Word2Vec 논문을 스터디할 때 썼던 글을 올린다.
모델에 대한 자세한 수식, 이해보다는 흐름을 살펴보았다.
! 오역/의역이 있을 수 있습니다.
Abstract
매우 많은 data sets에서, 단어들의 연속적인 벡터 표현을 계산하는 두 개의 model architectures를 제안한다.
단어 유사도 검사로 quality가 측정되며, 결과는 이전에 Neural Networks에서 제일 좋은 성능을 보이던 기술들과 비교한다.
더 작은 계산 비용을 통해 크게 향상된 정확도를 볼 수 있었다.
16억 단어 데이터 세트에서 고품질의 word vectors를 학습하는 데에 하루도 걸리지 않았다.
이 벡터가 구문, 의미론적 단어 유사성을 측정할 때 최첨단 성능을 제공한다는 것을 보여준다.
1 Introduction
현재 많은 NLP 시스템들과 기술들에서 단어를 atomic units(원자 단위)로 다룬다.
여러 이유가 있다. 간단함, 강인함, 많은 데이터로 학습한 간단한 모델이 적은 데이터로 학습한 복잡한 모델보다 낫다 등등..
그러나, 간단한 기법은 한계에 다다랐다. 성능은 고품질의 speech data 양에 크게 좌우되었다.
기계 번역에서, 현존하는 corpora(말뭉치)들은 몇 십억개, 혹은 이보다 적은 단어들로 구성되어 있다.
그러므로, 우리는 좀 더 발전된 기법에 초점을 맞춰야 한다.
최근 기계 학습의 발전으로, 더 복잡한 모델을 더 많은 데이터 set에 대해 학습하는 것이 가능해졌고, 이들은 일반적으로 간단한 모델들을 능가한다.
1.1 Goals of the Paper
이 논문의 목표는 거대한 데이터 sets에서 고품질의 word vectors를 학습할 수 있는 기술을 소개하는 것이다.
현재 표현되는 벡터의 quality를 측정하기 위해, 우리는 최근에 제안된 기술들을 사용한다. 기술에 의하면, 유사한 단어가 서로 근접하는 경향이 있을뿐만 아니라, 여러 수준의 유사성을 가진다고 기대할 수 있다
이는 굴절 언어(inflectional languages)에서 일찍이 관찰되었다.
예를 들어, 명사는 여러 개의 단어 어미(word endings)를 가질 수 있다. 우리가 원 vector space에서 유사한 단어를 검색하면, 유사한 어미를 갖는 단어들을 찾을 수 있다.
놀랍게도, 이 단어 표현의 유사성은 단순한 통사적 규칙을 뛰어넘는다는 것이 발견됐다.
v = vector
v(king) - v(man) + v(woman) = v(queen)
이 논문에서, 단어 간의 선형 규칙성을 보존하는 새로운 model architecture를 개발해 이 vector operation의 정확도를 최대화할 것이다.
우리는 구문 규칙성과 의미 규칙성을 모두 측정하기 위한 새로운 포괄적인 테스트 set을 디자인하고, 이 규칙성을 높은 정확도로 학습할 수 있음을 보여준다.
훈련 시간과 정확도가 word vectors의 차원과 training data의 양에 따라 어떻게 달라지는 지에 대해서도 논의한다.
1.2 Previous Work
연속적인 벡터들로 단어들을 표현하는 것은 긴 역사를 갖고 있다.
인기있는 모델인 NNLM(Neural Network Language Model)은 이어지는 word vector들을 표현하고 통계적인 언어 모델을 학습할 때, linear projection layer and a non-linear hidden layer를 가진 피드포워드 신경망이 사용되었다. 많은 이들이 이를 따라했다.
word vectors가 많은 NLP 애플리케이션을 크게 개선하고 단순화하는 데 사용할 수 있다는 것이 최근 밝혀졌다.
word vectors를 추정하는 작업은 다른 모델 구조들에서 다양한 데이터 뭉치에서 학습되었고, 몇몇 word vectors의 결과는 향후 연구와 비교에 사용할 수 있다. 그러나 우리가 아는 한, 이런 구조들은 훨씬 더 많은 계산 비용이 들었다.
2 Model Architectures
잘 알려진 잠재 의미 분석(LSA, Latent Semantic Analysis)과 잠재 디리클레 할당(LDA, Latent Dirichlet Allocation)을 포함하여 단어의 연속적인 표현을 추정하기 위해 많은 다양한 유형의 모델이 제안되었다.
서로 다른 모델 아키텍처를 비교하기 위해, 모델을 완전히 훈련시키기 위해 모델의 계산 복잡도를 매개 변수로 정의한다. 다음으로, 우리는 계산 복잡도를 최소화하면서 정확도를 극대화하도록 노력할 것이다.
계산 복잡도 공식~~
2.1 Feedforward Neural Net Language Model (NNLM)
확률론적 피드포워드 신경망 언어 모델
입력, 투영, 숨겨진 레이어, 출력 레이어로 구성된다.
H x V의 복잡도가 제일 크지만, 어휘의 이진트리 표현을 사용하면 V는 log2(V) 정도로 내려간다.
따라서 대부분의 복잡도는 N x D x H에 의해 발생합니다.
2.2 Recurrent Neural Net Language Model (RNNLM)
반복 신경망 기반 언어 모델은 문장 길이(모델 N의 순서) 지정 필요성과 같은 피드포워드 NNLM의 특정 한계를 극복하기 위해 제안되었다. 왜냐하면 이론적으로 RNN은 얕은 신경망보다 더 복잡한 패턴을 효율적으로 나타낼 수 있기 때문이다.
RNN 모델에는 projection 레이어가 없으며 입력, 숨김, 출력 레이어만 있다.
반복 모델 -> 일종의 단기 메모리를 형성한다.
H x V는 계층적 softmax를 사용하여 H x log2(V)로 내려간다.
따라서 대부분의 시간복잡도는 H x H에서 발생한다.
2.3 Parallel Training of Neural Networks
대규모 데이터 세트에 대한 모델을 교육하기 위해, 우리는 피드포워드 NNLM과 본 논문에서 제안된 새로운 모델을 포함하여, DistBelief라는 대규모 분산 프레임워크[6]에 여러 모델을 구현했다.
이 DistBelief 프레임워크를 통해 각 복제본을 병렬로 실행한다.
훈련시 Adagrad라는 adaptive learning rate와, mini-batch 비동기 경사하강법(asynchronous gradient descent)을 사용한다.
3 New Log-linear Models
여기서, 우리는 분산 표현 단어들(강아지 귀엽다.. 비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 가진다.)을 배울 때, 계산복잡도를 최소화하는 두 개의 모델 구조를 제안할 것이다.
이전의 섹션에서 대부분의 복잡도는 모델의 non-linear hidden layer에서 발생했다.
우리는 데이터를 효율적으로 학습시키는 더 간단한 모델을 연구했다.
3.1 Continuous Bag-of-Words Model (CBOW)
앞에서 살펴본 NNLM과 비슷하지만, non-linear hidden layer가 제거됨.
그리고, 미래의 단어들도 사용했다.
앞뒤 n개의 단어들을 이용해 가운데 단어 유추 (n은 hyperparameter)
3.2 Continuous Skip-gram Model
CBOW와 비슷. 현재 단어를 문맥에서 유추하는 대신, 현재 단어를 input으로 해서 (현재 단어 전후의) 특정 범위 안의 단어를 예측
range 늘리면 word vectors의 quality 올라갈 뿐만 아니라, 계산 복잡도도 늘어남(increase).
일반적으로 멀리 있는 단어가 현재 단어와 연관성이 적기 때문에, 훈련에서 그 단어들을 덜 샘플링함으로써 멀리 있는 단어들에 weight을 작게 준다.
4 Results
다른 버전의 word vectors들과 quality 비교
v는 벡터
v(bigger) - v(big) + v(small) = v(smallest) 가능
여러 분야에서 응용 가능하다.
4.1 Task Description
평가 방식 설명
4.2 Maximization of Accuracy
사용한 데이터: Google News corpus(텍스트 집합으로 구성된 언어 리소스)
학습 데이터 수, 임베딩 차원 증가에 따라 대체적으로 성능 향상
4.3 Comparison of Model Architectures
기존의 RNNLM, NNLM과 우리가 만든 CBOW, Skip-gram 성능 비교
CBOW, Skip-gram 성능이 좋다.
CBOW는 Semantic(의미론) 정확도가 높고,
Skip-gram은 Syntactic(구문론) 정확도가 높았다.
4.4 Large Scale Parallel Training of Models
분산 연산 framework인 DistBelief 사용
mini-batch asynchronous gradient descent(미니배치 비동기 경사하강법) 사용
Adagrad(adaptive learning rate procedure) 사용
NNLM보다 CBOW, Skipgram의 성능이 더 좋았다.
4.5 Microsoft Research Sentence Completion Challenge
Microsoft 문장 완성시키기 대회(Microsoft Sentence Completion Challenge)에선 1040개의 문장들로 이루어져 있고, 한 단어가 빠져있을 때 5개의 보기 중 가장 일관성이 있는 단어를 선택한다. (빈칸찾기 문제)
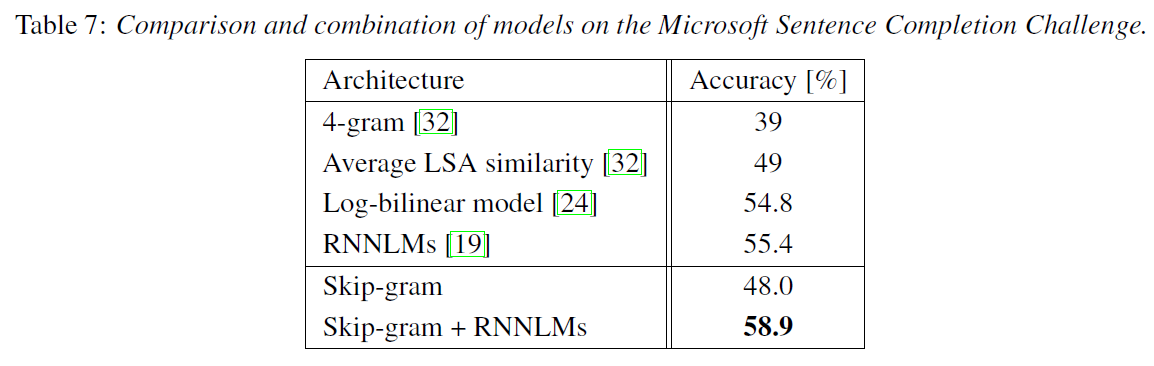
대회에서 제공된 50M개(5천만 개)의 단어애 대해 640차원 모델을 학습한다.
그 다음, 입력 미지의 단어를 사용하여 테스트 세트의 각 문장의 점수를 계산하고, 문장의 모든 주변 단어를 예측한다.
이런 방식인 듯.. ■ 주변부를 보고 ■ 예측
■□?□□
□■?□□
□□?■□
□□?□■
이러한 개별 예측의 합을 보고, 가장 가능성이 높은 문장을 고른다.
skip-gram 모델 자체는 점수가 높지 않지만, RNNLM으로 얻은 점수를 보완해 조합했을 때 높은 정확도를 보인다.
5 Examples of the Learned Relationships
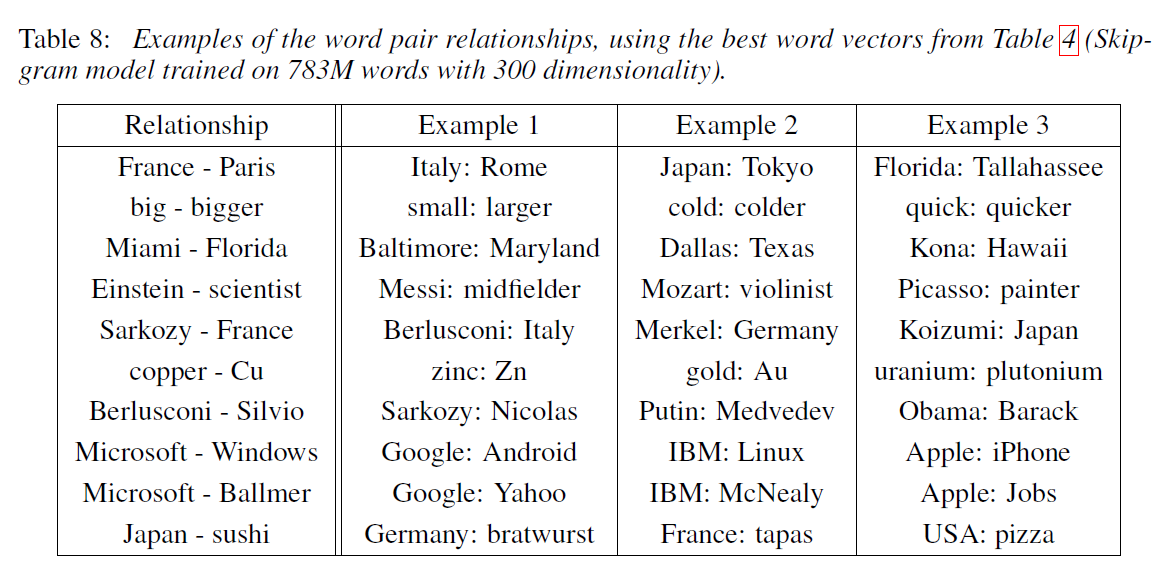
표 8은 다양한 관계의 단어들을 보여준다.
앞에서 했던 접근을 따른다. -> 관계는 두 단어 벡터들을 빼서 정의되고, 결과는 다른 단어로 추가된다.
보다시피 결과는 꽤 좋다. 많은 개선의 여지가 있을 것으로 보인다. (정확한 일치만을 가정하면 표 8에서 60%의 정확도를 보인다.) 데이터 더 늘리면 좋은 성능으로 널리 쓰일 것이다. 정확도를 높이는 다른 방법은 관계에서 한 개 이상의 예시를 제공하는 것이다. 1개 대신 10개의 예를 사용했더니 정확도가 10%정도 향상되었다.
벡터 연산을 통해 다른 일을 수행할 수 있다. 문맥에 어울리지 않는 단어를 찾는 데에 높은 정확도를 보였다. IQ test 등에서 인기 있는 타입이죠?
6 Conclusion
이 논문에서 우리는 다양한 모델에 의해 (language tasks 모음에서) 도출된 단어 벡터의 quality를 살펴보았다.
인기있는 Neural Network Model인 Feedforward와 Recurrent와 비교해서, 우리는 매우 간단한 모델 구조로부터 높은 품질의 word vectors를 얻을 수 있었다.
계산 복잡도가 훨씬 낮기 때문에, 더 많은 data set에서 더 높은 차원의 word vectors를 정확하게 계산할 수 있게 되었다.
DistBelief 분산 프레임워크를 사용하면 어휘 크기가 무제한인 1조 단어 코퍼스(크고 구조화 된 텍스트 집합으로 구성된 언어 리소스)에서도 CBOW와 Skip-gram 모델을 사용하는 것이 가능할 것이다. 이는 이전의 비슷한 모델들에 비해 몇 배 더 큰 수치다.
이전에 SemEval-2012 Task 2에서 word vectors가 이전 기술보다 훨씬 뛰어난 성능을 발휘한다는 흥미로운 연구가 있었다. 누구나 사용 가능한 RNN vectors들은 다른 기술과 함께 사용되어, 이전의 최고 기록보다 Spearman’s rank correlation에서 50% 이상 향상된 결과를 달성했다. word vectors를 기반으로 한 Neural Network는 감정 분석, 해설(paraphrase) detection 등 많은 NLP 업무들에서 사용됐다. 이 논문에서 보인 model architectures가 이러한 applications들에 benefit이 될 수 있길 기대한다.
우리가 진행중인 연구는 word vectors들이 기반 지식들에서 사실(facts) 확장 자동화, 기존 사실의 정확성 검증에도 유용하게 사용할 수 있을 것이다. 기계 번역 실험도 매우 유망해보인다. 미래에, LRA(잠재 관계 분석)나 다른 기술들과의 비교도 흥미로울 것이다.
7 Follow-Up Work
이 논문의 초기 버전을 쓴 뒤, 우리는 single-machine multi-threaded 방식의 C++ 코드를 게시했다. word vectors를 계산하고, 연속적인 가방의-단어들과 skip-gram architecture를 모두 사용했다. 학습 속도는 종이에 쓴 것보다 훨씬 빠르다. 일반적인 hyperparameter를 선택했을 때, 시간당 수십억 개의 단어를 본다. entities라 불리는 140만 개의 벡터들을 만들었으며, 1,000억 개 이상의 단어들을 훈련했다.

멘토링 때 공유드린 것 처럼 학습된 모델에서 어떤 부분에서 단어를 벡터로 변경되는지 알아보면 좋을 것 같습니다!