유사도 검색 vs BM25. 내 문서에서는 뭐가 더 좋을까? AutoRAG로 비교해보기.
요약 :
1. 전통적인 검색 방법인 BM25가 임베딩과 유사도 검색을 이용한 방법보다 성능이 높을 때가 꽤나 많다.
2. 데이터마다 뭐가 더 좋은 지는 다르기 때문에 AutoRAG에서 실험해 보시라!
RAG에서 R을 담당하는 Retrieval
RAG (Retrieval Augmented Generation)에서 Retrieval은 매우 중요하다. 당연하다. 제대로 된 단락을 Retrieval이 찾아오지 못하면, LLM은 환각을 생산하는 멍청이가 된다.
이 Retrieval에는 크게 두 가지 방법이 있는데, dense와 sparse가 그것이다. 그런데 dense, sparse하니 이게 뭔지 당황스러울 것이다.
Dense Retrieval은 보통 RAG하면 생각하는 유사도 검색이라고 보면 된다. 단락을 임베딩 모델을 통해 벡터화하고, 임베딩한 질문 쿼리와 유사도 검색을 수행, 높은 유사도를 가진 단락을 가져온다. RAG의 기초 중 기초다.
반면에 Sparse Retrieval은 임베딩 모델을 사용하지 않는다. Sparse Retrieval의 대명사인 BM25의 작동 원리를 간단하게 알아보자. 직관적인 이해를 위해 수식은 제거했다.
BM25의 원리
도서관에 책 100권이 있다고 하자. 그 책들 중에서, '뉴진스 다니엘이 가장 좋아하는 채소는?'이라는 질문을 대답하기 위한 특정 페이지를 찾아야 한다. 어떻게 검색해야 할까?
아무래도 먼저 '뉴진스 다니엘 채소'와 같이 검색해야 하지 않을까? 그러면 '뉴진스'나 '다니엘' 등의 단어가 많이 담겨있는 책의 페이지가 나올 것이다.
그런데 문제는, 컴퓨터는 자동으로 '뉴진스 다니엘 채소'가 질문의 핵심 키워드라는 것을 모른다. 그렇기에 질문 전부를 단어 별로 나눈 후 검색할 것이고, 그러면 '뉴진스 다니엘은 당근을 좋아해' 보다 '다니엘 용주 리의 가장 좋아하는 채소는 뜨끈한 해장국의 시래기이다.'라는 문장이 더 먼저 검색이 될 수 있다.
이 문제는 생각보다 간단하게 해결할 수 있다. 보통 '키워드'라고 불리는 단어들은 자주 안쓰기 마련이다. 100권의 책 중에서 '뉴진스'나 '다니엘'과 같은 단어가 얼마나 나올까? 아무래도 몇 번 나오지 않을 것이다. 반면에 '가장' 이라던가 '좋아하는' 같은 단어는 매우 많이 등장하는 단어일 것이 분명하다.
그렇기에, 전체 문서에서 자주 등장하는 단어들은 검색할 때 고려하지 않는다. 그렇게 자주 등장하지 않는, '키워드'일 확률이 높은 단어들만 고려하여 문서를 검색하게 된다.
이것이 BM25의 대략적인 원리이다.
그래서 BM25와 같은 기법을 TF-IDF라고 한다. 영어로 Term Frequency-Inverse Document Frequency인데, 위 설명을 보았다면 대충 이해가 갈 것이다.
기본적으로 특정 단어의 빈도를 기준으로 검색하는데 (Term Frequency), 문서에서 자주 등장하는 단어들은 제외하는 것이다 (Inverse Document Frequency)
그래서 무엇을 써야해?
이제 유사도 검색과 BM25 (dense & sparse retrieval)에 대해서 알았는데, 둘 중 무엇을 써야 할까?
답은 "진리의 케바케"이다…
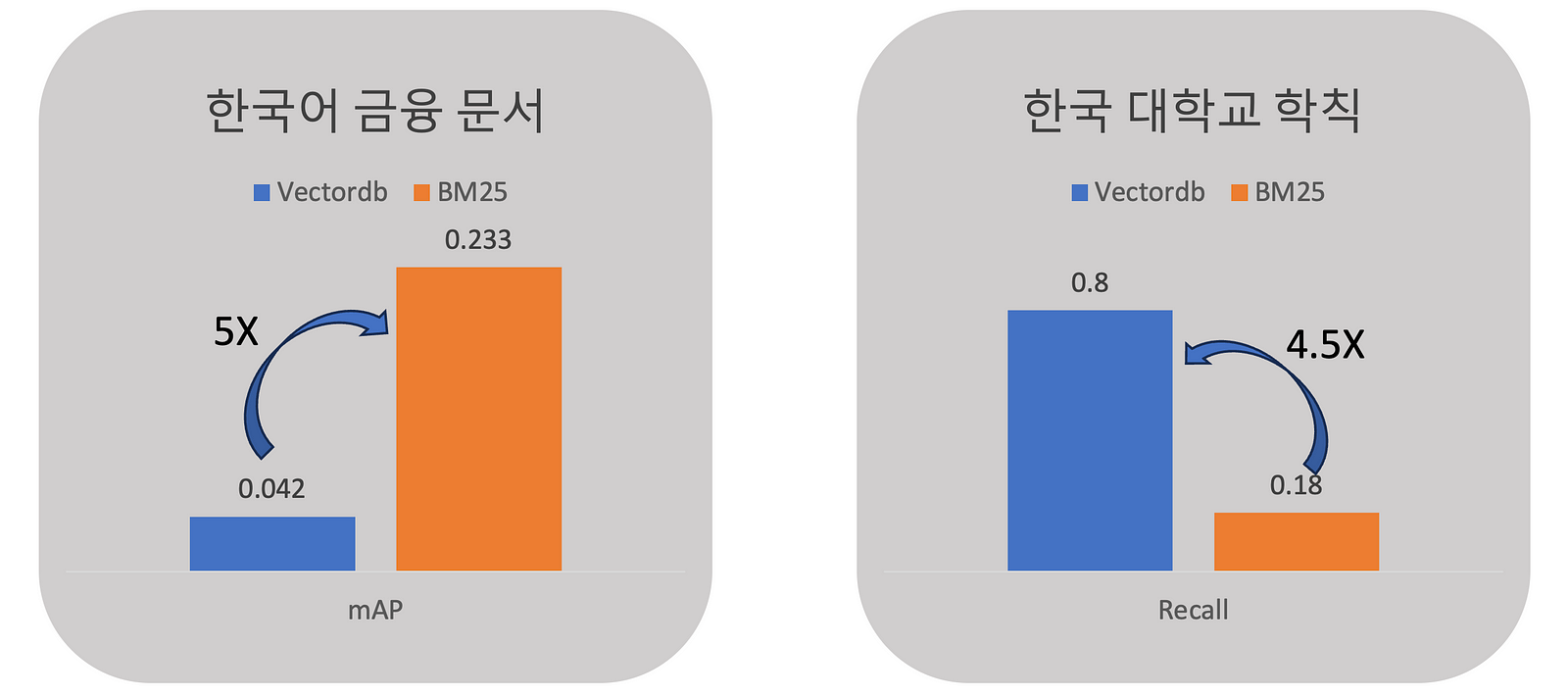
위는 필자가 직접 실험한 결과인데, 한국어 금융 문서에서는 BM25가 유사도 검색 (VectorDB)보다 다섯 배 성능이 좋았다. 반면에 대학교 학칙 문서에서는 유사도 검색이 BM25보다 4.5배 높은 성능을 보였다. 완전히 똑같은 기법인데, 문서 특성에 따라 이렇게까지 차이가 많이 나는 것이다.
그래서 뭐가 더 좋을까? 라고 물어본다면 '케바케'라고 답할 수 밖에 없다.
뭐가 더 좋은지 알아보자
그러면 이제 AutoRAG를 사용해서 어떤 방법이 더 좋은 것인지 알아보도록 하자.
엄청 간단하다!
- 일단 평가 데이터셋을 만들어줘야 한다. 여기서는 자세히 설명하지 않고, 문서에서 읽어보는 것을 추천한다.
- 아래처럼 YAML 파일을 만들어보자. Retrieval만 실험할 것이므로 짧은 YAML 파일이면 충분하다.
node_lines:
- node_line_name: retrieve_node_line
nodes:
- node_type: retrieval
strategy:
metrics: [retrieval_recall, retrieval_ndcg, retrieval_map]
top_k: 5
modules:
- module_type: vectordb
embedding_model: openai
- module_type: bm25
bm25_tokenizer: ko_kiwi- OPENAI_API_KEY 환경변수를 설정하고, autorag를 실행한다!
autorag evaluate --project_dir /your/path/to/project_dir \
--qa_data_path /your/path/to/qa.parquet \
--corpus_data_path /your/path/to/corpus.parquet \
--config /your/path/to/config.yaml- Dashboard를 실행하거나,
project_dir/0/retrieve_node_line/retrieval/summary.csv를 열어보고 어떤 모듈이 선택되었는지 확인한다.
더 읽어보기
- AutoRAG 깃허브 - https://github.com/Marker-Inc-Korea/AutoRAG
- Retrieval 메트릭 알아보기(영문) - https://medium.com/@bwook/retrieval-evaluation-metrics-in-autorag-0ca14d4e43f6
- 한글 검색 잘되는 retriever 전략 (한국어) - https://www.youtube.com/watch?v=ckHAvm-L6Sc&t=1s
