Google Developers; LLMs: What's a large language model?
LLM 란?
- LLM은 Large Language Model의 약자로, 한국어로는 대규모 언어 모델이라는 뜻. 이는 방대한 텍스트 데이터를 학습하여 인간의 언어를 이해하고 생성하는 인공지능 모델을 의미함.
- GPT 시리즈, Gemini, 딥시크 등 사용자와 채팅을 통해 정보를 제공하는 생성형 AI 전반이 LLM 을 이용하여 서비스를 제공함.
- 대규모 데이터 보유 및 학습, 자연어 처리 규모, 수많은 파라미터 개수 등을 특징으로 가짐.
최신 기술인 대규모 언어 모델 (LLM)은 토큰 또는 토큰 시퀀스를 예측하며, 때로는 여러 단락에 해당하는 예측 토큰을 예측하기도 함. 토큰은 단어, 하위 단어 (단어의 하위 집합), 단일 문자일 수 있음. LLM은 다음과 같은 이유로 N-gram 언어 모델이나 순환 신경망보다 훨씬 더 나은 예측을 수행함.
- LLM에는 순환 모델보다 훨씬 많은 매개변수가 포함되어 있음.
- LLM은 훨씬 더 많은 컨텍스트를 수집함.
이 섹션에서는 LLM을 빌드하는 데 가장 성공적이고 널리 사용되는 아키텍처인 트랜스포머를 소개함. (보통 LLM은 이런 트랜스포머를 이용하여 모델링)
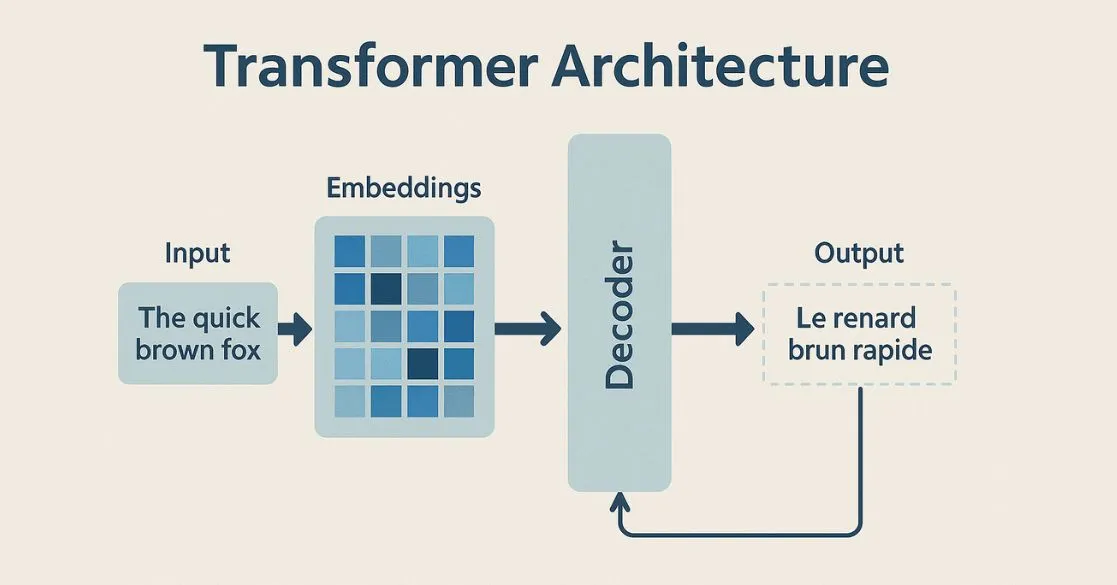
트랜스포머란?
구글: 번역과 같은 다양한 언어 모델 처리를 위한 하나의 최신 아키텍처 → 자연어 처리에 탁월함
(ex: 영어를 프랑스어로 번역하는 트랜스포머 모델 → 인코더 (input text를 중간 표현으로 변환) 와 디코더 (중간 표현을 output text로 출력))
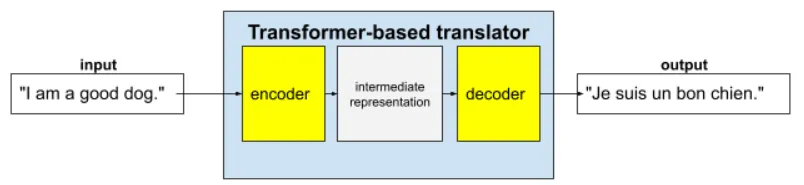
맥락에 맞는 자연스러운 표현 변환 및 출력을 위해 트랜스포머 모델은 셀프 어텐션 (self attention) 에 의존
→ self attention: 다른 어텐션 매커니즘(예: seq2seq 번역)은 보통 입력 토큰과 출력 시퀀스(예: 번역)의 토큰 또는 다른 시퀀스의 토큰 간의 관계에 가중치를 부여함. (입력 단어와 출력 단어 간 관계에 대해 중심적으로) 하지만 self-attention은 입력 시퀀스에서 토큰 간 관계의 중요도만 가중치를 부여함. (그냥 문장 안에서 단어들끼리 서로 얼마나 중요하게 연결되어 있는지를 봄)
→ 전통적 attention 매커니즘: 교수님이 나에게 질문할 때, 제대로 대답 (출력) 하기 위해 전공책 (입력) 에 밑줄 긋는 느낌 (번역에 최적화)
→ selft attention 매커니즘: 문장을 읽고 이해할 때, 머릿속에서 차근차근 개념도를 만들어 이해하는 느낌, “철수가 영희를 만났다” → 철수가 → 영희를 → 만났구나, 하나씩 연결해가면서 이해하는… (언어 이해, 추론에 최적화)
전반적인 transformer 모델 처리 과정
- Positional Encoding
- Multi-Head Self-Attention
- Feed Forward Network
- Residual + Normalization
- (추가로) Decoder 구조 & Cross-Attention
1. Positional Encoding
✨ 비유
트랜스포머는 RNN처럼 순서를 차례대로 읽지 않음
👉 대신 모든 단어를 동시에 보고 “attention” 함 (문장 안 단어들간 관계 파악을 위해)
근데 순서 정보 없으면 "I eat sushi"랑 "Sushi eat I"를 똑같다고 생각할 수 있으니……
그래서 단어 벡터에다가 위치 정보(사인/코사인 패턴)를 더해줌 → 나름의 위치와 순서 파악
📐 정석
각 위치 pos와 차원 i에 대해:
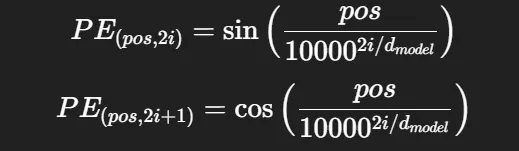
- d_model: 임베딩 차원 수
- 사인/코사인 쓰는 이유: 멀리 있는 단어도 연속적인 패턴으로 관계 파악 가능
2. Multi-Head Self-Attention
✨ 비유
어떤 글을 읽을 때, 한 번에 여러 “시선”으로 본다고 생각하면...
- 첫 번째 시선: “문법적 관계”(주어-동사-목적어)
- 두 번째 시선: “의미 관계”(사랑 ↔ 좋아하다)
- 세 번째 시선: “위치 관계”(on ↔ under)
👉 여러 관점으로 본 뒤, 마지막에 합쳐서 더 풍부한 이해를 만듦.
📐 정석
한 head에서 attention은 이렇게 계산됨:
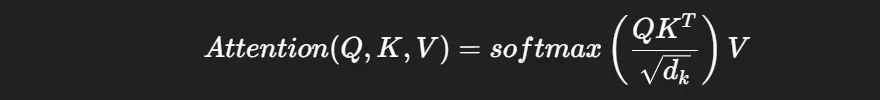
- Q (Query): 지금 토큰이 “다른 단어를 찾을 때 던지는 질문”
- K (Key): 각 단어가 가진 “자기 자신을 설명하는 열쇠”
- V (Value): 실제 정보(단어 의미 벡터)
Multi-head는 이걸 h번 반복:
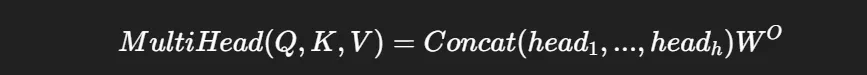
3. Feed Forward Network (FFN)
✨ 비유
attention으로 “단어 관계망”을 만들었다면, FFN은 그걸 가공하는 “뇌의 추가 사고 과정”임.
즉, “이 관계망으로부터 더 높은 차원의 패턴”을 뽑아냄.
📐 정석
각 토큰 벡터 x에 대해:
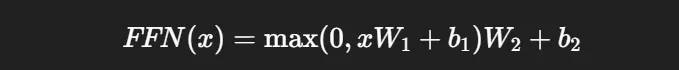
👉 그냥 2층 MLP (ReLU 포함).
4. Residual Connection + Layer Normalization
✨ 비유
학습하다가 gradient 사라지면 망하니까, 항상 “원래 입력”을 shortcut으로 더해줌.
그리고 매번 값이 너무 튀지 않도록 layer normalization으로 안정화시킴.
= 공부할 때 “새 개념”을 배우지만, 항상 “기존 노트”랑 비교해서 균형 잡는 느낌.
📐 정석
예를 들어 attention layer 출력:
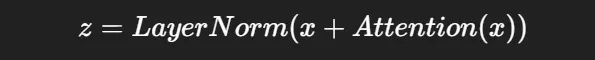
5. Decoder (Cross-Attention 추가)
✨ 비유
번역 같은 task에서는 “Encoder는 원문 정리”, “Decoder는 그걸 읽어서 새로운 문장 생성”.
Decoder에는 self-attention도 있고, 추가로 cross-attention이 있어서 출력 단어 ↔ 입력 단어 연결을 다시 잡아줌.
📐 정석
Cross-Attention에서는:
- Q: Decoder 현재 상태
- K, V: Encoder 출력 👉 그래서 출력 단어를 생성할 때 입력 문장 어디를 참고해야 할지 정함.
“트랜스포머는 단어들끼리 서로 눈치 보면서 ‘야 나 너 중요하냐?’ 확인 → 여러 시선(멀티헤드)으로 동시에 보정 → 그걸 또 가공(FFN)해서 똑똑해지는 구조
약간 김탄 style의 모델. 문장 안 단어들 간 관계를 파악하고 이를 보정함으로써 더 매끄럽고 자연스러운 번역에 굿!
다음 목표: attention is all you need 논문 읽기
