
CCTV 1편 요약
- 서울시 구별 cctv 현황 데이터 확보
- 인구현황 데이터 확보
- cctv 데이터와 인구현황 데이터 합치기
- 데이터를 정리하고 정렬하기
pandas + python 영역
Pandas
- 데이터 조작 및 분석을 위한 파이썬 프로그래밍 언어 용으로 작성된 소프트웨어 라이브러리이다. (위키백과)
- 이름이 판다여서 귀엽다고 생각했는데, 경제학 용어인 패널 데이터에서 파생되었다고한다.
- 파이썬에서 R만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈
- 단일 프로세스에서는 최대 효율
- 코딩 가능하고 응용 가능한 엑셀로 받아들여도 됌
- 원하는 모듈이 설치되어 있따면
- import pandas as pd
자료수집
- 구글 검색 [ 서울시 자치구 연도별 cctv 설치 현황 ]
- 서울시 자료 받은 열린데이터 광장으로 이동하여 오픈 API 서비스 선택하여 다운로드
- 파일명은 seoul_Population.xls
구글 검색으로 통해 대용량 데이터를 얻어 여러가지 실습을 해볼 수 있다.
파일 열기
import 모듈 as pd
변수 = pd.read_파일확장자("../파일경로/파일명.csv", encoding="utf-8")
변수.head()
- 한글은 encoding 필수
- head()는 데이터가 긴 경우 앞부분 5줄만 보여달라란 뜻
+) 엑셀의 경우
엑셀의 경우 윗 부분 섹션이 병합되어있는 경우가 많은데, 판다스는 이를 읽지 못한다.
pd.read_excel("경로", header=2, usecols ="B,D,G,J,N")
이런식으로 써주는게 눈에 잘 들어온다header = 2
병합되어있는 맨윗 두줄을 날려라
usecols = ""
필요한 열만 가져옴
Pandas의 데이터프레임 구조
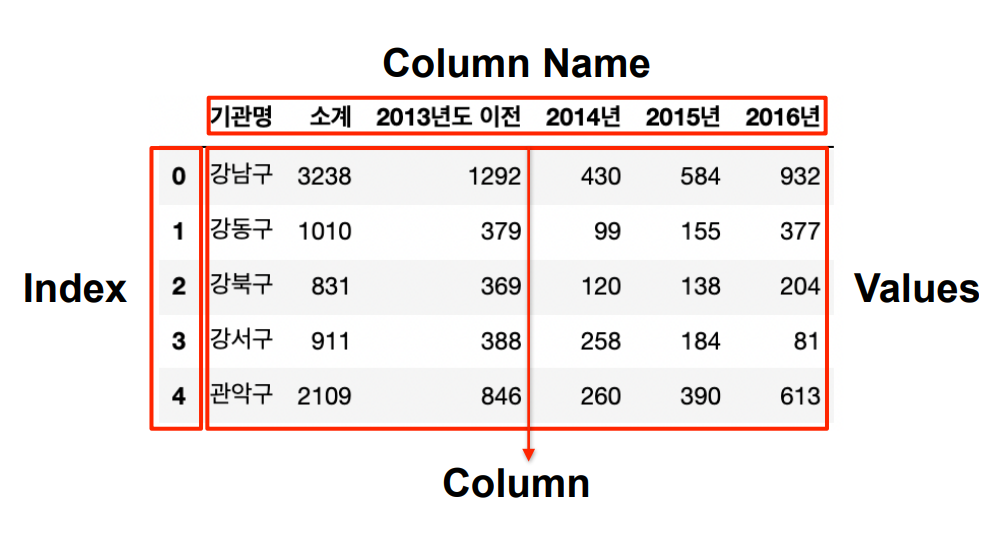
데이터 프레임의 이름바꾸기
변수명.rename(바꿀요소={위치:"바꿀이름"}, inplace=True)
예시) 변수명.rename( colums={ 변수명.colums[0] : "구별", 변수명.colums[1] : "인구수", 변수명.colums[2] : "한국인", ....}, inplace=True, ) 변수명.head()
inplace="True"
데이터도 바꾸는 명령어, 디폴트는 False값임.
데이터프레임 정보 탐색
파일담은 변수명.head() : 데이터의 상위 5줄 보이기. 디폴트는 5. 수량을 넣어 보이는 데이터 조절 가능하다.
e.g > CCTV_seoul.head()파일담은 변수명.tail() : .head()와 반대로 최하단 5줄 보임. 전체데이터 수량 파악하기 수월함
변수명.colums : colums 전체 값 보여짐
변수명.colums[0] : colums 첫번째 해당하는 값
변수명.index : 데이터프레임의 인덱스 값만 보여짐
변수명.values : 데이터프레임의 값만 보여짐
변수명.describe() : 데이터프레임의 기술통계 정보확인
데이터 선택
- 데이터변수명 ["컬럼이름"]
그 컬럼 내용이 인덱스와 함께 나옴
그러나 나오는건 Series 형태로 나옴!
- 데이터변수명.컬럼이름
컬럼이름이 문자열일때 이렇게 조회 가능 (숫자는 안됌)
- 데이터변수명[ ["A", "B"] ]
2개 이상의 컬럼 선택 시는 리스트 형태로
- offset index
[n:m] : n부터 m-1까지 선택
인덱스나 컬럼의 이름으로 slice 하는 경우 끝을 포함합니다
df.loc[:, ["A", "B"]]
모든 자료 a,b행만 보여줘 적은 데이터는 Series로 보여줌df.iloc[인덱스,열]
iloc : inter location
컴퓨터가 인식하는 인덱스 값으로 선택
e.g>
df.iloc[3]
컴퓨터가 인식한 3번째 인덱스의 값을 보여줌
df.iloc[3:5, 0:2]
행 3~4, 열 0~1번째 데이터 출력됌
df.iloc[[1,2,4],[0,2]]
행 1,2,4 / 열 0,2 데이터 출력
데이터 추가
병합 전 두 데이터를 살펴보며 추가할 데이터가 있는지 본다.
필요한 데이터를 추가작업함.
딕셔너리 안의 리스트 형태 ( 열 값 기준으로 들어감 )
left = pd.DataFrame({ "key" : ["K0","k4","K2","k3"], "A" : ["A0","A1","A2","A3"], "B" : ["B0","B1","B2","B3"] }) left
리스트 안의 딕셔너리 형태 ( 행 하나씩 )
pd.DataFrame([ {"key":"k0","C":"C0","D":"D0"}, {"key":"k1","C":"C0","D":"D0"}, {"key":"k2","C":"C0","D":"D0"}, {"key":"k2","C":"C0","D":"D0"} ])
이번 CCTV 작업에서는 cctv의 최근 증가율을 추가함
CCTV_seoul["최근 증가율"] = (
(CCTV_seoul["2016년"] +
CCTV_seoul["2015년"] +
CCTV_seoul["2014년"]) / CCTV_seoul["2013년도 이전"] * 100
)
CCTV_seoul.sort_values(by="최근 증가율", ascending=False).head()데이터 정렬
데이터변수명.sort_values(by="기준", ascending=True)
데이터 정렬 True면 오름차순, False면 내림차순
데이터 정렬하며 삭제할 것, 삭제하고 데이터를 정리한다.
pop_seoul.drop([0], axis = 0) 로 cctv 데이터와 행 열수 맞춰줌
만약 행이라면 pop_seoul.drop(["구별"], axis = 1)
pop_seoul["구별"].unique()
중복값 제외하고 한번씩만 출력하기len(pop_seoul["구별"].unique())
데이터 양 확인
병합
병합 전 두 데이터 Data Frame 잘 맞춰주기
병합 전 두 데이터의 key가 될 부분을 정하고 그 컬럼을 기준으로 병합!
how를 지정하면 그 기준으로 지정 안한 데이트를 병합함
( 지정한 데이터는 다 가져오고 다른 데이터는 왼쪽에 없는 자료면 NaN 직혀버림)
Pandas에서 데이터프레임을 병합하는 방법
- pd.concat()
- pd.merge()
- pd.join()
Pandas에서 데이터프레임을 병합하는 방법
- pd.concat()
- pd.merge()
- pd.join()
pd.merge(left,right,on="key")
how 값을 안쓰면 공통의 데이터가 나옴. 디폴트값 how="inner"
반대의 값은 how="outer" 합집합, 모든 데이터 나옴
pd.merge(left,right,how="left",on="key")
left 기준으로 표 보임.
right가 없는 값음 NaN처리되고
left가 없는건 걍 짤림
