이 블로그 포스트에서는 hybrid retrieval에서 왜 hyper parameter를 조정하는 것이 중요한지 알아볼 것이다. 해당 내용은 모두 pinecone의 논문 An Analysis of Fusion Functions for Hybrid Retrieval의 내용에 대한 포스팅임을 밝힌다. Hybrid Retrieval에 대한 자세한 분석이 담긴 논문이기 때문에, 원문을 보면 훨씬 더 많은 정보를 얻을 수 있을 것이다.
Hybrid Retrieval이란
Hybrid retrieval이 무엇인가? 간단하게, 여러 retrieval 모듈의 결과를 합치는 것이다.
Retrieval에는 벡터DB와 코사인 유사도를 활용하는 기법과, BM25와 같이 키워드 출현의 빈도를 파악하는 방식의 TF-IDF 기법이 존재한다. 벡터DB를 사용하는 기법을 semantic retrieval, TF-IDF 기법을 lexcial retrieval로 부른다.
Hybrid Retrieval 기법은 semantic과 lexcial retrieval 결과를 합쳐서 최종 retrieval 점수를 계산하는 것이다.
그러면 어떻게 계산할까?
Hybrid cc
Hybrid cc 기법에서 cc는 convex combination을 의미한다. "가중치 합" 정도로 이해하면 될 것이다.
이 말인 즉슨, semantic과 lexcial retrieval 결과를 더하는데, 각각 특정 가중치를 부여하여 합치는 것이다. 만약 semantic retrieval 결과에 더 비중을 가하고 싶다면 높은 가중치를 부여하면 될 것이다.
수식으로 표현하면 아래와 같다.
여기서 는 가중치 파라미터이다. 이것을 통해 semantic과 lexical retrieval 둘 중 어느 것을 더 중요하게 여길 것인지 선정한다.
수식이 매우 간단한 가중합이기 때문에, 쉽게 이해할 수 있을 것이라 생각한다.
Hybrid cc Normalization
근데 hybrid cc의 문제점 중 하나가, lexical과 semantic retrieval의 점수 분포가 다르다는 것이다. 대표적으로, BM25는 점수가 0~1 사이인 반면 코사인 유사도는 점수가 -1~1 사이이다.
이를 해결하기 위해서, 각 점수를 normalize하는 과정이 필요하다. 각 점수를 모두 비슷한 범위의 점수로 맞추어서, 단순히 점수의 분포 차이만으로 좋지 않은 결과가 나오는 것을 방지하기 위함이다.
이 때, 당연스럽게도 lexical과 semantic 각각에 대해 normalize를 수행해야 한다.
hybrid cc를 수행할 때 여러 normalize 기법이 존재하는데, 그 종류는 아래와 같은 것들이 있다.
- mm : Min-max Normalization. 가장 높은 점수와 낮은 점수를 각각 최댓값과 최소값으로 설정하고, 이를 이용해 normalize한다.
- tmm : mm과 비슷하지만, 최소값을 이론 상 가장 낮은 값으로 설정한다. BM25면 0, 코사인 유사도라면 -1이 최소값으로 설정될 것이다.
- z : Z-score Normalization. 평균과 표준편차를 활용하여 normalize한다.
Hybrid cc 가중치는 얼마나 중요할까?
Pinecone 연구진은 여러 데이터와 normalize 방법을 이용해서 가중치가 변할때 성능에 얼마나 큰 영향을 미치는지 측정하였다.
여러 가중치와 여러 normalize 방법을 이용해, NDCG@1000 성능을 측정하는 방식이다.
(NDCG가 무엇인지 모른다면? => 관련 블로그 보러가기)
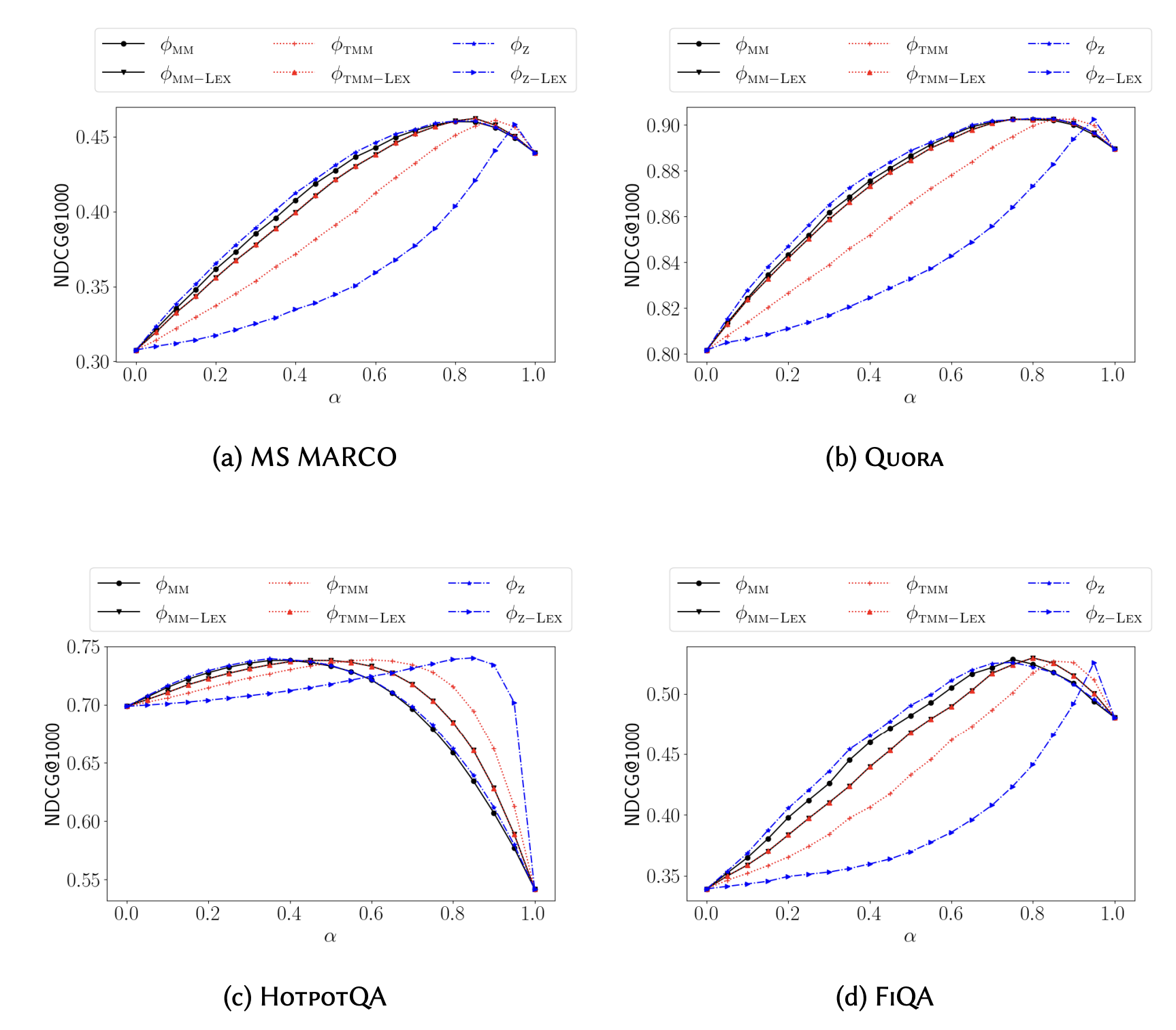
연구진은 실험적 방법과 이론적 방법을 이용하여 아래의 내용을 증명하였다. 이론적 증명은 어렵고 길기 때문에 원본 논문에서 확인 부탁드린다.
- Hybrid cc의 normalization 방법을 다른 것으로 바꾸더라도, hybrid cc 결과로서 단락의 순위에는 영향을 주지 않는다.
- 다른 normalization 방법으로 바꾸어도 최대 성능은 비슷하게 유지된다. 이 때에는 다른 가중치 값을 필요로 한다.
- normalize 방법 중에는 tmm 방법이 데이터 분포적으로 가장 robust한 편이다. 다른 기법에 비해 피크 점수가 뾰족하고 분간이 잘 가게 형성되는 것을 관찰했다.
또한 실험 결과로서 아래의 내용을 관찰할 수 있다.
- hybrid cc의 가중치를 조절하는 것에 따라, 0.1 이상 NDCG 값의 차이가 발생한다.
- normalize 방법에 따라 최대 성능을 보여주는 가중치 값이 다르다.
- 데이터 마다 최대 성능을 보여주는 가중치 값의 차이가 있다. (HotpotQA 결과를 보자)
결국, hybrid cc의 가중치에 따라서 normalize 기법과 관계없이 성능 변화의 폭이 꽤 있는 편이라는 것을 알 수 있다. 더불어 이는 데이터마다 다른 양상을 보여주기에, 올바른 가중치 값을 탐색적으로 찾는 것이 hybrid cc 사용시 중요하다는 것을 알 수 있다.
결론
적합한 가중치를 선정하는 것은 hybrid retrieval에서 매우 중요하다! Normalize를 선정하는 것은 어떤 방법을 쓰더라도 높은 성능을 찾을 수 있는데 반해, 적합한 가중치는 계속 바뀌며 성능에 영향을 크게 미친다.
Hybrid rrf 방법은 이번 포스트에서 다루지 못했는데, 기회가 된다면 rrf에 대해서도 다뤄보고자 한다.
그래서 어떻게 최적화하죠?
여러분의 머릿 속에는, "그래서 어떻게 최적의 값을 찾지?"라는 물음이 생길 것이다. 그래서 AutoRAG 0.2.10 버전부터 새로운 Hybrid retrieval 최적화 방식이 도입되었다.
기존에는 특정 가중치만 입력하여, 한 번에 몇 개 정도밖에 가중치 실험을 할 수 없었다. 이를 개선하기 위하여 가중치 탐색 범위를 직접 설정하고, 얼마나 많은 가중치를 실험해보고 최적점을 찾을 것인지 선정할 수 있다!
아래와 같이 YAML 파일을 설정하기만 하면, 0.0에서 1.0까지 0.01만큼 가중치를 바꾸어가며, 101개의 가중치를 실험해 최적의 가중치를 찾아줄 것이다. 여러분들은 YAML 파일 수정만 하면 된다! (AutoRAG 버전 업데이트는 당연히 필수!)
modules:
- module_type: hybrid_cc
normalize_method: [ mm, tmm, z, dbsf ]
weight_range: (0.0, 1.0)
test_weight_size: 101심지어 위와 같이 네 가지 normalize 방법도 설명할 수 있다. 이 네 가지 방법을 모두 실험할 수 있지만, 위 결론처럼 마음에 드는 것, 혹은 'tmm' 방식을 사용하는 것을 추천한다. normalize 방법 끼리의 성능 차이는 크지 않기 때문이다.
