
RAG 평가와 최적화에 가장 중요한 것은 무엇일까? 여러 가지 중요한 것들이 있겠지만, 그 중에서도 어떤 “질문”으로 평가하고 최적화 하느냐가 아주 중요할 것이다.
하지만, 실제로 LLM을 이용해 무작정 질문을 만들어 보면 처참한 성능에 놀랄 것이다. 나보다 훨씬 똑똑한 것 같았던 LLM이 이런 말도 안되는 질문을 만든다고?
이번 포스트에서는 도대체 왜 LLM이 RAG 평가를 위해 좋은 질문을 못 만드는지 알아본다.
RAG 평가용 질문이란?
초입부가 조금 어려웠다면, RAG 평가용 질문이라는 개념부터 잡고 가자.
여기서는 “자동으로” RAG 평가용 질문을 생성하는 것에 대해서만 다룬다.
먼저, RAG가 질문을 받으면, 단락을 가져오고, 그 단락을 이용해 LLM이 대답을 하는 구조라는 것은 모두 알고 있을 것이다.
그러면 어떻게 자동으로 생성할 것인가? 먼저 정답 단락을 선택해야 한다.
그리고 그 정답 단락에서 질문을 만든다. 그러면 자연스럽게 해당 질문의 정답 단락, 즉 retrieval gt는 해당 단락이 될 것이다.
그 이후, 질문과 정답 단락을 제공한 상황에서 LLM의 모범 답안을 만들면 된다.
즉, 단락 선택 ⇒ 단락에서 질문 생성 ⇒ 답변 생성 의 과정을 거쳐 만들어지게 되는 것이다.
얼마나 안좋길래?
도대체 LLM이 질문 생성을 얼마나 못하길래 이러는 것인가? 궁금해 할 것이다.
예시를 들어보겠다.
단락 : 특 허 법 원제25-2부
판 결
사 건 2022나2213 특허권침해금지청구권부존재 확인청구의 소
원고, 피항소인 1. 주식회사 A
대표자 사내이사 B
2. 주식회사 C
대표자 사내이사 D
3. 주식회사 E
대표이사 F
소송대리인 변호사 최서령
소송복대리인 변호사 김민지
피고, 항소인 G 주식회사
대표이사 H
소송대리인 법무법인(유한) 다래. 담당변호사 문린, 민현아
제 1 심 판 결 서울중앙지방법원 2022. 10. 28. 선고 2019가합578947 판결
여러분들이라면 이 단락을 보고 어떻게 질문을 만들 것인가? 이 단락을 찾아야만 정답을 맞출 수 있는 적절한 질문은 아래와 같을 것이다.
사람이 만든 질문 : 2022나2213 사건의 피고측 변호사는 누구인가요?
해당 질문은 문서를 찾아야만 풀 수 있고, 해당 문서를 보고 있다는 가정 하에 한 질문도 아니다. 실제로 사건 번호를 알고 있는 경우 충분히 검색할 만한 질문이라고 보여진다.
하지만 LLM이 실제로 만든 질문은 아래와 같다.
LLM이 만든 질문 : 사건 번호는 무엇인가요?
어이가 없지 않은가?
심지어 위 경우는 아주 똑똑한 LLM인 gpt-4o 모델을 활용한 것이다.
LLM이 만든 저 질문 만으로 해당 문서를 특정할 수도 없거니와, 그 누구도 검색창에 저렇게 입력하지는 않을 것이다.
이곳에서는 단적인 하나의 예시만 들었지만, 많은 단락들에 대한 질문 생성 결과를 보면 이런 식으로 “안 좋아 보이는” 질문들을 생성하는 것을 알 수 있을 것이다.
당신은 할 수 있습니까?
그런데, 당신은 질문을 잘 만들 수 있나요?
만약 당신에게 아래와 같은 단락을 보고 “좋은” 질문을 생성해 보라고 부탁했다고 생각해보자.
(20)과 구이용 회전팬(20\')이 별도로 구비된다. 먼저 끓임용 회전팬(20)은 도 2에서 보는 바와\n같이 마치 솥뚜껑을 뒤집어 놓은 것처럼 아래로 볼록하고 하면 중앙에 축돌기(21)가 형성되\n고. 이 축돌기(21)는 상기 축공(11)에 분리 가능하게 삽입된다. 또한 구이용 회전팬(20\')은 도\n3에서 보는 바와 같이. 상기 축돌기(21)에 축방향으로 기름배출공(22)이 관통된다. 그리고, 구\n이용 회전팬(20\')을 사용할 경우에는 앞서 설명한 바와 같이 상기 받침대(10) 내부. 즉 기름배\n출공(22) 하부에 기름받이통(12)이 배치된다.\n【도 3】\n구이용 회건전\n기름방송능\n받침대사 7 기름발이통\n이 사건 특허발명의 정정청구서(제12~13쪽)\n정정사항 1은 이 사건 제1항 발명의 축공(11)을 \'관통형\'으로 한정한 것이므로 청구범위를\n감축한 것에 해당합니다.\n이 사건 특허발명의 명세서 식별번호 <14>에는 "그리고, 구이용 회전팬(20\')을 사용할 경우\n에는 받침대(10) 내부, 즉 상기 축공(11)의 하부에 기름받이통(12)이 배치된다."라고 기재되어\n있는 점. 식별번호 <15>에는 "이 축돌기(21)는 상기 축공(11)에 분리 가능하게 삽입된다."\n"또한 구이용 회전팬(20\')은 도 3에서 보는 바와 같이. 상기 축돌기(21)에 축방향으로 기름배\n출공(22)이 관통된다.
으악! 일단 읽기부터가 싫다. 일단 질문을 만드려면 이해부터 해야 할 것 같은데, 참… 변리사도 아니고 우리 같은 사람들은 이해하는 것부터가 일이다. 어찌저찌 하더라도 내가 만든 질문이 좋은 질문인지 어떻게 장담할 수 있을까?
Bloom’s Taxonomy
이렇게 “좋은” 질문을 만드는 일은 매우 어렵다. 이렇게 어려운 것은 다름이 아니라 진짜 어렵기 때문이다.
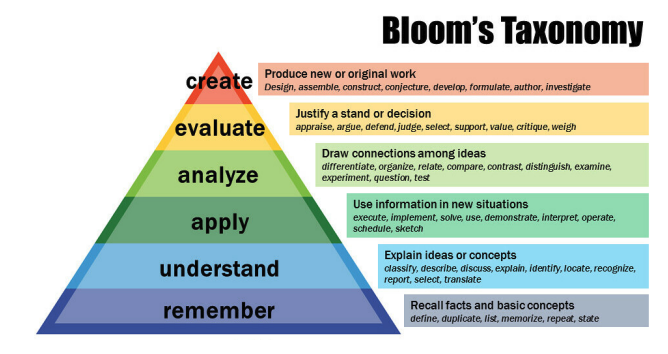
이것은 Bloom’s Taxonomy라는 것이다.
사람이 인식적으로 할 수 있는 행동들에 대한 복잡도를 나타낸 것이다.
아래부터 기억 - 이해 - 적용 - 분석 - 평가 - 창조이다.
즉, 창조는 가장 어려운 것에 속한다.
그리고 질문 생성은 바로 창조에 속한다. 이런 창조를 하기 위해서는 해당 내용에 대해서 완벽하게 이해하고 주변 지식들까지 습득한 상태여야 한다. 또한, 사람들이 해당 도메인에서 어떤 유형의 질문을 많이 하는지 이해하고 그것을 주어진 단락에 적용해서 질문을 만들어 내야 한다.
이것을 과연 LLM이 효과적으로 수행할 수 있는가?
“좋은” 질문은 무엇인가요?
RAG 평가에 “좋은” 질문은 무엇인가?
일단 현실적인 질문일수록 좋을 것이고, 너무 어려워도 안 되고 또 그렇다고 너무 쉬워서도 안될 것이다.
자 그러면 “현실”적인 질문은 무엇인가? 어려운 질문은 무엇이며, 또 너무 쉬운 질문은 무엇인가?
명확하게 답하기가 힘들다. 만약 어떤 도메인에서 대강 정의했다 하더라도, 다른 도메인으로 바꾸면 또 기준이 달라진다.
이렇듯 “좋은 질문”은 정의하는 것부터가 만만치가 않다.
정의를 못하기 때문에, 가장 처음으로 해 볼 만한 프롬프트 엔지니어링도 쉽지 않다.
나도 무엇을 원하는지 모르고 추상적으로 표현할 수 밖에 없기 때문이다.
어떻게 해야 할까?
좋다. 가장 똑똑한 LLM 이더라도 아직 RAG 평가용 질문 생성에는 부족한 점이 많다.
그러면 어떻게 해야 할까? 일일이 사람 써가면서 질문을 만들어야 할까?
물론, 전문가가 질문을 직접 만들어 주면 그것만큼 좋은 것이 없을 것이다. 하지만 그럴 만한 돈과 시간이 있었다면 애초에 자동 생성은 고민하지도 않았을 것이다.
전문가들이 데이터가 추가되면 매번 질문을 업데이트 해줄 것인가?
아직 완벽하지는 않지만 좋은 질문 생성을 위한 수많은 시도가 이루어지고 있다. AutoRAG 팀도 많은 삽질을 했고, 또 하고 있다.
추후 블로그 포스트에서 그러한 시도를 적어보겠다.
추가로, 현재 AutoRAG RAG 평가용 데이터 생성을 위한 기능을 대거 리팩토링 하고 있다.
곧 배포가 완료되면 관련해서 튜토리얼 포스트 역시 작성해 보겠다.

정말 좋은 글인 것 같습니다. 저는 의학 분야에서 RAG 연구를 진행하고 창업을 추진하고 있습니다. 제가 판단한 문제점은 다음과 같습니다.
1. 문서화되지 않은 맥락 - 우리가 암묵적으로 알고있는 context를 본문에 명시하거나 추가적으로 가져와야 합니다.
2. 지식의 계층 - 우리가 소위 "먼저 배우는 지식"과 "나중에 배우는 지식"이 있습니다. 항상 좋은 질문은 제시된 context에서 가장 나중에 배울 수 있는 질문이 좋은 질문으로 평가받는 것 같습니다.
3. 결국 글쓰기 문제 - 핵심 내용을 왜곡하지 않으면서 짧은 글이 좋은 글입니다. 짧고 핵심이 바로잡힌 글을 넣었을 때 성능이 향상됩니다.
결국 저는 지식을 나눠서 표현해야 한다고 생각합니다. 한 글 안에서도 다양한 지식으로 분해해서 DB에 저장할 수 있을 것 같습니다.