자료구조 ( Data Structure )
자료구조란 프로그래밍에서 효울적인 데이터를 조직적으로 관리하여 구조적으로 표현하는 방식과 이를 구현하는 데 필요한 기능을 가능하게 하는 기술입니다. 보다 구체적으로 설명하자면 , 자료구조는 데이터 값의 집합과 각 데이터의 관계 , 데이터에 적용 시킬 수 있는 함수나 명령이 포함되는 것 입니다.
- 자료구조란 여러 데이터들의 묶음을 저장하고 , 사용하는 방법을 정의한 것
자료구조의 중요성
잘 짜인 자료구조는 메모리 용량을 최소한으로 사용하게 할 수 있고 실행시간을 단축 시킴으로써 보다 효율적인 알고리즘을 실행 할 수 있는데에 도움을 줍니다. 어떤 프로그램을 설계하는지에 상관없이 자료구조를 선택하는 것은 가장 우선적으로 고려되어야 할 내용이고 매우 중요합니다. 큰 프로젝트를 만드는 경우 최정 결과물의 성능이나 구현의 어려움 등이 자료구조에 크게 의존하기 때문입니다. 자료구조가 우선적으로 선정되고 나면 해당 프로젝트에 적용될 알고리즘은 보다 명확해집니다. 이런 관점에서 기존의 정형화된 개발론에서 알고리즘이 자료구조보다 중요한 요소라는 상식을 뒤집었고 , 자료구조가 알고리즘보다 중요한 요소로 적용되는 개발론과 프로그래밍 언어의 개발이 가속화 되고 있습니다. 자료구조를 통해 대규모의 데이터를 쉽게 관리하고 활용하는 데 있어 어려움이 줄어들며 데이터베이스에서 원하는 데이터를 찾기도 쉬워집니다. 개발자는 사용자의 요구사항에 알맞은 것을 개발하고자 하는 프로그램에 필요한 맞춤 알고리즘을 설계 할 수 있습니다. 또한 동시에 사용자들이 요구하는 여러 요청사항을 한번에 처리하여 데이터 처리속도를 향상시키며 처리과정도 단순화 할 수 있습니다.
- 잘 짜인 자료구조는 메모리 용량을 최소한으로 사용합니다.
- 실행시간을 단축시켜 효율적인 알고리즘 실행을 도와줍니다.
- 데이터를 관리하고 활용하는데에 어려움이 줄어듭니다.
- 성능이나 구현의 어려움 등이 자료구조에 크게 의존합니다.
자료구조의 종류
1. 배열(Array)
배열은 가장 일반적인 자료구조입니다. 동일한 타입의 데이터들을 저장하며 고정된 크기를 갖고 있습니다. 일반적으로 배열에는 같은 종류의 데이터들이 순차적으로 저장되어 있으며 생성되는 순간 설정되는 데이터에 인덱스가 부여되어 인덱스 번호를 이용하여 데이터를 지정할 수 있습니다.

const tempArr = ["하나","둘","셋"];
console.log(tempArr[2])
// 셋 - 첫 인덱스는 0부터 시작되어 셋이 2번이 됩니다.장점
배열은 바로 만들어서 활용하기 쉽고 원하는 데이터를 효율적으로 검색하여 가져오는 게 가능하고 배열을 기반으로 하여 더 복잡한 자료 구조를 만들 수 있으며 정렬이 용이하다는 장점이 있습니다.
단점
데이터를 저장할 수 있는 메모리의 크기가 고정되어 있고 데이터를 추가 , 삭제하는 과정이 비효율적입니다. 데이터가 삭제 되고 나면 남은 공간은 빈 공간이 되어 메모리의 낭비가 심합니다.
배열이 차지하는 메모리의 크기 = 배열의 길이 X sizeof(타입)
배열의 길이 = sizeof(배열 이름) / sizeof(배열 이름[0])
- 데이터가 순차적으로 저장되며 고정된 크기를 갖습니다.
- 데이터가 저장되는 순간 인덱스가 부여되어 인덱스 번호로 데이터를 지정 가능합니다.
- 데이터 삽입 시 인덱스의 데이터를 덮어쓰는 형태로 삽입합니다.
- 데이터 삭제시 해당 데이터 인덱스는 메모리가 비어있는 상태가 됩니다.
2. 연속 리스트(Contiguous List)
연속리스트는 배열처럼 연속적인 기억 장소에 데이터가 저장되는 자료구조입니다. 연속적으로 데이터가 저장되어 있어 검색에는 용이하지만 , 데이터 삽입이나 삭제는 용이하지 않습니다. 삽입과 삭제가 일어나는 경우 자료의 이동이 필요하다는 번거로움이 있기 때문입니다.
- 데이터 삽입 시 데이터를 한 칸식 뒤로 밀고 해당 자리에 삽입합니다.
- 데이터 삭제 시 삭제된 데이터의 자리에 뒤에 있는 데이터들이 한칸씩 전진하여 채워집니다.
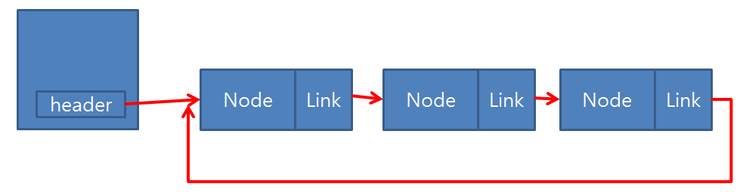
3. 연결 리스트 (Linked List)
데이터를 임의의 기억공간에 기억시키되 , 데이터 항목의 순서에 따라 노드의 포인터를 이용하여 서로 연결시킨 자료 구조입니다. 각 노드는 데이터와 포인터를 가지고 있으며 한 줄로 연결되어 있는 방식으로 데이터를 저장합니다. 각 노드들의 포인터는 다음이나 이전의 노드와의 연결을 담당합니다.
- 각 요소는 Node
- 각 Node 에는 key와 다음 노드를 가리키는 포인터인 next가 포함
- 첫번째 요소는 Head 마지막 요소는 Tail
단순 연결 리스트(Single Linked List)
- 각 노드에 자료 공간과 한개의 포인터 공간이 있으며 각 노드의 포인터는 다음 노드를 가리킵니다.

이중 연결 리스트 (Doubly Linked List)
- 이중 연결 리스트의 구조는 단일 연결 리스트와 비슷하지만 , 포인터 공간이 두 개가 있고 각각의 포인터는 앞의 노드와 뒤의 노드를 가리킵니다.

원형 연결 리스트
원형 연결 리스트는 일반적인 연결 리스트에 마지막 노드와 처음 노드를 연결시켜 원형으로 만든 구조입니다.
장점
- 연결 리스트의 장점은 새로운 데이터를 추가하고 삭제하는 것이 용이하고 효율적입니다.
- 배열처럼 메모리에 연속적으로 위치하지 않고 구조의 재구성이 필요 없습니다.
- 메모리를 더 효율적으로 사용할 수 있기에 대용량의 데이터 처리에 적합합니다.
단점
- 연결이 끊어지면 다음 노드를 찾기가 어렵고 속도가 느리다는 점
- 배열과는 다르게 특정 위치의 데이터를 검색하는데 시간이 걸립니다.
4. 스택 (Stack)
스택은 선형구조이며 순서가 유지되는 선형 데이터 구조입니다. 리스트의 한쪽에서만 데이터의 삽입과 삭제가 일어나므로 , 가장 마지막 요소부터 가장 처음 요소를 처리하는 LIFO(Last In Firt Out) 매커니즘을 갖고 있습니다. 기억공간이 부족한 경우 데이터를 삽입하는 경우 오버플로우(Overflow)가 발생하고 삭제할 데이터가 없을 때 데이터를 삭제하고자 하면 언더 플로우(Underflow)가 발생합니다. 데이터를 받은 순서대로 정렬하고 메모리의 크기가 동적이지만 한번에 하나의 테이머나 처리할 수 있는 불편함이 있습니다.

5. 큐(Queue)
Queue는 선형구조이며 스택과 비슷하지만 먼저 입력된 요소를 먼저 처리하는 FIFO(First In First Out)매커니즘을 갖고 있습니다. 리스트의 한쪽에서는 삽입이 일어나고 다른 쪽에서는 제가 일어나며 데이터의 시작 부분을 프론트(Front)라 하고 끝 부분은 리어(Rear)라고 합니다. 나중에 집어 넣은 데이터가 먼저 나오는 스택과는 반대되는 개념입니다.
장점
- 동적인 메모리 크기와 빠른 런타임이 있습니다.
단점
- 가장 오래된 요소만을 가져오고 한번에 하나의 데이터만 처리합니다.

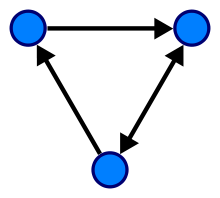
6. 그래프(Graph)
그래프는 비선형구조이며 정점(Vertex)과 간선(Edge)으로 이루어진 데이터 구조이며 사이클이 없는 그래프를 특별히 트리라고 합니다. 꼭짓점과 꼭짓점을 잇는 변으로 구성되며 방향 그래프와 무방향 그래프가 있습니다.
장점
- 새로운 요소들을 추가나 삭제가 용이하며 구조를 응용하기에 적합합니다.
단점
- 데이터간에 충돌이 일어날 수 있습니다.
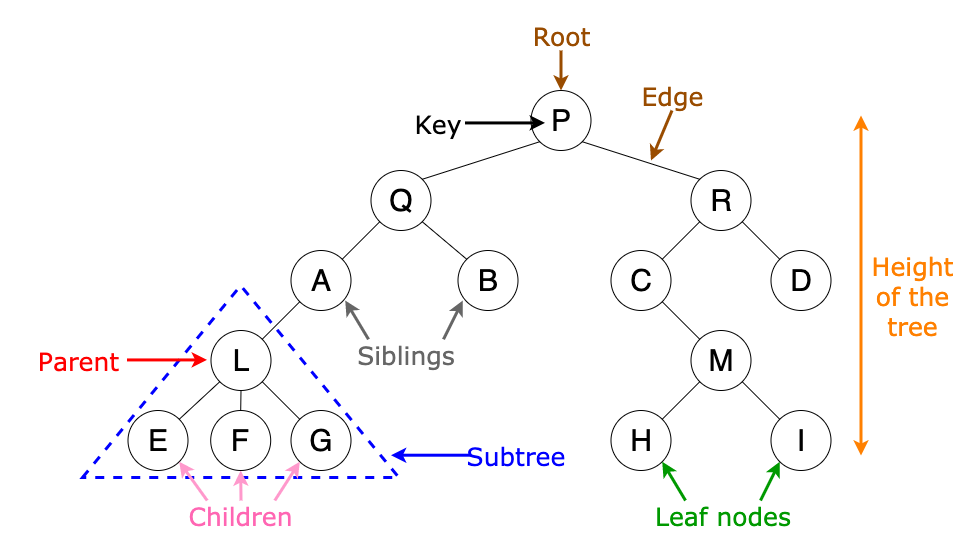
7. 트리(Tree)
트리는 비선형 구조이며 노드(Node)로 구성된 계층적인 자료구조 입니다. 최상위 노드(Root)를 만들고 그 아래에 자식을 추가하는 방식으로 트리구조는 다양하게 구현할 수 있습니다. 노드와 노드를 잇는 선을 간선(Edge)이라합니다. 같은 부모(Parent) 노드를 가지며 같은 레벨에 있는 노드를 형제(Siblings) 노드라 하고 자식이 없는 노드를 단말(Terminal) 노드라고 합니다.