웹 크롤링
1.01.크롤링 이란?!

1.크롤링이란?크롤링(crawling) 혹은 스크레이핑(scraping)은 웹 페이지를 그대로 가져와서 거기서 데이터를 추출해 내는 행위를 의미 한다. 크롤링하는 소프트웨어는 크롤러(crawler)라고 부르며간단히 요약하면 조직적, 자동화된 방법으로 www(월드 와이드
2.02.정적 크롤링, 동적 크롤링의 차이

1\. 정적크롤링 이란 정적인 데이터를 수집하는 방법을 의미1-1 정적인 데이터란? 변하지 않는 데이터를 의미즉 한페이지 안에서 원하는 정보가 모드 드러날때 정적데이터라고 할수있다.2.동적 크롤링동적 크롤링은 동적인 데이터를 수집하는 방법을 의미2-1. 동적인 데이터란
3.03.정적 크롤링의 도구
requests 라이브러리는 파이썬에서 HTTP와 관련된 작업을 편하게 할 수 있도록 도와주는 라이브러리입니다\-get()함수웹 페이지의 내용을 요청하는 함수위의 결과를 print 했을때 <Response200>결과가 나오면 응답이 잘되었다는 뜻입니다 위의 결과를
4.04.동적크롤링의 도구
동적 크롤링을 위해서는 Chromedriver와 selenium이 필요 하다.일반적인 Chrome과는 다르게 모든 설정이 풀려있는 상태의 크롬 드라이버 라고 생각하면 된다.크롬 드라이버설치의 경우 https://chromedriver.chromium.org/d
5.05.HTTP status 코드
간단하게 말하자면 클라이언트가 서버에게 요청을 보낼 때 그 요청의 결과가 어떻게 되었는지를 알려주는 것입니다. 이를 통해 요청을 했을 때 그 요청이 성공적인지 혹은 에러가 발생했는지를 알 수 있습니다Status code의 앞의 숫자가 1로 시작하는 경우에는 서버가 요청
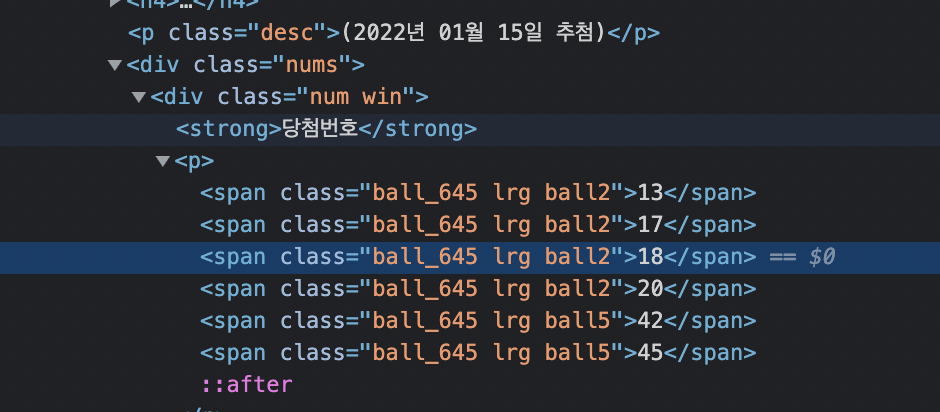
6.06.정적크롤링
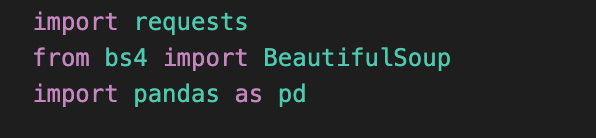
준비단계에서 필요한 request, BeautifulSoup 및 크롤링한 데이터를 엑셀파일로 옮겨줄 pandas 를 임포트 했다.처음 헤더 부분없이 코드를 진행하였을때 req.status_code가 402를 나타내어서 해결책으로 헤더 부분을 넣어주었다.메인 코드부분이며
7.07.동적크롤링

동적 크롤링을위해 selenium,BeautifulSoup을 import 시켰고 time의 경우 홈페이지의 로딩시간 서칭시간등을 기다리기 위해 추가 했다. 물론 time 말고 selenium의 Wait으로 해도된다!. 그리고 엑셀로 저장하기위해 pandas 또한 imp
8.08.selenium Wait
크롤링 코딩을 하면서 페이지 이동기간동안 time 을 많이 사용했다 하지만 원하는시간만큼만 기다리기때문에 로딩이 빠르나 느리나 정해진 시간만큼 기다려야 하는 단점이 생겼다.이를 해결하기 위해 구글링 한결과 selenium의 Wait을 찾게되었고 잊어버리지 않기위해 남겨