Level1 P-stage
Image Classification 대회 회고
부스트캠프를 진행하면서 첫번째 프로젝트인 Image Classification 대회를 진행한 과정 및 느낀점들을 정리해보고자 합니다.
목차
- 대회 개요
- 진행 과정
- 대회 결과
- 느낀점
대회 개요
먼저 대회를 간단히 설명하자면 사람의 이미지를 받았을 때, 해당 사람이 마스크를 쓰고 있는지, 연령대는 어떠한지, 성별은 어떠한지 분류하는 대회입니다. 데이터셋은 부스트캠프 자체에서 구매한 이미지 데이터셋을 이용했으며, 리더보드 상에서 f1 score를 올리는 것이 목표였습니다.
분류 task에 대해서 자세히 언급하자면, 전체 4500명의 사람 중에 60%가 학습 데이터셋으로 사용되었으며 각 사람에 대해서 총 7개의 이미지가 주어졌습니다. 그 중 5개의 이미지는 마스크를 정상적으로 착용한 이미지였으며, 1개는 마스크를 착용하지 않은 이미지, 마지막 1개의 이미지는 부적절하게 마스크를 착용한 이미지였습니다. 이러한 이미지를 기반으로 성별(Male/Female), 세가지 연령대(30세 미만/30세 이상 60세 미만/60세 이상), 세가지 마스크 착용 상태(미착용/착용/부적절)으로 나누어 총 18가지 class로 나눠야 했습니다.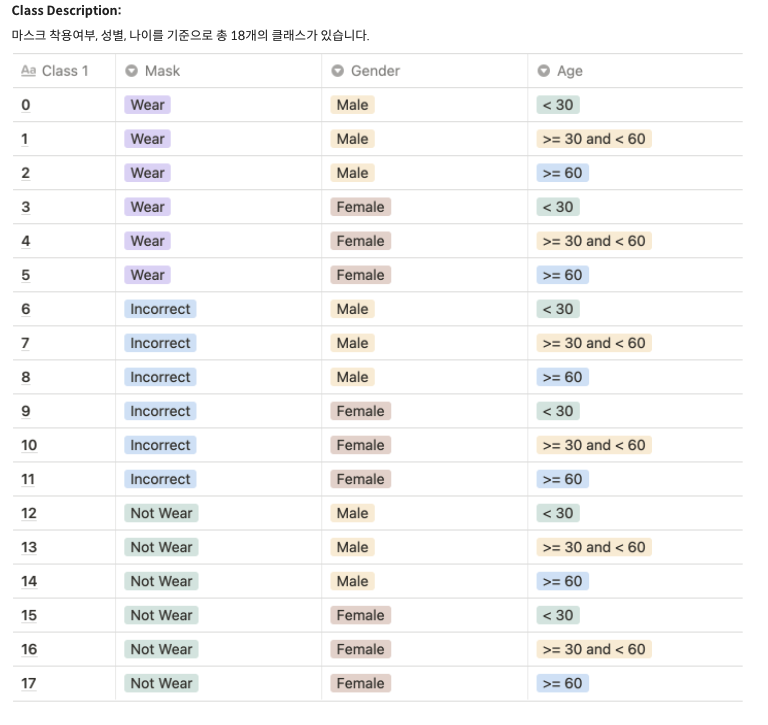
부스트캠프에서 이번 프로젝트를 통해서 학생들에게 가르치고자 하는 것은 대회 자체에서 높은 등수를 차지하는 것보다는 그 과정에서 대회 자체를 경험해보고, 노트북 형태에서 벗어나 다양한 협업 툴을 이용하는 동시에 여러 방법론들을 직접 경험하여 앞으로 계속될 대회와 프로젝트의 기반을 다지는 것이었습니다.
진행 과정
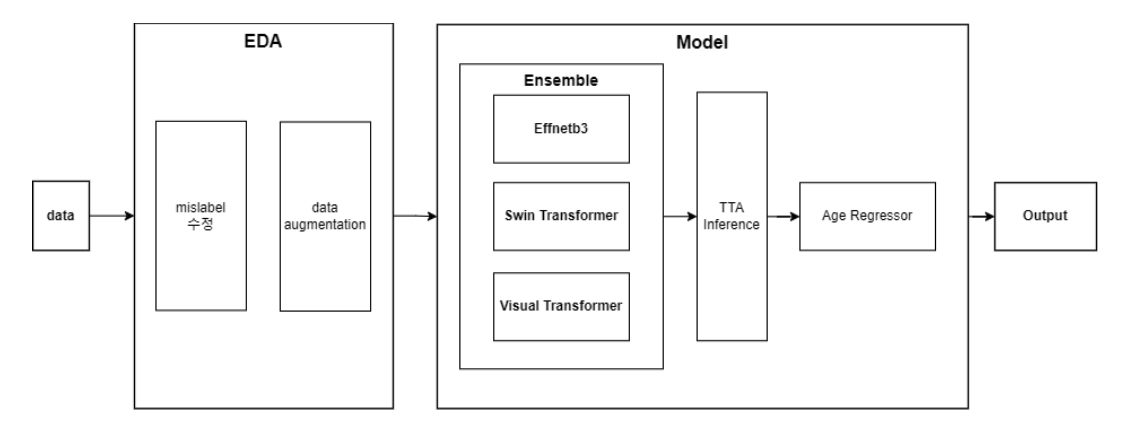 대회를 도식화하면 위와 같습니다. 기본적인 EDA를 진행한 이후에 data에 몇가지 augmentation을 적용하였습니다. 이후 여러 모델을 이용하여 앙상블을 구성하였고 이에 대해 TTA를 적용한 다음 가장 분류하기 까다로운 나이대에 대해서 regressor처리를 하여 개선했습니다.
대회를 도식화하면 위와 같습니다. 기본적인 EDA를 진행한 이후에 data에 몇가지 augmentation을 적용하였습니다. 이후 여러 모델을 이용하여 앙상블을 구성하였고 이에 대해 TTA를 적용한 다음 가장 분류하기 까다로운 나이대에 대해서 regressor처리를 하여 개선했습니다.
1. EDA
대회를 본격적으로 시작하기에 앞서 주어진 데이터셋을 분석하기 위해 기본적인 EDA를 진행했습니다. 데이터를 분석한 결과 크게 다음의 문제점들을 발견했습니다.
1) 데이터의 mislabel
부스트캠프 내의 다른 수강생분이 실시한 데이터 전수조사를 통해서 성별, 나이대에 잘못된 라벨링이 된 데이터들이 존재한다는 사실을 전달 받았습니다. 해당 문제는 가장 먼저 처리해야 할 문제였습니다.
2) 데이터의 imbalance
주어진 데이터를 살펴본 결과 가장 먼저 눈에 띄는 것은 사람들의 나이대가 고르지 못하다는 점이었습니다. 60대 인원이 매우 적은 한편 그들의 나이가 모두 60세인 것과 30세 이상 60세 미만의 나이대 사람들은 대부분 50대 후반에 집중적으로 분포했습니다. 데이터를 개선할 때 이러한 부분은 또한 우선적으로 해결해야 할 문제처럼 보였습니다.
해당 사실들을 기반으로 데이터 개선 작업을 진행했습니다. 각 데이터를 불러올 때 csv를 바탕으로 진행하도록 데이터가 주어졌기 때문에, 저희 팀은 먼저 csv내에 mislabel된 데이터를 수정하였습니다. 이후 숫자가 매우 적은 60대 데이터에 대해서 rotate, horizontal flip, noise를 적용하여 offline augmentation을 진행했습니다. 이후 전체 데이터 양을 늘리기 위해서 random augmentation을 offline으로 진행하여 데이터 양을 3배로 증폭시켰고 cutout방식을 online으로 적용하였습니다.
2. Model
1) Validation strategy: Stratified K-Fold
학습을 진행할 때에 가장 중요한 것은 학습 과정에서 test 데이터셋과 evaluation 데이터셋을 제대로 분류하는 것입니다. 저희 팀은 가장 먼저 각 사람의 ID에 따라 데이터를 분리하여 동일 인물의 데이터가 train과 valudation에 동시에 들어가지 않도록 구성하였습니다. 그 이후에 마스크 착용 상태 및 나이의 비율을 유지하여 데이터를 분할했습니다.
2) Loss Function
실험 과정에서 Cross Entropy, Focal Loss, Label Smoothing을 모두 진행해 보았고, 그 결과 가장 성능이 좋게 관찰된 Focal Loss를 이용하였습니다. 특히 추가 실험으로 데이터 비율에 맞는 weight를 적용했으나 큰 효과가 없음을 확인했습니다.
3) Ensemble: Soft voting(by confidence)
먼저 hard voting으로 ensemble을 진행했으나, 기존 결과에서 confidence차이로 출력이 달라졌습니다. 이후 Transformer 모델을 추가했을 때, 일부 이미지를 높은 confidence로 구분하는 것을 확인하여 이를 이용하여 soft voting을 진행했습니다.
- Efficientnet_b3
첫번째 베이스 라인에서 여러 CNN 계열의 모델을 실험한 결과 efficientnet이 가장 우수한 것을 확인했습니다. 속도, overfittin을 고려하여 b0 혹은 b3을 베이스 모델로 활용하였습니다. - Swin Transformer
- Visual Transformer
Transformer의 계열을 이용하였을 때, Acc나 F1 score에서의 뚜렷한 장점은 확인하기 어려웠지만 confidence가 CNN 계열보다 높았습니다.
3. TTA, Age Regressor
1) TTA
결과를 inference를 하여 output csv를 추출할 때 horizontal flip, resizing, rescaling 등을 적용한 이미지 또한 고려하도록 하였습니다.
2) Age Regressor
분류 과정에서 가장 문제가 있는 부분은 나이대를 분류하는 것이었습니다. 이를 개선하기 위해 regression을 추가하여 진행했으며, 해당 부분에서도 CNN 계열의 모델과 Transformer 계열 모델을 ensemble하여 진행했습니다. 이 과정에서 기존의 30세 이상 60세 미만을 threshold로 사용하지 않고 최적의 결과를 보여주는 57세에서 58세 사이의 값을 이용하였습니다.
대화 결과
팀원들 대부분이 이번 프로젝트가 첫 대회 경험임에도 불구하고 전체 48팀 중에서 12등을 하며 동메달권에 들어갔습니다. 부스트캠프 내에 인공지능 관련한 경험이 풍부하고 잘하시는 분들이 많다는 것을 고려했을 때 나름의 쾌거라고 생각합니다.
단순히 등수 자체가 만족스럽다기 보다는 전체 프로젝트 과정 속에서 notebook 에서의 실험하는 것에서 벗어나 python 파일 자체로 실험을 진행하는 방법을 익힌 것과 github, wandb, notion 등 다양한 협업 툴을 활용하면서 진행한 것이 굉장히 만족스럽습니다.
느낀점
첫번째 프로젝트를 경험하면서 다방면에서 많은 것들을 배웠습니다. 첫번째 대회를 진행하면서 그 방식 자체를 경험해 본 것 자체도 큰 의미가 있습니다. 네이버 부스트캠프 자체에서도 아직 두번의 대회가 남아있으며 그 이외에도 다양한 경험들을 해 나갈텐데, 꾸준히 앞으로 나아가기 위한 초석을 닦은 대회입니다.
저희 팀은 대회를 진행하면서 각자의 대회를 펼치지 않고 모두가 하나의 지점에 다다르기 위해 나누어서 실험을 진행했습니다. 이 과정에서 노트북 기반으로 실험을 진행하는 것에서 github을 이용해 코드를 관리하거나, 하나의 wandb 계정에 실험 결과들을 기록함으로서 모두 함께 공유할 수 있도록 했습니다. 그 외에도 notion, 구글스프레드시트 등 공유에 도움이 되는 사항이면 도구를 아끼지 않았습니다.
물론 다들 아직 초짜이다보니 부족한 부분도 많았습니다. Baseline code 자체를 구성하는데도 꽤 많은 시간이 들어서 초반에 제출 기회를 여러개 날리기도 했고, pth파일 자체를 공유하는 등 좀 더 효율적으로 실험을 진행할 수 있는 방법들을 사용하지 못하기도 했습니다. 특히 가장 처음에 EDA를 진행하면서 팀 전체의 방향성을 세분화하여 결정하고 대회를 진행했으면 좋았을거라는 의견은 팀원 모두가 공감했습니다.
개인적으로 아쉬웠던 것은 실험을 본격적으로 진행하기 이전에 내가 현재 로컬에서 점수를 확인하고 있는 실험이 리더보드 상에서 대략적으로라도 어느정도의 점수를 보일 것인지에 대한 지표를 구축하지 않았다는 것입니다. 대회에서는 하루 동안 제출할 수 있는 횟수에 제한이 있기 때문에 리더보드상의 점수와 실험 점수와의 경향성을 파악할 수 있도록 구축하고 실험을 진행하는 것이 중요하게 느껴졌습니다.
그럼에도 불구하고, 이러한 여러가지 생각을 들도록 만든 이번 대회는 정말 값지다고 할 수 있습니다. 이론에서만 듣던 여러가지 모델들을 실제 테스크에 적용하기도 하고, data augmentation, TTA, pseudo labeling, ensemble 등을 직접 적용해보고 공유해볼 수 있는 기회였습니다. 가장 중요한 것은 이번에 배운 점들은 확실히 내 것으로 만들어서 다음 대회에서도 마음껏 이용할 수 있도록 하는 동시에, 아쉬웠던 점을 확실히 보완할 수 있도록 정리해 나가는 것입니다.
cf) 멘토님의 피드백
멘토님도 저희 팀의 WRAP-UP 리포트를 읽으시고 긍정적인 피드백을 남겼주셨습니다. 멘토님도 대회를 진행하시는 동안 늘상 강조하신 부분이 성능이 어땠는지보다는, 어떤 방식으로 생각하고 적용했는지, 팀 내에서 어떻게 소통하고 작업했는지였습니다. 이러한 부분에서는 저희 팀이 충분히 잘 해냈기에 높은 점수를 주셨습니다. 다만 다음의 세가지를 생각해 볼 거리들로 남겨주셨는데, 하나씩 답을 찾아가면 좋을듯 합니다.
1. 왜 Transformer 계열의 모델에서 Confidence 가 높은지에 대한 고민?
2. Why is the L2 loss better than the L1 loss?
3. Adamw vs Adam vs SGD?