
Sierialize = 직렬화
직렬화 란?
빅맥을 생각해보자 참깨빵 → 패티 → 소스 → 양상추 → 치즈 → 피클 → 양파 순서로 재료가 올라가고 맨위에는 빵을 덮어서 마무리가 되어있을 것 이다.
만약 이 빵을 바로 앞이 아닌 멀리 컨베이어 벨트에 올려서 전달해야하는데 레일 중간에 통로가 너무 낮아서 재료를 분해해서 한줄로 올려야한다면 받는 쪽에서는 분리되어서 온 재료를 다시 조합해 완성된 햄버거를 만든다.
다소 억지스럽긴 하지만, 이것이 바로 직렬화 (및 역직렬화)다.
햄버거를 객체라고 생각하면
- 우선 이 객체를 어디론가 전달하기 위해 그 구성요소들을 한 줄의 바이트로 줄세운다(직렬화, 인코딩)
- 줄 세운 데이터를 스트림(파일이나 네트워크)을 통해 전달
- 스트림을 통해 전달받은 쪽에서는 바이트화된 객체를 다시 원래의 형태로 되돌린다(역직렬화, 디코딩)
조금 더 공학적으로 생각해보면
파일이나 네트워크를 통해 데이터가 왔다갔다하는 길(스트림)은, 데이터가 한 번에 한 바이트씩밖에 통과할 수 없는 아주 좁은 통로이다.
하지만 객체화 되어있는 데이터는 입체적인 구조로 되어있어서 이 좁은 통로를 통과할 수 없다.
그렇기 때문에 데이터가 스트림을 통해 통신이 가능하도록 한 줄로 줄세우는 작업이 필요한 것이다.
이때, 순서를 정하는 규칙이 존재 한다.
앞서 보았듯 햄버거로 비유 한다면 맨바닥에 있을 빵을 먼저 보내고 그 다음 순서로 쌓겠다 거나 위에서부터 보내겠다 는 규칙 도있을 것이다. 전송하는 쪽과 받는 쪽이 이렇게 동일한 규칙을 공유 하고 있어야 원활한 통신이 가능하다.
즉 직렬화란 스트림 전송을 위해 일정한 규칙에 의해 데이터를 일련의 바이트로 변형하는 작업이다.
여기서 일정한 규칙은 pickle, JSON과 같은 개념들이 바로 ‘일정한 규칙’들 중 하나이다.
이처럼 직렬화 하는 방식은 그 규칙에 따라 여러 방식이 있으며 pickle, JSON은 여러 직렬화 방식중 하나이다.
Pickle
1 #Pickle
2
3 import pickle
4
5 fruit_store = {'apple' : 1000,'banana' : 2000,'tomato' : 'soldout','melon' : '5000'}
6
7 #pickle 파일쓰기
8 with open('.data/fruit.txt','wb') as f:
9 pickle.dump(fruit_store,f)
10
11 #pickle 로 쓰인 파일 읽기
12 with open('.data/fruit.txt','rb') as f:
13 data = pickle.load(f)5번째 줄에 선언한 fruit_store 딕셔너리 객체를 직렬화 하는예제이다.
7번째줄에 ‘pickle 파일 쓰기’ 라고 되어 있는데 이를 다시 말하면 ‘pickle로 데이터 직렬화 해서 파일에 쓰기’ 와 같다.
11번째 줄의 ‘pickel 로 쓰인 파일 읽기’ 는 ‘pickle로 직렬화된 데이터를 읽어서 역직렬화 하기' 와 같다.
9번째 줄에서 pickle.dump를 하면 fruit.txt 파일에 직렬화된 fruit_store딕셔너리가 쓰여지는데 해당 파일을 열어보면 다음과 같이 바이트로 직렬화 된것을 직접 확인 가능하다.
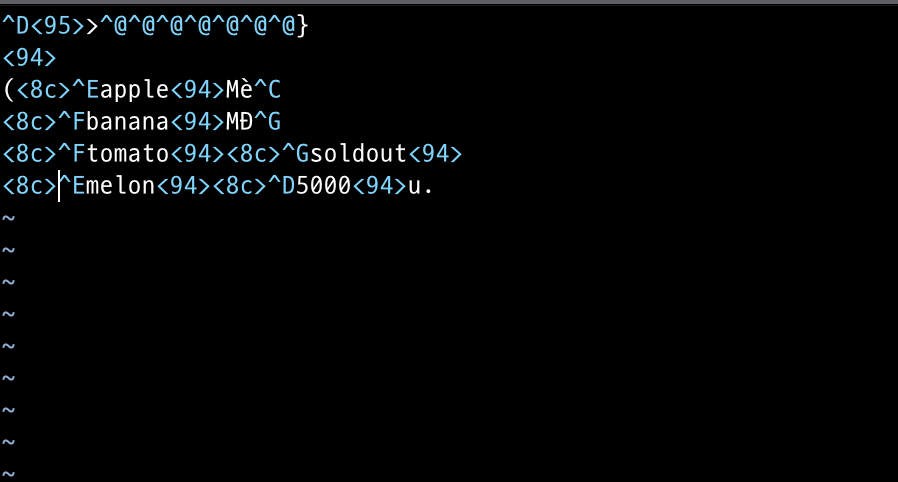
잘 모르겠지만..(인코딩 상의 문제라고 사료됨)pickle이 정해놓은 규칙에 의해 직렬화가 된 것을 확인할 수 있다.
JSON
동일한 코드에서 pickle만 json으로 바뀌었다.
import json
fruit_store = {'apple':1000, 'banana':2000, 'tomato':'soldout', 'melon':'5000'}
# json으로 파일 쓰기
with open('./fruit_01.txt','wb') as f:
json.dump(fruit_store,f)
# json으로 쓰인 파일 읽기
with open('./fruit_01.txt','rb') as f:
data = json.load(f,encoding='utf-8')이경우 직렬화된 파일은
{"tomato": "soldout", "melon": "5000", "apple": 1000, "banana": 2000}이다
JSON으로 객체를 직렬화하면 Pickle보다 사람이 볼 때 훨씬 가독성이 좋다는 장점이 있다.
하지만 속도면에서만 보자면 Pickle이 훨씬 빠르므로, 상황에 따라 취사선택을 해야한다.
결론
앞선 예제에서 봤듯이 직렬화 방식에는 여러가지가 있다.해당 예제에서는 Pickle과 JSON만 다루었지만,
YAML이나 CSV같은 직렬화 방식도 많이 사용한다.
각 직렬화 방식은 Pickle과 JSON처럼 장단점이 있으므로 상황에따라 필요한 직렬화를 적절히 사용해주어야한다.
예를들어 Pickle은 가독성이 떨어지는 대신 직렬화/역직렬화 속도가 JSON에 비해 빠르기때문에,
어떤 객체가 단순히 프로그램 동작 과정에서만 사용된다면 JSON보다는 Pickle이 좋다.
하지만 log나 설정파일 처럼 사람이 직접 확인하기 용이해야하는 부분에서는 JSON을 사용하면 된다.
참고로 복잡한 설정파일의경우 가독성이 아주 중요하므로,
JSON보다 더욱 가독성이 좋은 YAML같은 직렬화 방식을 고려해보는 것도 좋다.
또한 REST API응답용으로는 YAML보다는 구조 파악이 용이한 JSON을 고려해보는 것이 좋다.
