
💡Nginx는 왜 사용하는가?
✏️우선 배경지식.
Nginx는 웹서버이다. 웹서버란 백엔드 단에서 HTML, CSS, JS, img 파일 등 static page(정적 페이지)를 요청받고 처리해주는 서버다.
만약 자바 기반 웹 앱이나 DB자료 요청 등의 동적 페이지가 필요할 경우 웹서버는 WAS(웹 어플리케이션 서버)에 요청을 하는 역할도 수행한다.
그럼 Nginx, 왜 사용하는가? 파악하려면 아파치 서버와 비교해야 한다.
Apache 1995년에 개발됐고, Nginx는 2002년에 개발됐다.
95년 당시 NCSA httpd라는 웹서버가 사용되고 있었다.
그럼 NCSA httpd는 뭐냐? 세계최초의 웹서버였으면 좋겠지만 인터넷을 만든 팀 버너스 리가 만든 CERN httpd에 선두자리를 빼앗긴 세계에서 2번째로 일리노이 대학교에서 개발한 웹서버다.
대신 NCSA httpd는 common gateway interface, 즉 CGI를 최초로 도입했음. 기존의 CERN httpd는 엄청 정적인 페이지였기 때문.
그럼 정적인게 뭐냐?
세계 최초의 홈페이지(http://info.cern.ch/hypertext/WWW/TheProject.html)를 방문해보면 알 수 있는데 엄청 조용하고 정적이다. 즉, 사용자한테 정보만 욱여 넣어줄 뿐 사용자가 이거 해줘 저거 해줘 요청에 대해 아무런 처리를 못하는 것.
이거를 개선하는게 CGI와 WAS. 사용자가 입력하는 정보를 처리하는 개념이다. 기존에 C언어 이런거에서 셸에 입력하면 결과 내주고 이런 프로그램을 서버에서 실행하면서 사용자가 홈페이지에서 요청한걸 처리해준다는 개념.
웹서버인 NCSA httpd가 사용자가 입력한 정보를 프로그램에 요청해 그 결괏값을 다시 보내주는 것.
이렇게 탄생한 NCSA httpd는 1990년대 초반에 엄청난 인기를 끌었다.
그러나 NCSA httpd는 팀 아저씨가 개발한 것도 아니었고, 근본이 부족했기 때문에 여기저기서 입맛에 맞게 수정해 쓰기 시작했다. 그래서 서로 호환도 안 되고 버그가 엄청 많아졌다.
그래서 이러면 다 망하겠다 싶어서 뛰어난 개발자들이 모여서 만들기 시작한게 지금의 Apache.
다만 완전히 새롭게 만든게 아니라 NCSA httpd 코드를 기반으로 만들었고, 실제로 아파치 개발자들도 NCSA 개선(patch)버전을 만든다고 언급함. 아파치라는 이름은 이렇게 a patch web server 에서 탄생했다.
그런데 아파치도 시간이 흘러 2000년쯤 되자 인터넷 사용랑이 폭발적으로 늘어나면서 문제가 발생했는데,
수많은 사용자가 커넥션을 요청하니 서버가 감당하지 못하고 더이상 커넥션을 만들어주지 못하는 일이 발생한 것.
커넥션이 1만개쯤 되면 더이상 커넥션을 형성하지 못하는 문제로 이를 c10k문제라고 한다. 커넥션이 1만개(K= 1000개).
이건 하드웨어가 문제가 아니다.
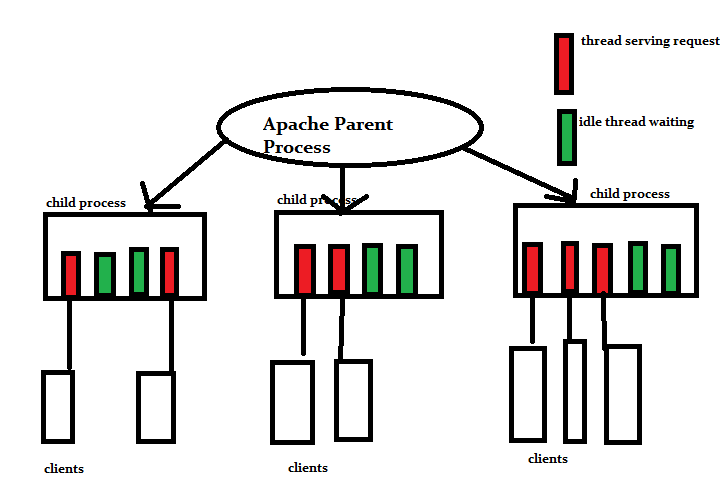
아파치 서버는 사용자 요청이 올 때마다 자식 프로세스를 생성해 클라이언트-서버 커넥션을 만들어준다.
또 미리 fork를 떠서 자식 프로세스를 미리 많이 만들어놨는데, 이를 pre-fork 방식이라 하는데 이런식으로 요청이 올때마다 프로세스를 할당한다.
또한 커넥션이 만들어지는 과정이 여러 절차로 오래걸리기 때문에 계속 유지하자고 생각해서 아파치는 커넥션을 Keep alive 헤더 시간만큼 연결을 유지. 여기에 아파치 서버는 확장성이 좋은 대신에 프로세스당 차지하는 리소스양도 크게 잡아먹게 된다.
이런 상황에서 각 클라들은 메모리도 많이 잡아먹고 연결도 오래 유지하려 하고, 또 추가로 다른 클라들의 많은 요청도 받게되니 서버 cpu는 컨텍스트 스위칭을 많이 하면서 과부하가 걸린 것.
이런 아파치의 단점을 극복하고자 2002년 탄생한게 Nginx다.
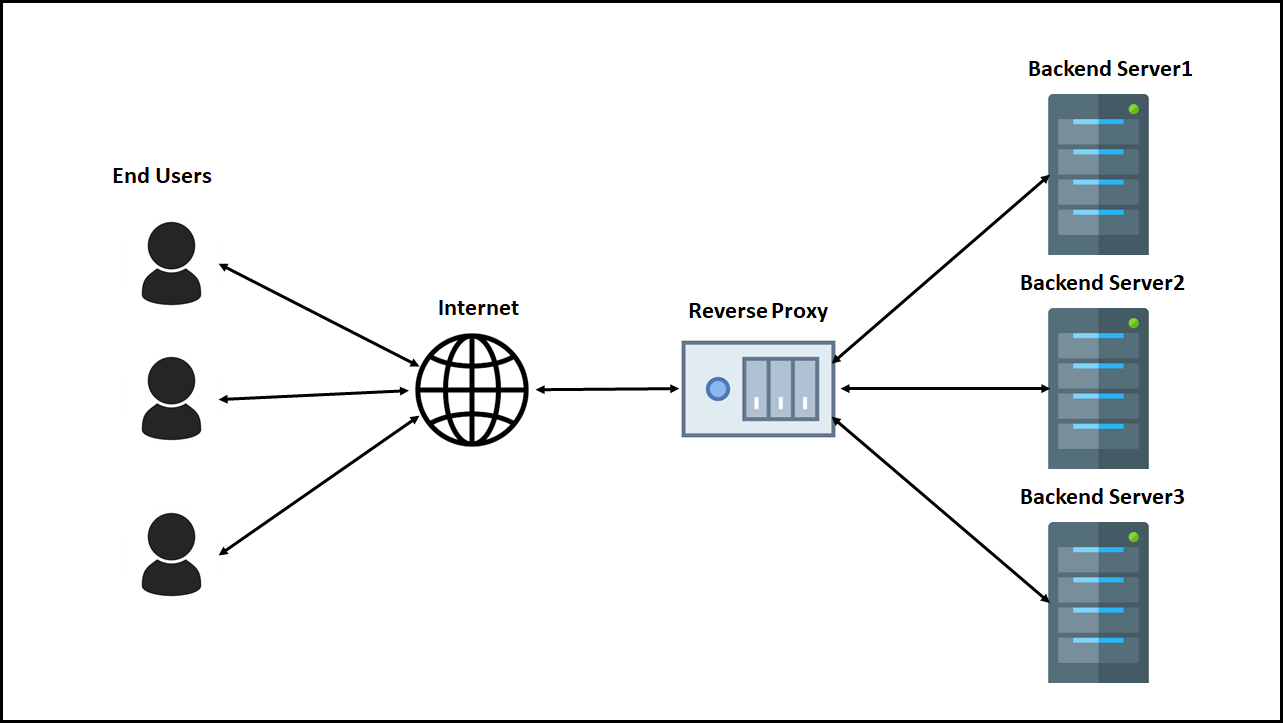
초창기 Nginx는 아파치와 함께 사용하기 위한 목적이었음.
아파치 서버 앞단에 엔진엑스를 두고, nginx가 동시 커넥션을 대신 유지해주는 방식이다.
정적 파일 요청은스스로 처리하고 하고 동적파일 요청을 받았을 때만 아파치 서버와 커넥션 형성을 해주는 것이다.
💡 여기서 잠깐, 엔진엑스 구조?
마스터(부모) 프로세스에서 워커 프로세스 형성.
CPU코어 개수만큼 워커 프로세스 생성함. 이렇게 컨택스트 스위칭을 줄임.
listen 소켓을 지정받고 클라 요청이 들어오면 커넥션 형성(keep alive)하고 요청 처리.
하지만 요청이 없으면 다른 커넥션을 만듦.
이런 요청을 이벤트라고 부르는데, 워커프로세스에 의해 큐 대기 방식으로 비동기 처리됨 => 이벤트 드리븐
이렇게 하면 워커프로세스가 쉬지않고 일하게 됨.
시간이 오래걸리는 이벤트는 스레드풀에 위임함.
💡 스레드풀 처리 방식
thread per request란 하나의 리퀘스트는 하나의 스레드가 처리하는 모델임. 그런데 서버에 요청이 들어올때마다 스레드를 새로 만들고 처리가 끝나 버린다면, 스레드 생성에 소요되는 시간이 낭비됨.
스레드 처리속도보다 요청이 빨리 들어오게 된다면? 결국 스레드 수가 증가, 컨텍스트 스위칭이 증가. 또 메모리도 고갈됨.
결국 이를 해결하기 위해 스레드풀 개념이 등장. 앞에서 봤던 스레드풀 리퀘스트 모델. 스레드를 미리 만들어 놓고, 서버 API 요청이 들어오면 큐에 요청이 왔을때 할당받은 스레드가 처리. 처리가 다 끝나면 스레드를 버리는게 아니라 스레드 풀로 돌아감.
따라서 미리 만들어놓고 재사용하기 때문에 스레드 생성 시간을 절약하고 요청을 빠르게 처리.
제한된 수의 스레드만 생성, 운용하기 때문에 스레드를 무한정 생성하지 않음.
그럼 몇개의 스레드를 만느냐? CPU-bound task는 코어 개수만큼
IO bound task라면 코어 개수의 2~3배 가량 스레드를 만듦.
task 수의 제한이 없다면 큐의 크기를 확인.

어찌됐든 원래 아파치와 함께 사용하려고 만들었던 Nginx는 2008년 애플에서 만든 스마트폰의 등장으로 나름의 세를 불리기 시작한다.
사람들이 스마트폰을 통해 수시로 인터넷에 접속하고 여러 커넥션을 요청했기 때문에 Nginx는 아파치 없이 웹서버 그 자체로 사용되기 시작한 것. 스마트폰 보급률이 올라가면서 Nginx는 더욱더 매력적인 웹서버로 명성을 떨쳤다.
하지만 이런 Nginx도 단점이 존재한다.
개발자가 기능 추가 시도했다가 워커프로세를 종료하는 경우 관련된 커넥션과 요청을 더이상 처리할 수 없는 문제가 발생해 개발자가 모듈 만들기가 까다로웠던 것.
그러나 앞서 말했듯 장점이 이를 상쇄한다. 수많은 동시 커넥션 빨리 처리하는데 프로세스 적게 만들어 가볍고 빠르다.
설정이나 기능을 변경해야 한다? 그러면 개발자가 마스터프로세스는 워커 프로세스들을 따로 생성하고 새로운 프로세스들은 거기서 처리한다.
기존 워커프로세스에서는 더이상 커넥션 형성을 안 하고 기존 워커 프로세스에서 처리한다. 기존 워커 프로세스의 이벤트들이 다 끝나면 기존 워커프로세스를 없애버리는 것이다.
그럼에도 아파치가 여전히 사용되는 이유는 그 안정성 때문이다.
아파치는 애초에 탄생 배경부터 버그 수정을 패치하고 호환이 되는 걸 목표로 나왔었다. 그래서 다양한 os에서 안정적이라는 장점이 있다.
반면 Nginx는 windows에서 제대로된 성능을 발휘 못한다는 단점이 있음.
또 아파치는 모듈 기능 추가가 쉽고 모듈 종류도 아파치 서버가 훨씬 많다는 장점이 있다.
💡 여기서 잠깐, 멀티 프로세스와 멀티 플렉싱 서버의 차이?
멀티 프로세스 기반 서버
- 클라이언트 <-> 서버 간 전송 데이터의 용량이 클 때
- 데이터 송수신이 지속적일 때
멀티플렉싱 기반 서버
- 클라이언트 <-> 서버 간 전송 데이터 용량이 작을 때
- 연속적인 연결이 필요 없을 때(연결이 간헐 적일 때)
- 많은 수의 클라이언트 처리
결론은 Nginx나 아파치나 서로 장단이 있으니 상황에 맞는 서버를 사용하자.
