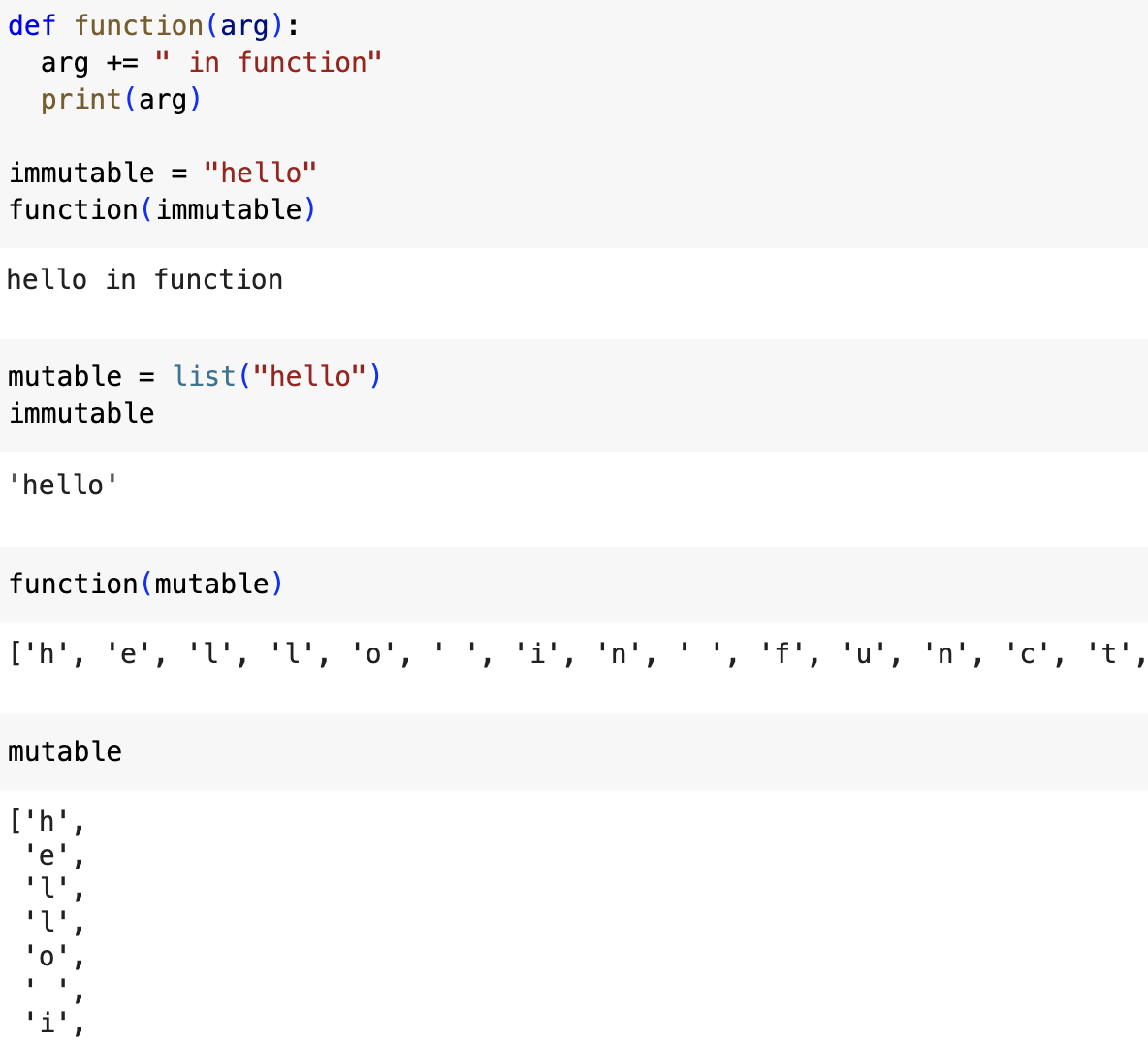
첫 번째 문자열을 전달하면 함수의 인자에 할당한다. string 객체는 immutable 타입이므로 "arg + = <expression>" 문장은 사실 "arg+<expression>"형태의 새로운 객체를 만들어서 arg에 다시 할당한다. 이 시점에서 arg는 단지 함수 스코프 내에 있는 로컬 변수이며 호출자의 원래 변수와는 아무런 관련이 없다.
반면에 mutable 객체인 리스트를 전달하면 해당 문장은 다른 의미를 갖는다(실제로는 list의 extend()를 호출하는 것과 같다). 이 연산자는 원래 리스트 객체에 대한 참조를 통해 값을 수정하므로 함수 외부에서도 값을 수정할 수 있다.
list의 참조 값이 함수에 값 형태로 전달된다. 하지만 그 값 자체가 참조이기 때문에 원본 list 객체를 변경하고 있으므로 함수 호출이 끝난 뒤에도 변경된 값이 남아있게 된다. 마치 이런 코드를 실행하는 것과 비슷하다.

이러한 유형(mutable)파라미터를 사용한다면 예상치 못한 부작용을 유발할 수 있으므로 주의해야 한다. 이러한 방식으로 변경하는 것이 꼭 필요한 상황이 아니라면 가급적 다른 대안을 찾아야 한다.
함수 인자를 함수 안에서 변경하지 말자, 최대한 함수 호출을 통해 발생할 수 있는 부작용을 회피하자.
가변인자
파이썬은 다른 언어와 마찬가지로 가변 인자를 사용할 수 있는 내장 함수와 구조를 가지고 있다. 문자열 연산을 위해 % 연산자 또는 format 메서드를 사용하는 경우이다. 파이썬에서 제공하는 이러한 함수를 사용하는 대신에 비슷한 방식으로 동작하는 자신만의 가변 함수를 만들 수도 있다.
가변 인자 함수를 위한 몇 가지 권장사항과 함께 기본 원칙들을 한 번 살펴보자.
가변 인자를 사용하려면 해당 인자를 패킹(packing)할 변수의 이름 앞에 별표(*)를 사용한다. 이것은 파이썬의 패킹 메커니즘에 따른 것이다.
예시
3개의 위치 인자를 갖는 함수가 있다고 가정해보자. 함수에서 기대하는 순서대로 리스트의 값을 편리하게 전달할 수 있다. 첫 번째 요소에 list[0] 두 번째 요소에 list[1] ... 이것은 전혀 파이썬스러운 코드가 아니긴 하지만 여기서 패킹 기법을 사용하면 하나의 명령어로 전달할 수 있다.

패킹 기법의 장점은 다른 방향으로도 동작한다는 것이다. 리스트의 값을 각 위치별로 변수에 언패킹하려면 다음과 같이 할당 할 수 있다.
a, b, c = [1,2,3]부분적인 언패킹도 가능하다. 시퀀스의 첫 번째 값과 나머지에 관심이 있다고 가정해보자. 이런 경우 첫 요소를 할당하고 나머지는 리스트로 패킹할 수 있다.



변수 언패킹의 가장 좋은 사용 예는 반복이다. 일련의 요소를 반복해야 하고 각 요소가 차례로 있다면 각 요소를 반복할 때 언패킹하는 것이 좋다. 이러한 동작을 살펴보기 위한 예시로 데이터베이스의 결과를 리스트로 받는 함수를 가정해보자.
from dataclasses import dataclass
USERS = [
(i, f"first_name_{i}", f"last_name_{i}")
for i in range(1_000)
]
@dataclass
class User:
user_id: int
first_name: str
last_name: str
def bad_users_from_rows(dbrows)->list:
"""DB 레코드로부터 User를 생성하는 파이썬스럽지 않은 나쁜 코드 """
return [User(row[0],row[1],row[2]) for row in dbrows]
def users_from_rows(dbrows)->list:
"""DB 레코드로부터 User 만들기 """
return [
User(user_id, first_name, last_name)
for (user_id, first_name, last_name) in dbrows
]또한 User 객체를 생성할 때 튜플의 모든 위치 인자를 넘기려면 다음과 같이 할 수도 있다.
[User(*row) for row in dbrows]
자체 함수를 디자인할 때 이러한 종류의 기능을 활용할 수 있다.
표준 라이브러리에 있는 max 함수를 예로 들면 max함수의 정의는 다음과 같다.

비슷한 표기법으로 이중별표를 키워드 인자에 사용할 수 있다. 이중 별표를 사용하면 딕셔너리의 key값을 파라미터 이름으로 사용하고, 딕셔너리의 value값을 파라미터 값으로 사용한다는 의미이다.
예를 들어 function(**{"key":"value"})는 다음과 동일한 표기이다. function(key="value")
반대로 이중 별표로 시작하는 파라미터를 함수에 사용하면 반대 현상이 벌어진다. 키워드 제공 인자들이 딕셔너리로 패킹된다.

이는 함수에 전달할 값을 동적으로 생성할 수 있게 해주는 정말 강력한 기능이다. 그러나 이 기능을 남용하면 코드의 가독성이 떨어질 수 있다.
함수의 정의에 이중 별표 인자를 사용한다는 것은 임의의 키워드 인자를 허용한다는 것이고 이런 경우 파이썬은 우리가 임의로 접근할 수 있는 딕셔너리를 만들어준다. 다만 이 딕셔너리에서 직접 어떤 값을 추출하는 용도로 사용하는 것을 추천하지 않는다. 즉, 딕셔너리에서 특정 키로 인자 값을 조회하지말고, 필요한 경우 함수의 정의에서 직접 꺼내도록 하자
예를 들어
def function(**kwargs):# 안 좋은 예
timeout = kwargs.get("timeout",DEFAULT_TIMEOUT)함수의 서명에서 파이썬이 직접 언패킹을 하고 기본 값을 설정하도록 하는 것이 좋다고 한다.
def function(timeout=DEFAULT_TIMEOUT, **kwargs): # 좋은 예위치 전용 인자(positional-only)
위치 인자는 함수의 앞 쪽에 제공되는 인자이다. 인수의 값은 함수에 정의된 순서에 따라 차례로 인식된다.
함수 인자를 정의할 때 특별한 구문을 사용하지 않았다면, 기본적으로 위치 또는 키워드로 전달할 수 있다.
def my_function(x,y):
print(f"{x=}, {y=}")
my_function(1,2)
my_function(x=1,y=2)
# 역순으로도 가능
my_function(y=2,x=1)
my_function(1,y=2)위 예시에 있는 호출방법 모두 동일한 효과를 가진다.
심지어 역순으로도 인자를 전달할 수 있다. (이 방법에서는 인수 하나를 키워드로 전달했다면, 나머지도 키워드로 전달해야한다.)
반드시 위치 인자만을 사용하도록 하고 싶다면 마지막 위치 전용 인자의 끝에 /를 추가하면 된다.
def my_function(x,y,/):
위치 전용 인자를 사용한 경우 인자에서 특별한 의미를 찾으려고 하지 말자.
키워드 전용(keyword-only) 인자
위치 전용 인자와 유사하게 일부 인수를 키워드 전용으로 만들 수도 있다. 키워드 전용 인자는 를 사용하여 그 시작을 알린다. 함수 서명에서 뒤에 오는 것들은 키워드 전용 인자가 된다. 아래 예에서 *args 다음에 오는 kw1, kw2가 키워드 전용 인자이다.
예를 들어 다음 함수 정의는 두 개의 위치 인자를 받고 다음에 임의의 개수만큼 위치 인자를 사용한다. 그 다음에 마지막에 2개의 인자가 바로 키워드 전용 인자이다. 마지막 인자 kw2는 기본값을 가지고 있는데 필수 사항은 아니다.
def my_function(x,y, *args, kw1, kw2=0):
print(f"{x=}, {y=}, {kw1=}, {kw2=}")
my_function(1,2, kw1=3, kw2=4)
my_function(1,2,kw1=3)이제 함수가 어떻게 동작하는지 명확하게 알 수 있다. 처음 두 개 이후에 더 이상의 위치 인자를 원하지 않으면 args 대신 를 넣으면 된다.
args를 사용하면
my_function(1,2,3, kw=4)처럼 위치 인자와 키워드 인자 사이에 임의의 개수만큼 위치 인자를 사용할 수 있지만, 로 정의했을 경우는 딱 2개의 위치 인자만 사용 가능하다.
함수 인자의 개수
너무 많은 인자를 사용하는 함수나 메서드는 code-smell의 징후이며 나쁜 디자인의 코드이다.
인자가 너무 많다는 것은 추상화를 빼먹었기 때문일 수 있다. 이는 구체화를 통해 전달하는 모든 인자를 포함하는 새로운 객체를 만들어서 해결할 수 있다.
또는, 가변 인자나 키워드 인자를 사용하여 동적 서명을 가진 함수를 만들어서 해결할 수 있다. 그러나 남용하게되면 매우 동적이게 돼서 유지보수가 힘들 수 있다.
예시
간단한 예시로 해결할 수 있는 방법을 생각해보자
다음과 같은 함수를 보면 모든 파라미터가 request와 관련이 있어보인다.
track_request(request.headers, request.ip_addr, request.request_id)이런 경우에는 그냥 request를 파라미터로 전달하는 것이 좋다.
track_request(request)이런 간단한 방법을 먼저 생각해보고 최후의 수단으로 함수의 서명을 변경하여 다양한 인자를 허용할 수 있다. 인자가 너무 많을 경우 *args 또는 **kwargs를 사용할 수 있지만, 함수 자체를 이해하기가 어려워질 수 있기 때문에 인터페이스에 대해서 적절히 문서화를 하고 인터페이스를 올바르게 구현했는지 확실히 해야 한다.
가장 일반화된 인자(
*args또는**kwargs)는super()를 통해 파라미터를 그대로 부모에 전달해야 하는 wrapper 클래스나 파라미터에 독립적으로 동작해야 하는 데코레이터와 같은 경우에만 사용하자
소프트웨어 디자인 우수 사례 결론
좋은 소프트웨어 디자인이란 소프트웨어 엔지니어링의 우수 사례를 따르고 언어에서 제공하는 대부분의 장점을 잘 활용하는 디자인이다. 파이썬이 제공하는 모든 기능을 잘 활용하는 것은 큰 가치가 있겠지만, 이것 또한 남용하는 것은 좋지 않으며 복잡한 기능을 단순한 디자인에 억지로 끼워넣으려고 한다면 큰 위험이 발생할 수도 있다.
소프트웨어 독립성(orthogonality)
모듈, 클래스 또는 함수를 변경하면 수정한 컴포넌트가 외부 세계에 영향을 미치지 않아야 한다. 이것이 불가능하다 하더라도 항상 최소화하려고 시도해야 한다.
코드 구조
코드를 구조화하는 방법은 팀의 작업 효율성과 유지보수성에 영향을 미친다.
특히 여러 정의가 들어있는 큰 파일을 만드는 것은 좋지 않다. 좋은 코드라면 유사한 컴포넌트끼리 정리하여 구조화해야 한다.
대부분의 경우 파이썬에서 대용량 파일을 작은 파일로 나누는 것은 어려운 작업이 아니다. 만약 코드의 여러 부분이 해당 파일의 정의에 종속되어 있어도 전체적인 호환성을 유지하면서 패키지로 나눌 수 있다.
해결 방법은 __init__.py 파일을 가진 새 디렉토리를 만드는 것이다.
마치며
3장에서는 클린 디자인을 위한 몇 가지 원칙들을 알아보았다.
- DbC(계양에 의한 디자인)
- 방어적 프로그래밍
- 어설션(assertion)
- 상속
- 함수의 인자
이들을 통해서 파이썬 상속과 함수에서 모르고 있었던 기능들을 알게되고 전체적인 디자인 구조를 생각할 수 있게 됐다. 하지만 무엇이든 남용하면 코드의 가독성이 떨어지기 때문에, 꼭 필요한 경우에 사용해야함을 명심해야겠다.
