AI, 머신러닝 분야에 관심을 가지고 지켜보시는 분들은 Kaggle이나 AIclowd, 데이콘 등 많은 대회를 통한 집단 지성으로 문제를 해결하는 모습을 지켜봐왔을 것이라고 생각합니다. 또한 그 대회에 참가하면서, 스스로 많은 성장을 이룩하기도 합니다.
오늘은 **Google — AI Assistants for Data Tasks with Gemma 대회의 우승팀의 풀이과정**을 함께 살펴보고자 합니다. 자신의 코드에 대해 잘 설명하는 것 또한 대회의 평가항목이었기 때문에 LLM과 RAG를 잘 모르더라도 많은 도움이 될 것이라 생각합니다.
✅대회는 Gemma를 활용하여 Kaggle을 위한 5가지 주제를 바탕으로 AI Assistant 구축을 목표로 합니다.
❗주제
-
data science 관련 지식에 대해 가르쳐주거나 설명해주기
-
python 에 대한 질문에 답변해주기
-
Kaggle 솔루션 내용 요약하기
-
Kaggle 대회 솔루션의 개념을 설명하거나 가르쳐주기
-
Kaggle 플랫폼에 대한 일반적인 질문에 대해 답하기
평가 방식 다음과 같습니다.
Technical: few-shot 프롬프팅, Retrieval-augmented generation, fine-tuning 등의 전략을 효율적으로 사용했는가?
Descriptive: 코드가 잘 설명되어있는가?
Useful: 해당 코드가 주제에 맞추어 도움이 되거나, 고품질의 결과를 생성하는가?
Robust: test의 추가적인 input에도 잘 작동하는가?
이 중
-
data science 관련 지식에 대해 가르쳐주거나 설명해주기
-
python 에 대한 질문에 답변해주기
에 집중하여 data science 관련 지식에 대해 가르쳐주거나 설명해주기에서 수상한 분의 대회 도전 과정을 살펴보며 인사이트를 알아보도록 하겠습니다.
✅Build AI Agents With Google’s LLM Gemma By Sita Berete
(원문 링크)
1️⃣. Vanilla Gemma
📎 Gemma 종류
이 대회는 모델의 사용이 Gemma로 국한되어있습니다. sita berete는 AI를 활용한 서비스를 제작하기 전 가장 먼저 RAG나 여러 기법 없이 어떤 일을 할 수 있는가 살폈습니다.
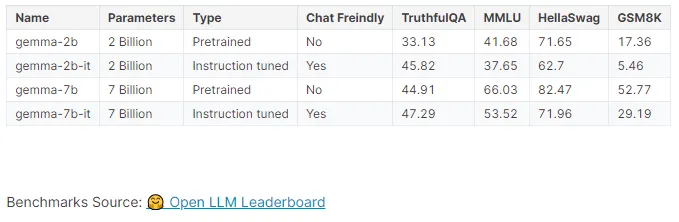
이론적으로 모델이 클수록 더 나은 성능을 보여주는 경우가 많습니다. 또한, 챗봇을 구현해야 하기 때문에 chat freindly한, instruction tune이 되어있는 모델을 사용하는 것이 좋아 보입니다.
옆에 있는 benchmark는 각각 진실성(Truthfu QA), 다양한 주제에 걸친 폭넓은 지식의 이해와 적용(MMLU), 상식 기반 추론 능력(Hella Swag), 수학 연산 능력(GSM8K)에 관한 점수를 나타내고 있습니다.
📎 요구 메모리
hugging face hub에 있는 모델이라면 hugging face가 제공하는 Model Memory Calculator tool을 통해 추론에 필요한 메모리양을 어느정도 ‘추정’해볼 수 있습니다. (total size)
아래 숫자 자료형들은 양자화를 의미합니다. 간단하게 해당 자료형으로 연산을 수행하여 정밀도를 조금 희생하면서 사용 메모리를 줄이고 추론속도를 높이는 기술입니다.

🤔 Gemma를 이번 문제에 테스트 해보기
Gemma 시리즈의 모델 중 2b-instruct tune, 7b-instruct tune, 7b 에게 이번 task와 관련된 프롬프트를 넣고 대답하게 했습니다.
prompt_1 = "What is Data Science?"
prompt_2 = "Explain 3 important Data Science concepts, and tell why each concept is important"
prompt_3 = "I'm a marketing specialist, I know nothing about Data Science. Explain to me what Data Science is and simplifie it as much as you can. When possible, use analogies that I can understand better as a marketing specialist"
#데이터 사이언스는 무엇인가?
#3가지 중요한 Data Science 개념 설명, 각 개념이 중요한 이유 설명해줘.
#저는 마케팅 전문가입니다. Data Science에 대해 아는 것이 없습니다. Data Science가 무엇인지 설명하고 가능한 한 단순화하십시오. 가능하면 마케팅 전문가로서 더 잘 이해할 수 있는 유사점을 사용하세요.아직 관련 지식이 없을 것으로 예상되는데, 이 output을 토대로 요구사항을 잘 이해하는 지, 이후 이 모델을 중심으로 파이프라인을 구축할 때 좋은 기대를 할 수 있을 지 추측해봅니다. 만일 2b와 7b중 2b가 7b 만큼 성능이 잘 나온다면, 문제 없이 메모리를 더 적게 사용하는 2b를 선택하겠지만, 이 노트북에서는 창의성과 이해의 측면에서 7b가 더 높다고 판단했습니다. 하지만 출력물을 봤을 때 미세조정이 필요하다고 생각되었습니다. (출력물은 원 노트북을 참고해주세요!)
2️⃣. 미세 조정(Fine-Tuning)
📌개념
미세 조정은 기본 모델이 가지고 있는 지식을 활용해 downstream 작업을 수행할 수 있도록 모델을 학습시키는 과정입니다. 위에서 등장한 Model Memory Calculator tool를 이용할 때 유심히 보셨으면 아셨을 수도 있지만, 추론보다 훨씬 많은 메모리를 요구합니다.(parameter, optimizer, gradient 등을 임시저장 해야하므로)
따라서 이 노트북에서는 PEFT(Parameter-Efficient Fine-Tuning)를 사용합니다. 모델의 일부만을 학습시켜서 새로운 작업에 좀 더 집중된 모델을 만드는 것입니다.
✨종류
특정 레이어를 얼리고 일부만 학습시키는 선택적 미세조정(Selective Fine-Tuning) 방식과 낮은 차수이고 적은 양의 파라미터만을 이용해 모델을 조정하는 재파라미터화(Reparameterization, 예 LoRA), 그리고 특정 작업을 위해 사전 학습 모델 위에 새로운 모듈 혹은 레이어를 추가하는 Additive Methods가 있습니다.
물론 캐글의 환경에서 컴퓨팅 자원이 열악하기 때문에 이러한 선택을 하는 것도 하나의 원인 이겠지만, 적은 양의 파라미터를 학습시키기 때문에 비교적 적은 데이터를 필요하고, 모델을 망가뜨릴 위험이 낮으면서도, 꽤나 쓸만한 모델이 만들어지기 때문에 PEFT가 좋은 선택이 될 수 있습니다. 지금 가지고 있는 데이터가 적다는 점이 PEFT를 선택하는 주요하고 확실한 원인이 되겠습니다.
🤔시행착오 — data gen, QLoRA 결정
훈련데이터를 이용해 미세조정하여 몇 번 test를 해보았지만, 5가지의 task가 모두 섞여있었기에 프로그래밍 작업을 실행하는 훈련모델이 나왔고, 이는 현재 하고 있는 data science 관련 지식 설명을 위한 코딩의 목적과는 달랐습니다. 따라서 특정 작업/ 도메인이 아닌 data science 개념(선형 회귀, PCA 등)을 설명하는 미세 조정용 데이터셋이 필요하다고 생각했습니다. 이러한 미세 조정은 prompt engineering을 적절히 수행하면, 충분히 좋은 성능을 낼 수 있기 때문입니다!
그래서 Gemini와 Github copilot을 이용해 DSI-Coder Dataset | Teach Data Science Programming dataset을 구축하기로 하였고, gemini로 ~10개의 예제를 만들고 Github copilot의 Autocomplete을 통해 총 181개의 미세조정을 위한 데이터셋을 구축하였습니다. 이후 Gemma 스타일로 데이터셋을 변환해주고 QLora로 학습시켰습니다.
미세 조정이 항상 필요한 것은 아니기에 항상 prompt engineering을 시도해보시는 것을 권장드립니다. 또한 미세 조정은 훈련 데이터셋의 질에 크게 좌우되기 때문에, 쓸만한 공개 데이터가 없거나 양이 적다면, 자신만의 데이터 셋을 제작하는 것이 좋을 때도 있습니다.
3️⃣.RAG(검색 기반 생성,Retrieval-Augmented Generation)
사실 정확성과 최신 정보 접근에 대해 LLM은 고질적인 문제를 가지고 있기 때문에 이를 완화하기 위해 외부 지식 소스에서 검색하여 가져온 데이터를 이용해 prompt에 적절히 추가하여 답하게 하는 RAG가 필요합니다.
이러한 RAG는 사실 정확도, 분야의 특수성, 유연성과 적응, 투명성과 신뢰성 측면에서 LLM보다 더 높은 이점을 가져다 줍니다.
데이터 소스는 Data science를 설명하는 이번 문제와 관련이 있는 “Python Data Science Handbook”과 함께 Wikipedia를 이용해 직접 만든“ Wikipedia Data Science Articles Dataset”을 이용했습니다.
📎 Retriever
Retriever는 Indexing을 어떻게 하는가에 따라 keyword indexing, entity indexing, TF-IDF, semantic Indexing 등이 포함됩니다.
LLM의 입력 토큰에는 한계가 있기 때문에 문서는 분할(chunking)되어야 합니다. 하지만 분할 시 보통 작게 자르면 문맥이 손실되고, 크게 자르면 임베딩의 정확도가 떨어지기 때문에 ParentDocumentRetriever를 사용했습니다.
4️⃣. Agent
AI Agent는 다양한 옵션을 고려하고 잠재적인 결과를 고려한 다음 목표를 달성할 가능성이 가장 높은 행동 방향을 선택합니다. 따라서 추론은 Agent를 위해 꼭 필요한 능력입니다. 요구되는 추론의 수준은 문제마다 다르겠지만요.
이번엔 ReAct(Reasoning and Acting)를 이용합니다. 이번 단계에서 추론 후 어떤 행동을 취할지 결정하는 방법입니다. 보통 질문 답변, 사실 확인 및 대화형 의사 결정에 적합합니다. 행동으로 추가적인 정보를 수집할지, 답변을 할 지 혹은 어떤 도구(검색, API 등)를 사용할지 결정합니다.
📌ReAct의 구조
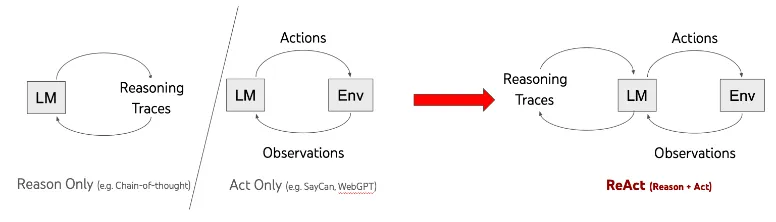
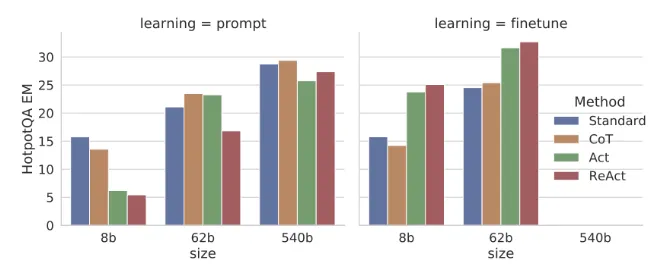
위 차트는 CoT, AcT, ReAct등 다양한 유형의 Agent가 LLM의 파라미터 수에 따라 어떻게 작동하는지 나타낸 chart 입니다. Gemma를 사용해야만 하는 상황이고, 2b와 7b가 있기 때문에 모델이 큰 7b를 reasoning을 위해 사용해야 할 것으로 보입니다. 흠.. 그런데 finetune을 시도하기 전에 필요한지 알기 위해 test 후에 실험 후에 결정해야할 것 같습니다.
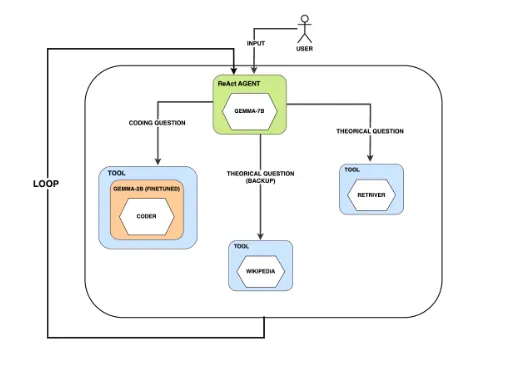
coder는 아까 fine-tuning한 code 설명 모델. 초록 부분이 계획 즉 ReAct구조에서 Reasoning에 해당합니다.
🤔시행착오
아래는 질문과 현재 구현된 Agent의 응답입니다.
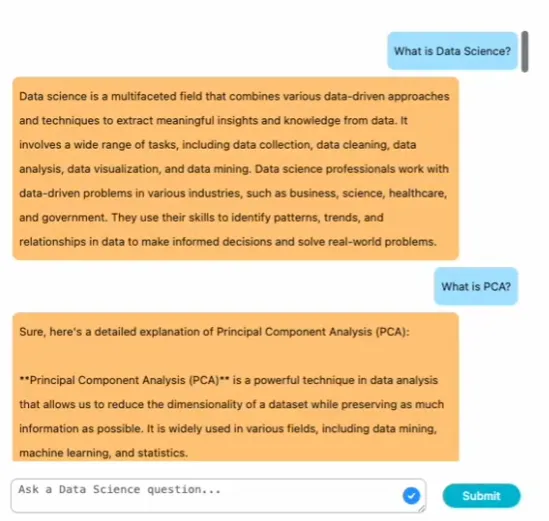
잘 대답해내는 군요!
추론에 있어서 python 에 관한 질문인지, data science에 대한 질문인지에 있어서 7b-it, prompt 기반 Reasoning에서 좋은 성능을 내는 것으로 판단했습니다.
⌛정리
📝모델 선택과정
-
모델을 선택할 때 벤치마크를 참고합니다.
-
실제와 매우 유사한 문제를 간단히 실험해보면서 성능을 고려합니다.
-
가지고 있는 컴퓨팅 자원을 기준으로 메모리를 고려합니다.(양자화 등)
📝Python 코딩 모듈
-
fine tuning은 컴퓨팅 자원과 데이터, 잘 될지 모른다는 불확실성 또한 내포되기 때문에 최후의 보루입니다.
-
항상 실험을 기반으로 판단해야 합니다. 목표를 명확히 하세요.
원하는 작업중에 python의 일반적인 질문을 해결하기 위해 코딩 능력이 필요했다. 가능한 모델은 gemma 뿐이었고, coding이 지원되는 모델이 없었습니다. 따라서 fine tuning을 선택했습니다.
데이터가 없어 직접 목적에 맞게 데이터도 제작하였습니다. 리스크 관리, 컴퓨팅 자원 등의 이슈로 PEFT 방식 중 QLoRA를 이용했습니다. test 결과 잘 나왔습니다.
📝Data Science 질의응답용 RAG 모듈
-
사실 정확도, 분야의 특수성이 있는 분야에는 RAG를 적극 검토합니다.
-
항상 실험을 기반으로 판단해야 합니다. 목표를 명확히 하세요.
지식 관련 질의 응답을 위해 RAG를 구축했습니다. 데이터가 제공되지 않아 위키피디아와 python handbook을 이용했습니다. 잘 나오도록 실험을 반복하며 조정했습니다.
📝Routing을 위한 Agent 구축
-
하나의 서비스에서 많은 기능을 제공해야한다면, Agent의 구조를 실험하세요.
-
기능을 모듈화하고 모듈을 잘 사용할 수 있는 똑똑한 모델을 추론에 활용하세요.
-
이 또한 항상 실험을 기반으로 판단해야 합니다.
하나의 AI 시스템에서 복수의 기능을 수행해야 하므로 routing을 수행하는 Agent를 도입했습니다. ReAct 방식을 이용했습니다. 실험 결과 7b prompt로도 이 작업을 잘 수행해냈습니다.
🏁 마무리
돌고 돌아 결국 필요한 실험을 반복하며 찾아가는 것은 AI를 활용한 좋은 시스템을 구축하는 불변의 법칙입니다. 다만 이러한 모듈을 찾고 구현하고 실험하는 과정은 상당히 시간이 오래 걸리는 작업입니다. 결국 새로운 작업이라면 그 작업을 기준으로 모듈이 적합한지 알아야 하기 때문입니다. 그렇다면, AutoRAG와 함께 빠르게 실험하고 좋은 AI 시스템을 구축해보는 것은 어떨까요?
