출처 : Improving Passage Retrieval with Zero-Shot Question Generation
UPR 리랭커는 랭체인이나 라마인덱스 모두에 들어가지 않은 리랭커 모듈이다. 그렇기에 생소할 수 있는데, 이 포스트에서 어떤 원리인지 알아보자.
들어가기에 앞서, 혹시 리랭커가 무엇인지 모른다면? 아래에서 빠르게 설명하겠다.
리랭커에 대해 알고 있으면 넘어가도 좋다.
리랭커란
기본적인 RAG는 Retrieval => Generation 형태다. 벡터 DB 등으로 적합한 단락을 찾고, 그것을 프롬프트로 만들어 LLM에 입력하는 구조다.
리랭커는 Retrieval 이후에 위치하는 모듈이다. 선천적으로 Retrieval 모듈들은 몇십만개의 단락 중에서 가장 관계가 높은 단락을 찾아내도록 설계 되었다. 그렇기에 효율은 높지만, 상대적으로 정확도가 부족할 수 있다. 이를 보완하기 위한 것이 리랭커다.
주로 리랭커는 BERT 등 언어 모델을 사용해 Retrieval 단계에서 얻은 단락들을 재정렬한다. 이런 모델들은 임베딩 모델보다 높은 연산량을 필요로 하지만 정확도가 더 높다. 그래도 Retrieval에서 나온 몇십개 수준의 단락들을 재배열하는 것을 빠르기 때문에, 리랭커를 사용하면 빠른 속도와 높은 성능, 두 마리 토끼를 한 번에 잡을 수 있다.
UPR 리랭커란
UPR Reranker는 “Improving Passage Retrieval with Zero-Shot Question Generation”이라는 논문에 나온 리랭커이다. 깃허브는 여기에.
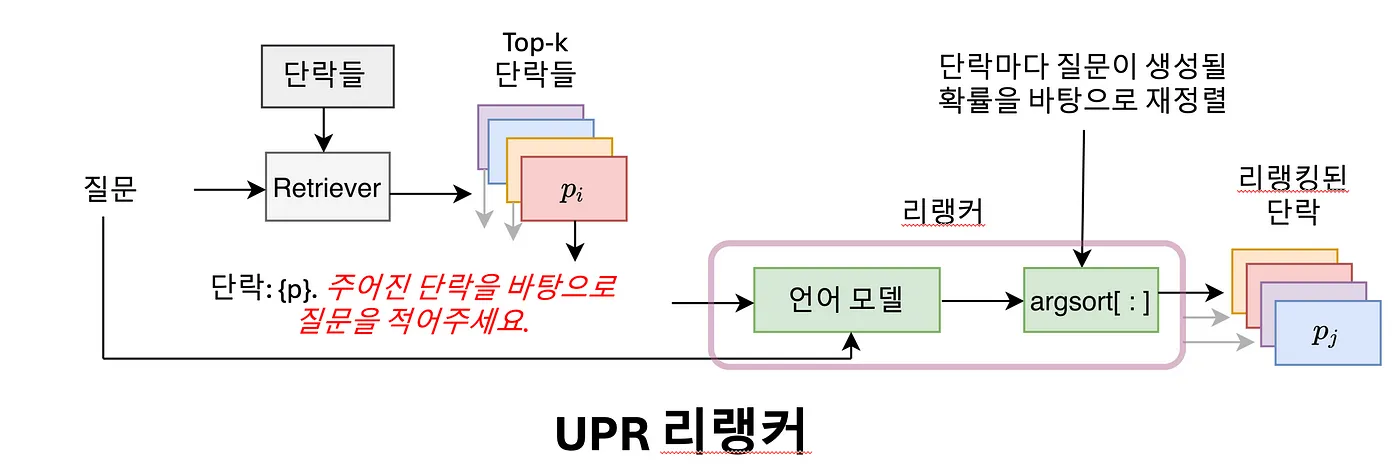
아래와 같이 리랭커가 동작한다.
-
Retrieval에서 가져온 단락들을 언어 모델에 입력한다.
-
언어 모델이 단락만을 보고서 질문을 생성하게 한다.
-
이 때, ‘원래 질문'을 언어 모델이 생성할 확률을 구한다.
예시를 들어서 설명해보겠다.
유저의 질문이 “걸그룹 에스파의 대표곡이 뭐야?”라고 해 보자.
해당 질문로 Retrieval 모듈에 검색하니 아래 단락 3개가 나왔다.
단락 A : 에스파는 2020년에 타이틀곡 Black Mamba로 데뷔한 4인조 걸그룹이다.
단락 B : 에스파 멤버 중 윈터와 카리나는 특유의 케미로 큰 인기를 얻었다.
단락 C : 에스파는 Next Level 곡으로 큰 히트를 거두고, 이 후 Spicy, Drama, Supernova 등의 곡들 역시 큰 인기를 얻었다.
이제 각각의 단락을 보고 질문을 만들도록, 언어 모델에게 입력한다. 예를 들어서, 이런 식으로 언어 모델에 프롬프트가 들어간다.
아래 단락을 보고, 예상 질문을 제작해줘.
단락 A : 에스파는 2020년에 타이틀곡 Black Mamba로 데뷔한 4인조 걸그룹이다.
질문 :
이제 언어 모델은 질문을 만들텐데, 이 때 유저의 질문이 나올 확률을 계산한다.
아무래도 단락 A에서는 “걸그룹 에스파의 대표곡이 뭐야?”라는 질문이 나오기 힘들 것이다.
단락 B 역시 “걸그룹 에스파의 대표곡이 뭐야?”라는 질문은 나오기 힘들다.
반면에 단락 C는 “걸그룹 에스파의 대표곡이 뭐야?”라는 질문을 쉽게 생각할 수 있다.
그렇기에 단락 C가 가장 높은 점수를 받아, 첫 번째 단락으로 재정렬 될 것이다.
어떻게 점수를 매길까?
UPR 리랭커는 어떻게 유저의 질문이 나올 확률을 계산할까? 바로 유저의 질문 토큰이 생성될 확률을 이용한다.
언어 모델은 기본적으로 앞의 토큰들을 통해 뒤에 토큰이 무엇이 올지 확률적으로 예측한다는 사실을 기억하자. 일련의 토큰 뒤에서, 어떠한 특정 토큰이 나올 확률을 구할 수 있는 것이다.
언어 모델에 단락을 넣어주고 질문을 생성하게 하면, 생성하는 동안 유저의 질문에 해당하는 각 토큰들이 나올 확률을 구할 수 있다.
다시 정리하면, 언어 모델에게 질문을 생성하게 할 때, 유저가 물어본 바로 그 질문을 생성할 확률을 구하는 것이다. 그 확률이 곧 점수가 된다.
AutoRAG에서 사용해보기
UPR 리랭커의 성능을 확인해보고 싶다면, AutoRAG에서 간단하게 사용해보자.
YAML 파일 수정으로 간단하게 사용할 수 있다.
아래와 같이 YAML 파일을 구성해 보았다.
node_lines:
- node_line_name: retrieve_node_line
nodes:
- node_type: retrieval
strategy:
metrics: [ retrieval_recall, retrieval_ndcg, retrieval_map]
speed_threshold: 10
top_k: 30
modules:
- module_type: bm25
- module_type: vectordb
embedding_model: openai
- node_type: passage_reranker
strategy:
metrics: [retrieval_f1, retrieval_recall, retrieval_precision]
speed_threshold: 10
top_k: 5
modules:
- module_type: pass_reranker
- module_type: monot5
- module_type: upr # 이곳에서 UPR 리랭커를 사용할 수 있다.
prefix_prompt: "단락 - "
suffix_prompt: "주어진 단락을 바탕으로 사람이 할 만한 질문을 적어주세요."
- module_type: flag_embedding_reranker 위 YAML 파일에서는 Retrieval에서 벡터 유사도 검색과 BM25 방법을 비교한다.
그 후에, 리랭커 단계에서는 리랭커를 안쓰거나, MonoT5, Flag Embedding 리랭커, 그리고 UPR 리랭커의 성능을 비교한다.
이 YAML 파일을 활용해서, 2개의 Retrieval 모듈과 4개의 리랭커 모듈 중 최적의 조합을 빠르게 찾을 수 있는 것이다.
AutoRAG를 설치하고 위 YAML 파일을 이용해 직접 실험하는 방법은 여기를 참고하자.
UPR 리랭커 사용 시 주의점
-
CUDA 사용을 권장한다. CPU도 정상 작동하나 시간이 오래 걸릴 수 있다.
-
첫 실행 시 모델을 다운로드 받아야 하기 때문에 시간이 오래 걸릴 수 있다. 인내심을 가지고 기다리자.
-
영어가 아니라 한국어 등에서 활용할 때는, 반드시 언어에 맞춘 프롬프트를 설정해주자. 위의 YAML 파일처럼 prefix_prompt와 suffix_prompt를 설정해주면 된다.
여기서, 특정 도메인에 알맞은 용어를 사용하면 더 높은 정확도를 보여줄 수 있다.
더 읽어보기
-
AutoRAG 깃허브 => https://github.com/Marker-Inc-Korea/AutoRAG
-
한국어 문서에 BM25 사용 시 주의할 점 => [링크]
