AutoRAG를 만들면서, Ollama와 함께 사용하고 싶다는 문의가 꽤 있었다. 그래서 AutoRAG에서 Ollama를 사용하는 방법을 보여주겠다.
환경 세팅
설치
먼저, 당연히 AutoRAG와 Ollama가 설치되어 있어야 한다. 아래를 참고하자
LLM 모델 다운로드
ollama에서 사용할 LLM을 다운로드 하자. 이번 포스트에서는 "llama3" LLM을 사용해 볼 것이다. 터미널에 아래와 같이 입력하여 llama3 모델을 다운로드한다.
ollama pull llama3Ollama 서버 실행
터미널에서 아래 명령을 입력해 ollama 서버를 실행하자.
ollama serve이제 준비는 끝났다!
Config YAML 파일 작성
AutoRAG를 이용하기 위해서는 Config YAML 파일이 반드시 필요하다. 이 YAML 파일 편집만을 통해서 어떤 모듈을, 어떤 LLM과 임베딩 모델을 이용해서, 어떠한 메트릭으로 실험하여 최적화 할지를 결정할 수 있다.
수십가지 모듈과 파라미터 옵션, 여러 가지 메트릭들을 이용할 수 있다. Config YAML 파일 작성하는 방법이 궁금하다면 여기를 참고하자.
이번 포스트에서는 retrieval과 prompt maker, generator(LLM)만을 사용한 간단한 실험을 설계해 보았다.
아래 YAML 파일은 AutoRAG 레포에서도 확인해 볼 수 있다!
node_lines:
- node_line_name: retrieve_node_line
nodes:
- node_type: retrieval
strategy:
metrics: [ retrieval_f1, retrieval_recall, retrieval_precision ]
top_k: 3
modules:
- module_type: bm25
- module_type: vectordb
embedding_model: huggingface_all_mpnet_base_v2
- module_type: hybrid_rrf
target_modules: ('bm25', 'vectordb')
rrf_k: [ 3, 5, 10 ]
- module_type: hybrid_cc
target_modules: ('bm25', 'vectordb')
weights:
- (0.5, 0.5)
- (0.3, 0.7)
- (0.7, 0.3)
- module_type: hybrid_rsf
target_modules: ('bm25', 'vectordb')
weights:
- (0.5, 0.5)
- (0.3, 0.7)
- (0.7, 0.3)
- module_type: hybrid_dbsf
target_modules: ('bm25', 'vectordb')
weights:
- (0.5, 0.5)
- (0.3, 0.7)
- (0.7, 0.3)
- node_line_name: post_retrieve_node_line
nodes:
- node_type: prompt_maker
strategy:
metrics: [ meteor, rouge, bert_score ]
modules:
- module_type: fstring
prompt: "Read the passages and answer the given question. \n Question: {query} \n Passage: {retrieved_contents} \n Answer : "
- node_type: generator
strategy:
metrics: [ meteor, rouge, bert_score ]
modules:
- module_type: llama_index_llm
llm: ollama
model: llama3
temperature: [ 0.1, 0.5, 1.0 ]
batch: 1
request_timeout: 300위 YAML 파일을 보면, retrieval에서 bm25와 로컬 모델인 all_mpnet_base_v2 임베딩 모델을 사용한 벡터DB, 그리고 여러 hybrid retrieval들을 실험하였다. 이러한 hybrid retrieval은 테스트 시간이 매우 짧으므로, 얼마든지 옵션을 추가해보아도 부담이 없을 것이다.
이 후, generator에서 ollama를 사용하여 최종 답변을 생성하고 테스트 할 수 있다. 이렇게 YAML 파일 설정만으로 ollama를 AutoRAG에서 사용할 수 있는 것이다.
여기서는 3가지 temperature 옵션을 주어, 가장 좋은 temperature를 찾아볼 것이다.
AutoRAG 실행
AutoRAG 실행을 위해서는 반드시 qa 데이터셋과 corpus 데이터셋이 준비 되어 있어야 한다. 어떤 데이터를 준비해야 하는 지에 대해서는 여기를 참고하자.
이제 준비가 되었다면, 빈 디렉토리를 하나 만들어 준다. 이 디렉토리는 '프로젝트 디렉토리'로서, AutoRAG의 최적화 결과가 모두 저장될 것이다.
이제 터미널에서 아래처럼 입력하여 AutoRAG를 실행하자! 반드시 ollama 서버가 실행중이어야 한다.
autorag evaluate \
--qa_data_path ./path/to/qa.parquet \
--corpus_data_path ./path/to/corpus.parquet \
--project_dir ./path/to/project_dir \
--config ./path/to/ollama_config.yaml이러면 AutoRAG가 RAG를 자동으로 실험하고 최적화 할 것이다.
대시보드 실행
실험이 완료되었다면, 대시보드를 실행하여 결과를 확인해보자. 아래처럼 실행하자.
autorag dashboard --trial_dir ./path/to/project_dir/0여기서 trial_dir은 '프로젝트 디렉토리' 안에 있으며, 숫자로 되어있다. 만약 실행 중 실패했다면, 가장 최신의 (높은 숫자) 폴더를 지정하자.
그러면, 아래와 같이 대시보드를 볼 수 있다!
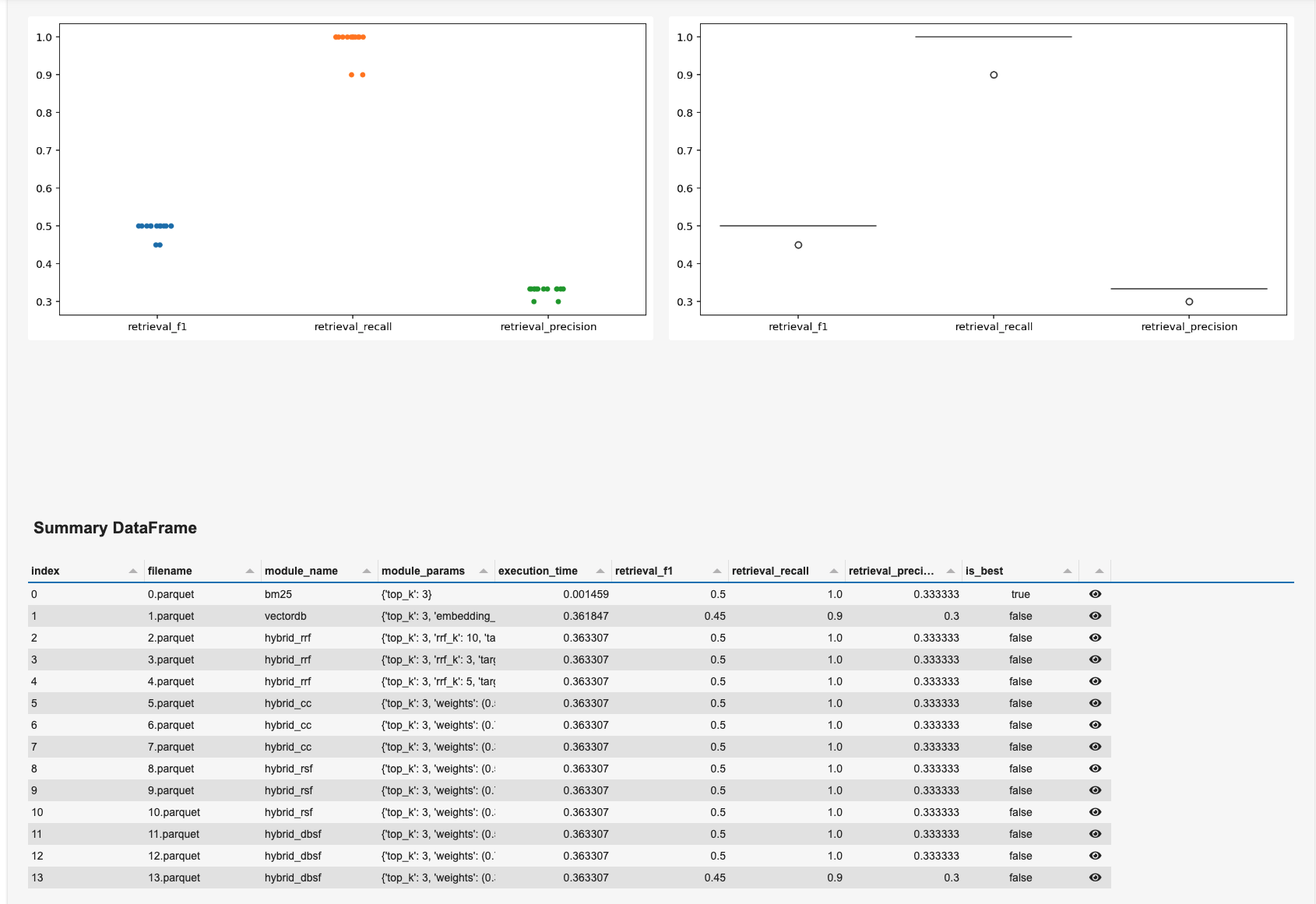
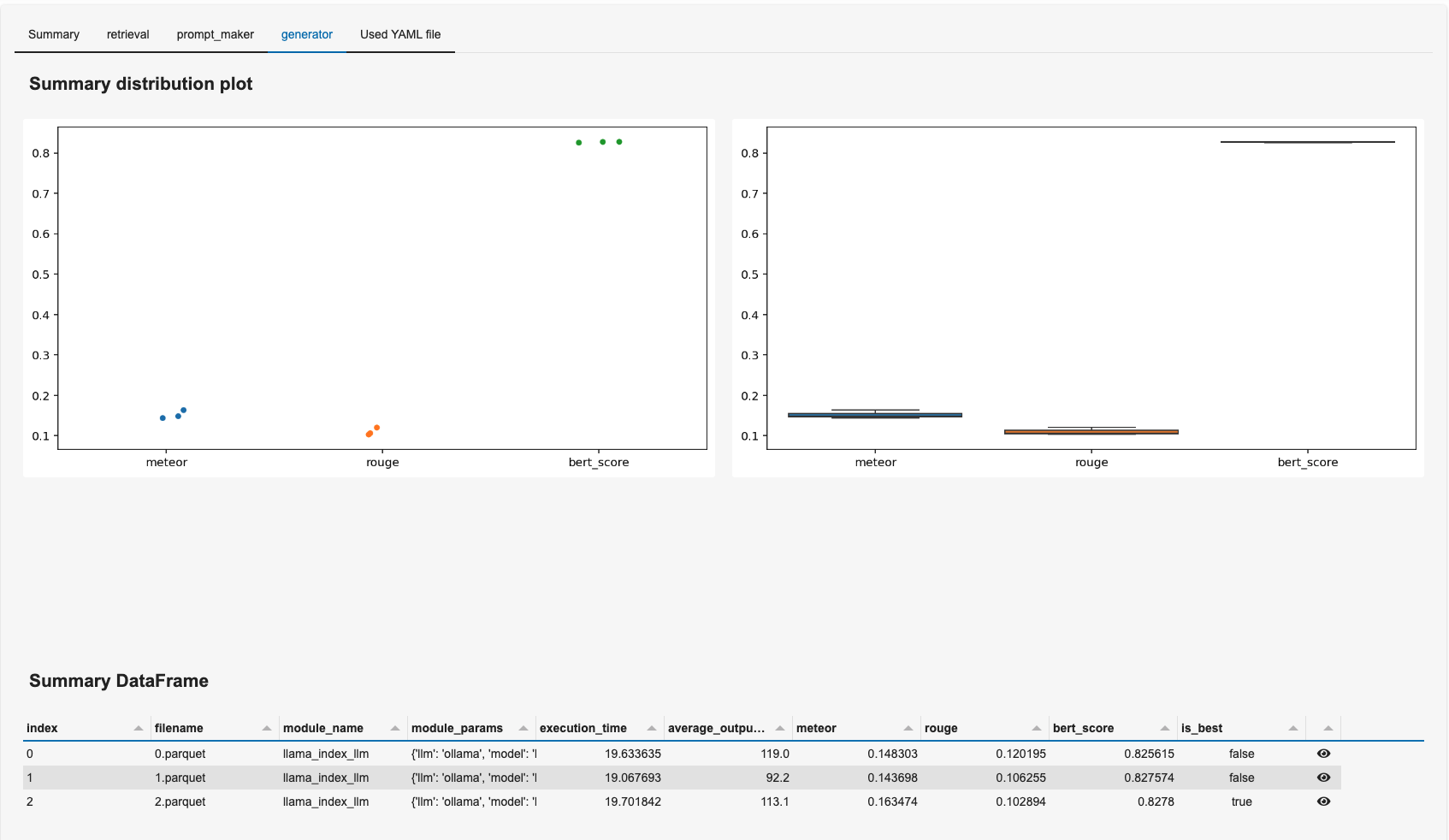
대시보드를 잘 해석하는 방법에 대해서는 이 글을 참고하자.
더 읽어보기
