RAG를 하려면 수 많은 Raw Data 들을 파싱해야 한다
Raw Data들 중에서도 가장 범용적으로 사용되는 파일은 PDF이기 때문에, PDF문서에서 텍스트를 추출해 내는 능력은 RAG의 가장 앞단에서 일어나는 일이고, 그렇기 때문에 중요하다
이번 글에서는 여러 파이썬 라이브러리의 PDF 파일에서 한글을 추출해내는 능력을 비교해 볼 것이다
인터넷 검색을 통해 무료 + 많은 사람들이 사용하고 있는 5개의 라이브러리를 실험 대상으로 정했다.
PyPDFium2, PyMuPDF, PyPDF2, PDFMiner, PDFPlumber 이렇게 5개를 비교해보도록 하자
실험 PDF
실험은 가장 무난한 5개의 Domain(medical, law, finance, commerce, public)의 PDF로 진행했다.
텍스트 추출 능력만 실험하기 위해, 이미지나 표가 있는 문서들은 일단 제외하였다.
코드
1. PyPDFium2
from langchain_community.document_loaders import PyPDFium2Loader
loader = PyPDFium2Loader(pdf_path)
load = loader.load()
print(load[0].page_content2. PyMuPDF
import fitz
doc = fitz.open(pdf_path)
for page in doc:
text = page.get_text()
print(text)3. PyPDF2
from PyPDF2 import PdfReader
reader = PdfReader(pdf_path)
pages = reader.pages
text = ""
for page in pages:
sub = page.extract_text()
text += sub
print(text)4. PDFMiner
from pdfminer.high_level import extract_pages
from pdfminer.layout import LTTextContainer
def extract_text_by_page(pdf_path):
for page_layout in extract_pages(pdf_path):
page_text = ""
for element in page_layout:
if isinstance(element, LTTextContainer):
page_text += element.get_text()
yield page_text
for page_number, page_text in enumerate(extract_text_by_page(pdf_path), start=1):
print(f"Page {page_number}:\\n{page_text}\\n{'-'*40}\\n")5. PDFPlumber
import pdfplumber
pdf = pdfplumber.open(pdf_path)
pages = pdf.pages
text = []
for page in pages:
sub = page.extract_text()
text.append(sub)
print(text)결과 비교
결과를 모두 붙여넣으니 글이 너무 길어져 사진 자료로 대체하도록 하겠다.
자세한 결과를 확인하고 싶은 분들은 -> 링크
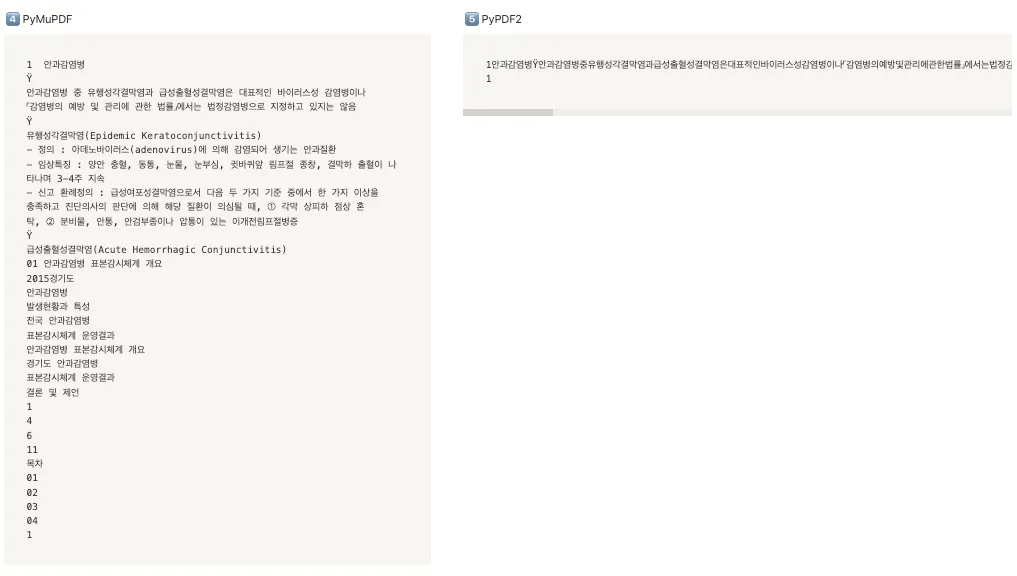
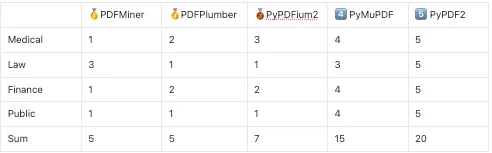
1. Medical
순위
🥇 PDFMiner (띄어쓰기까지 잘 추출해냄)
🥈 PDFPlumber
🥉 PyPDFium2
4️⃣ PyMuPDF
5️⃣ PyPDF2


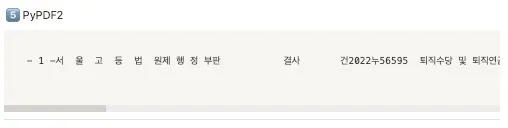
2. Law
순위
🥇 PDFPlumber → 줄 바꿈까지 완벽하게 추출
🥇 PyPDFium2
🥉 PDFMiner (공동 2위)
🥉 PyMuPDF (공동 2위)
5️⃣PyPDF2 (공동 4위)


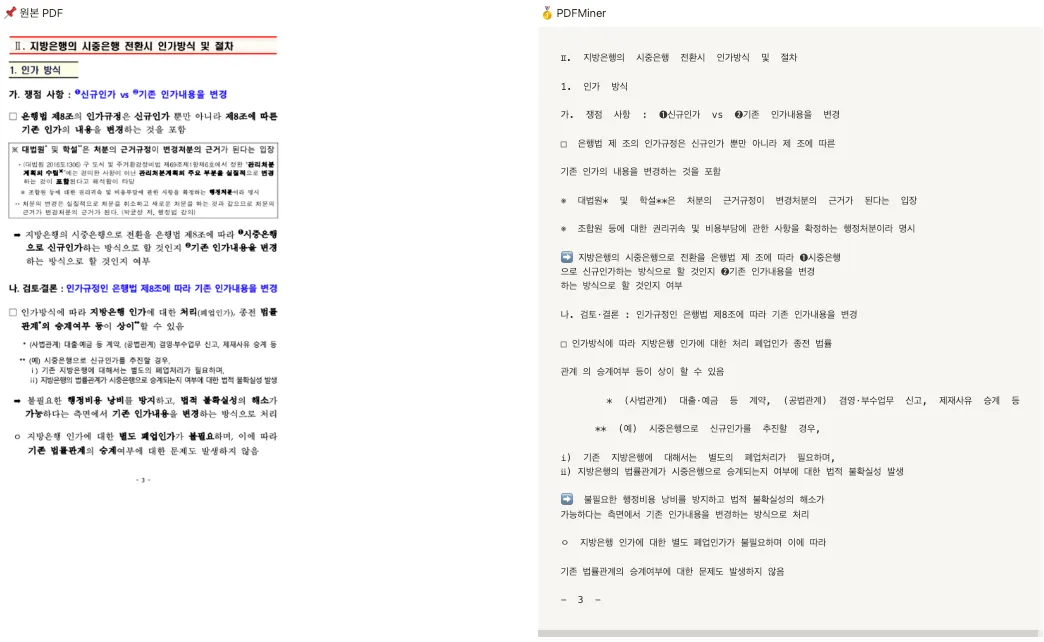
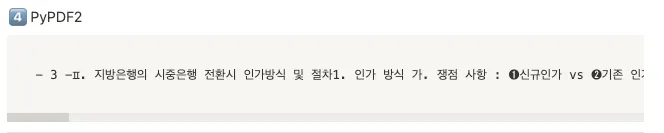
3. Finance
순위 (1~4위까지 성능은 사실상 거의 비슷)
🥇 PDFMiner
🥈 PyPDFium2
🥈 PDFPlumber
4️⃣ PyMuPDF → 줄 바꿈이 살짝 아쉬움
4️⃣ PyPDF2

4. Commerce
순위 (매길 수 없음)
전부 추출해내지 못하고 깨져버렸다

PyPDF2, PyPDFium2도 처참히 깨졌는데… 사진은 생략하도록 하겠다
5. Public
순위
🥇 PDFPlumber
🥇 PyPDFium2
🥇 PDFMiner
4️⃣ PyMuPDF
5️⃣ PyPDF2



최종 순위
총평
전반적으로 PDFMiner, PDFPlumber, PyPDFium2 성능 차이는 거의 없다고 느껴졌다
PyPDFium2가 3등을 하긴 했어도 1등과 거의 비슷한 수준이었다.
PyMuPDF는 줄 바꿈에서 가끔 깨지는 경우가 발생해 아쉬웠지만, 텍스트 추출 자체는 나쁘지 않았다
PyPDF2는 텍스트 추출은 잘 되지만, 줄 바꿈이 전혀 지원되지 않아 아쉽게도 꼴지를 했다
