Item 6 : 불필요한 객체 생성을 피하라
Conclusion
몇몇 이유를 빼면 객체 하나를 재사용하는 편이 보통의 경우 퍼포먼스적으로 이득이다.
또, 본인은 그걸 의도하지 않았더라도 새로운 객체를 생성하는 경우를 주의하라.
몇몇 이유 : 보안, thread safe, stream
In case
책에서 여러 케이스를 지적하지만 뭔가 하나같이 레벨이 다른 이야기라 일단 정리를 해야할 필요가 있다.
책에서는 다음과 같은 케이스를 지적하고 있다.
// String s = new String("bikini"); // dont do this!
String s = "bikini";
자바는 메모리 오버헤드를 줄이기 위해서 소스코드 내 상수를 힙 영역의 상수 풀에 저장해두고 같은 상수를 사용해야할때 상수 풀에서 불러다 사용한다.
위의 new String("bikini"); 의 경우 힙 영역에 저장되는 상수 풀에서 가져다 쓰는게 아니라 새로운 스트링을 수행될때마다 생성하므로
재사용해야하는 케이스중 하나로 설명하고 있다.
또, 정적 팩토리 메서드를 제공하는 불변 클래스는 해당 메서드를 사용할것을 권장한다.
//Boolean b = new Boolean("false");
//Integer i = new Integer(10);
//
Boolean b = Boolean.valueOf(false);
Integer i = Integer.valueOf(10); // 이 경우에도 미리 -128~+127 까지를 미리 캐시해두었다고 한다. Long도 마찬가지
위 같은 new 키워드를 이용한 생성자를 이용하기 보다는 아래와 같이 정적 팩토리 메서드를 사용하기를 권장하는데,
사실 이것도 바보짓이고 그냥 하던대로
Boolean b = Boolean.FALSE;
Integer i = 10;
위처럼 사용하면 된다.
자동으로 컴파일러가 해당 클래스의 팩토리 메소드처럼 사용하기 때문이다.
public static class RomanNumerals {
private static final Pattern ROMAN = Pattern.compile(
"^(?=.)M*(C[MD]|D?C{0,3})"
+ "(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$"
);
public static boolean isRomanNumeral(String s) {
return ROMAN.matcher(s).matches();
}
} // use this
static boolean isRomanNumeral(String s){
return s.matches("^(?=.)M*(C[MD]|D?C{0,3})"
+ "(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$");
}
위의 경우 앞에서 말한 상수 풀과는 관계 없이, String.matches 메소드가 내부적으로 숨기고 있는 의존성인 Pattern 클래스의 재사용에 관해서 이야기 하고 있다.
Pattern은 String.matches 메소드 안에서 한번 사용되고 버려지므로, 캐시처럼 static final로 만들어두고 사용하는것을 권하고 있음.
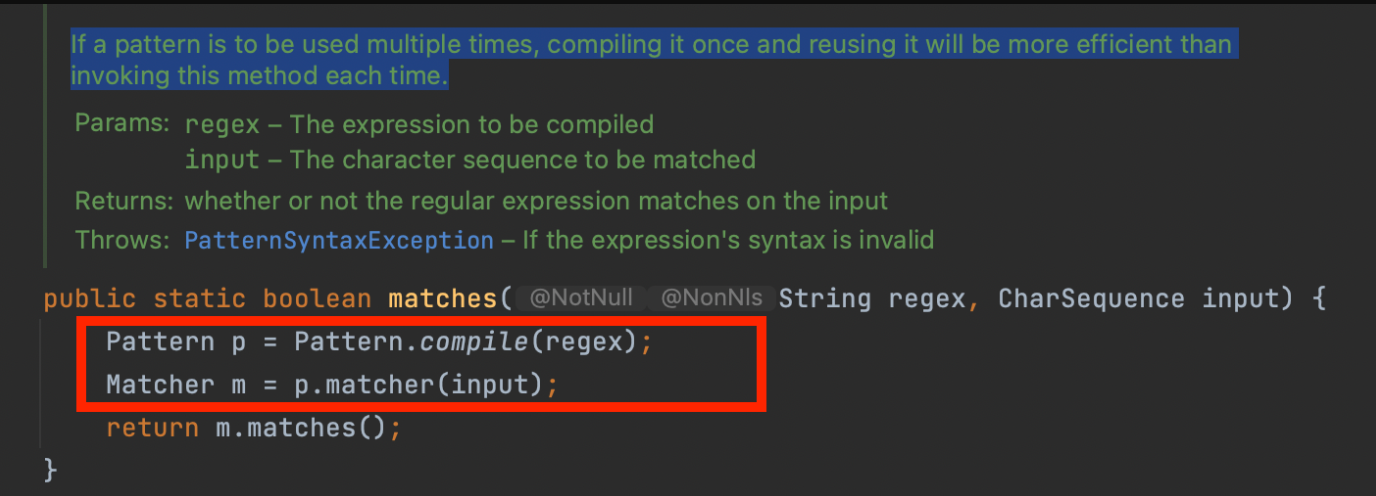
심지어 java doc으로 자주 사용 된다면 해당 메소드를 여러번 사용하는 것보다 pattern 을 한번 구워서 사용하는게 효율적이라고 적어놨음.
Map<String, Object> map = new HashMap<>(){{
put("개똥아", null);
put("똥쌌니", null);
}};
Set<String> keys = map.keySet();
map.put("아니오", null);
Set<String> keysAfterPut = map.keySet();
System.out.println(keys == keysAfterPut); // returns true
System.out.println(keys.size()); // 3
System.out.println(keysAfterPut.size()); // 3
책에서는 번역이 약간 이상하게 출판되었음(빡쳐서 번역자 누군지 찾아봄)
책에 나온 내용은 무시하고, 이런 케이스가 있다 정도로만 파악 하면 될거같음.
Map 인터페이스의 keySet 메소드는 Map의 Key를 전부 Set의 형태로 리턴한다.
하지만 반환하는 Set이 Map의 동작에 영향을 받으므로 단순한 뷰 객체라고 볼수있다. 그래서 해당 객체를 사용해야할때마다 여러개 만들 필요가 없다는 케이스를 설명하고 있다.
private static long sum() {
// Long sum = 0L; // cause Boxing <> Unboxing
long sum = 0L;
for (long i = 0; i <= Integer.MAX_VALUE; i++) {
sum += i;
}
return sum;
}
위의 코드는 primitive 타입인 long 과 reference(primitive wrapper) 타입인 Long 의 연산시
두 타입끼리의 정상적인 연산을 편하게 도와주는 Auto boxing시 생성되는 객체에 대해 설명하고 있다.
간단하게 설명하여 reference 타입인 Long은 불변형이고,
Long 타입의 + 연산은 내부적으로 Long 객체를 새로 만들어 리턴하므로 sum += i; 가 수행될때마다
새로운 Long 객체를 만들어내므로 의도치 않은 객체 생성을 하지 않도록 주의 하라는 내용이다.
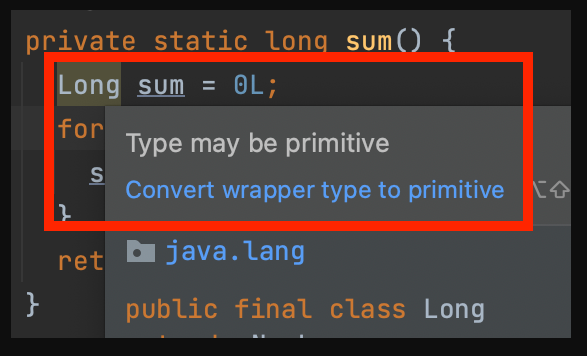
참고로 갓텔리제이는 친절하게 경고도 해주니 인텔리제이 씁시다.
in my opinion
일부 불변 클래스를 사용할때는 new 키워드 대신 정적 팩토리 메서드를 이용하라고 하지만,
모든 불변 클래스가 저렇게 캐시 객체를 리턴하게끔 만들어진것도 아니고,
정적 팩토리 메서드를 이용한 방법도 내부적으로는 new 키워드를 이용하여 리턴하기 때문에 이 부분은 자바의 모호성에 한 몫을 하는 거 같다..
String.matches 보다는 Pattern 을 compile 해서 사용하는것을 권장하지만,
가독성을 위해서라면 어느정도 포기가 가능한 부분이라고 생각한다.(엄청난 성능 차이가 아니기 때문에)
극단적인 예를들어 레거시 코드가 추상화라고는 찾아볼수 없을만큼 방대한 라인수를 가지고 있다면
오히려 객체화 시켜 작업자들을 혼란시키는거보다 그냥 내버려두고 모르는척 하는게 그 수준의 동료들을 위한 방법은 아닐까 생각한다.
1.1마이크로초 > 0.17마이크로초로 상대적으로는 많이 개선됐지만 톰캣의 tps가 1000tps 임을 생각해보면 그리 대단한 성능차이는 아니기 때문에
마지막 Long 연산에 대한 코드는 정말 중요한 부분인데, wrapper class가 불변이기 때문에 겪을수 있는 실수를 극단적으로 표현한 케이스라 생각한다.
해당 케이스는 이해하기 쉽게 Long 타입을 예를들어 설명하였지만 자바가 기본 제공하는 자료형에도 이런 부분이 숨어있는 만큼,
우리가 사용하는 라이브러리 이곳저곳에 산재해 있을 가능성이 높으므로 잘 알고 사용하는 것이 좋다 라는 메시지로 보임.
그런데, 애초에 기본 자료형이 객체여야할 이유가 있나? 라는 생각이 듬.
java 는 객체지향 언어로 모든게 객체로 표현해서 처리해야한다는것은 알겠는데 굳이 숫자까지 객체로 표현을 했어야 했는지?
