Apache Kafka
Apache Kafka is an open-source
distributedevent streaming platform
Kafka : 오픈 소스 분산 이벤트 스트리밍 플랫폼
event
An event records the fact that "something happened" in the world or in your business
서비스에서 어떤 일이 발생하였다는 사실을 의미
event streaming
event streaming is the practice of capturing data in real-time from event sources.
이벤트 소스에서 발생하는 데이터를 실시간으로 캡처하는 것 ( 이벤트 소스 : DB, Application … )
즉, 이벤트가 발생하는 즉시 흐름( stream ) 으로 만들어 흘려보내고, 누군가가 그걸 실시간으로 처리/소비하는 과정
이를 통해 단순히 데이터를 전달하는 것이 아니라 데이터를 분석하고 처리하는 구조를 제공하고, 실시간으로 데이터를 수집하고 처리하는 데이터의 흐름을 보장합니다.
Kafka의 event streaming platform
Kafka는 다음 3가지의 핵심 원리로 event streaming platform을 구성합니다.
-
event stream을 pub/sub
-
원하는 시간만큼 event stream을 안전하게 저정합니다.
-
event stream을 실시간으로 처리할 수 있으며, 과거의 event stream 또한 처리할 수 있습니다 ( 재처리 기능 )
즉, Kafka는 연속적으로 발생하는 이벤트를 수집하여 저장하고 전달하는 중앙 스트림 플랫폼
Apache Kafka의 구조
Kafka is a distributed system consisting of servers and clients that communicate via a high-performance TCP network protocol
Kafka는 높은 성능의 TCP 프로토콜로 통신하는 여러 서버, 클라이언트로 구성된 분산 시스템입니다.
Kafka의 Server & Client 구조
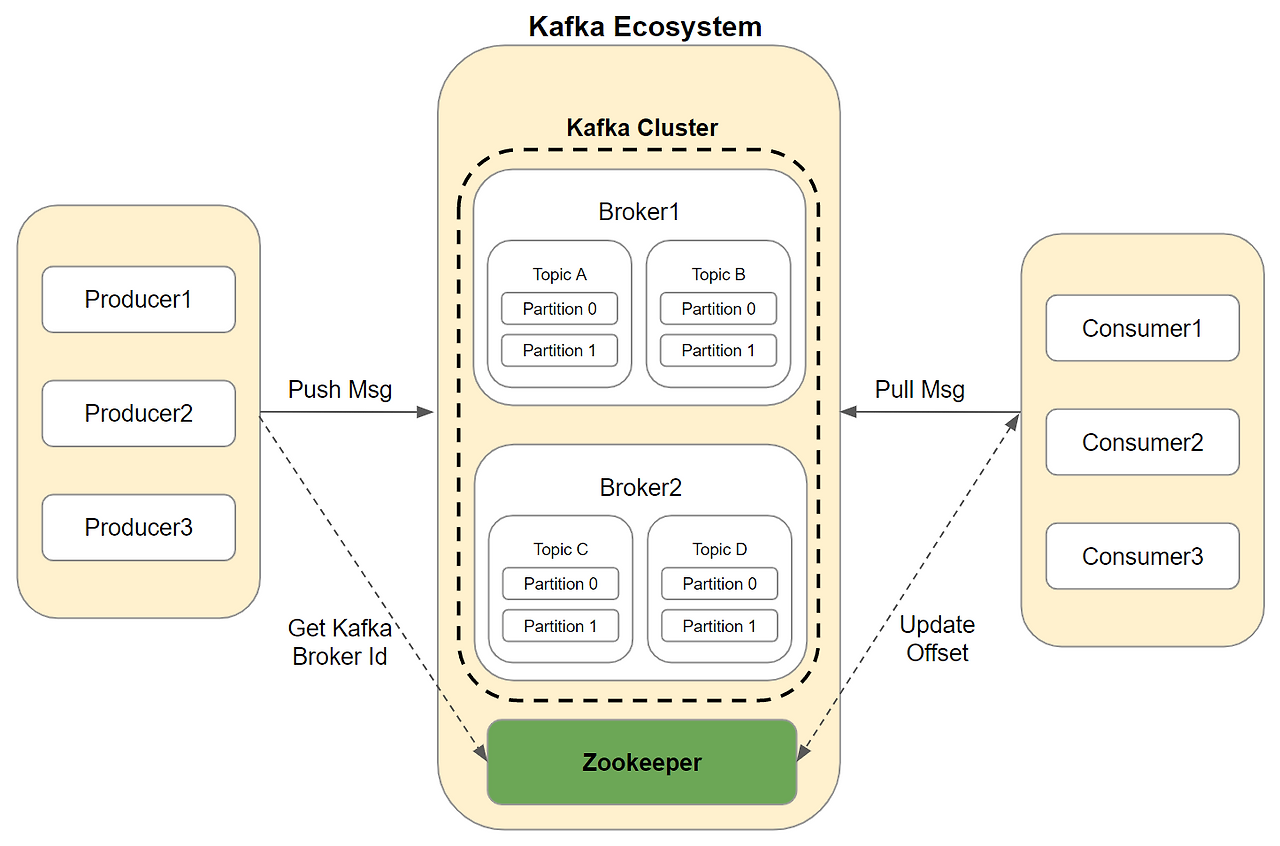
[ Kafka의 Server ]
Kafka is run as a cluster of one or more servers that can span multiple datacenters or cloud
Kafka는 확장 가능한 하나 이상의 서버로 이루어진 Cluster 형태로 동작합니다. ( Cluster 내부의 서버 : Broker )
Broker
Kafka 클러스터를 구성하는 서버로서, 하나의 Kafka는 Broker 1대 이상으로 구성되고, Producer가 보낸 메시지를 저장하거나 Consumer에게 필요한 파티션의 메시지를 찾아 스트리밍 방식 메시지를 전달하며 토픽과 파티션을 관리합니다.
Kafka Cluster는 여러 Broker로 구성되어 높은 확장성을 갖추기 때문에, 특정 Broker 서버에 장애가 발생하더라도 다른 Broker 서버가 작업을 이어받아 데이터 손실 없이 정상적으로 작업을 처리할 수 있습니다.
또한, Broker들은 서로 메시지를 복제해 장애 시에도 데이터가 유지되도록 합니다.
Kafka Cluster의 여러 Broker들은 파티션별로 Leader와 Follower의 역할을 가집니다.
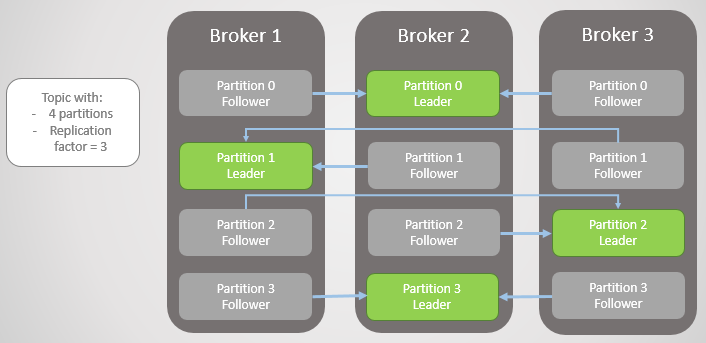
각 파티션에서 메세지를 읽고 쓰는 Broker는 단 1대이고, 이를 Leader Broker라고 칭하며, Leader Broker가 아닌 Broker들은 해당 Partition의 Follower Broker라고 부릅니다.
Follower Broker는 특정 Partition의 Leader Broker에 장애가 발생했을 때 빠르게 Leader로 승격되는 구조를 만들어 고가용성을 보장할 수 있습니다.
( 모든 Follower Broker들은 각 파티션의 Leader Broker로부터 지속적으로 새로운 메시지를 확인하여 갱신합니다. )
[ Kafka의 Client ]
Kafka Cluster는 Kafka Clinet와 상호작용하면서 event stream를 pub/sub 할 수 있게 하고, 이를 통해 분산 애플리케이션이나 마이크로서비스에서 이벤트 기반의 데이터 처리 및 가공을 할 수 있습니다.
Kafka Producer & Consumer
Producers are those client applications that publish (write) events to Kafka and consumers are those that subscribe to (read and process) these events.
Producer와 Consumer는 모두 Kafka의 Client Application으로서, Producer는 event를 publish ( write )하는 역할을 하고, Consumer는 event를 subscribe ( read )하는 역할을 합니다.
Producer는 누가 소비하였는지, Consumer는 누가 보냈는지를 알 필요가 없으므로, Kafka Broker가 중간에서 Producer와 Consumer를 완전히 분리하여 서로 의존하지 않도록 합니다.
또한, Producer는 Kafka가 중간 저장소 역할을 해주기 때문에 Consumer의 상태와 상관 없이 publish 할 수 있습니다.
즉, Producer는 Kafka에만 보내면 되고, Consumer는 나중에라도 Kafka에서 꺼내 가면 됩니다.
Kafka Topic & Partition
Topic
Events are organized and durably stored in topics
event는 Topic 내에 저장되며, Topic은 여러 Producer와 Consumer를 가질 수 있습니다.
( 정확히는 Topic 내의 특정 파티션에 저장됩니다. )
Kafka는 Topic 내의 이벤트를 소비해도 삭제되지 않기 때문에, 사용자가 같은 이벤트를 여러 번 다시 읽을 수 있습니다.
( event의 저장 유지 기간을 설정하여, 설정한 기간만큼 event를 보관할 수 있습니다. )
Producer가 보낸 이벤트는 Topic ( 파티션 )에 로그 형태로 저장합니다.
Partition
Topics are partitioned, meaning a topic is spread over a number of
Topic은 파티셔닝 되어 여러 파티션으로 구성되며, 각 파티션에 특정 Broker가 할당됩니다.
즉, 파티션 1개당 1개의 Kafka Leader Broker가 할당되기 때문에 같은 Topic이라도 다른 Partition이라면 서로 다른 Kafka Leader Broker에서 관리될 수 있습니다.
⭐️⭐️
Topic은 Cluster 단위의 논리적인 개념일 뿐 물리적인 저장 위치가 있는 것이 아니며, 특정 Topic은 특정 브로커에 종속되지 않고, 특정 Topic의 각 파티션은 각각 다른 브로커에 물리적으로 위치할 수 있습니다.
Topic: orders , Partition: 3개
| Partition | Leader Broker | Follower Brokers |
|---|---|---|
| orders-0 | Broker 1 | Broker 2 |
| orders-1 | Broker 3 | Broker 1 |
| orders-2 | Broker 2 | Broker 3 |
[ 왜 Topic을 여러 개의 파티션으로 나눌까 ]
Kafka로 publish 되는 event를 특정 Topic에 저장할 때, 이 Topic을 파티셔닝 하여 여러 개의 파티션에 분산하여 저장하는 이유는 데이터 분산 적재가 확장성에 매우 중요하기 때문입니다.
Topic 내에 여러 파티션이 존재하고, 각 파티션별로 다른 Broker가 할당될 수 있으므로, 이를 통해 Client Application은 Topic 내의 하나의 event를 사용하고자 할 때, 하나의 Broker에 집중되지 않고 여러 Broker를 사용하여 여러 데이터를 읽고 쓸 수 있습니다.
이를 통해 하나의 Broker에 부하가 분산되는 것을 완화하며, 데이터를 분산 저장, 처리하고 높은 확장성을 가집니다.
특정 Topic에 파티션이 여러 개 존재할 때, 각 파티션에 event는 기본적으로 라운드 로빈 방식으로 저장됩니다.
[ Kafka Consumer 동작 ]
Kafka Consumer는 Leader Broker에게 어디서부터 데이터를 읽을지에 대한 offset 값과 함께 fetch 요청을 보내 해당 offset부터 데이터 최신 데이터까지 순차적으로 읽습니다.
이렇게 offset을 직접 지정하기 때문에, 재처리가 매우 쉬우며, 각 Consumer는 자신이 어디까지 읽었는지( offset )를 별도로 저장하므로 서로 영향을 받지 않습니다.
Consumer는 Broker가 메세지를 push 해주는 시스템이 아니라 Consumer가 필요할 때 가져오는 pull 구조입니다.
즉, Consumer가 요청을 보내어 능동적으로 데이터를 가져오는 구조
pull 방식에서는 Consumer의 처리 속도에 맞게 메시지를 가져올 수 있어 과부하가 적은 장점이 있지만, Broker에 메시지가 없는 경우에도 메시지가 생성될 때까지 Polling 한다는 단점이 있습니다.
[ consume 된 메세지 추적 ]
대부분의 메세징 시스템은 Broker에서 어떤 메시지가 소비되었는지에 대한 메타데이터를 보관하고, 소비한 메세지의 메타 데이터를 삭제하는데, 이는 Consumer가 Broker에 소비 알림을 보내지 못한 경우 재소비 되거나 Broker에서 메시지를 삭제되지 않는 문제가 발생할 수 있습니다.
하지만, Kafka는 Broker가 아닌 Consumer가 소비한 메세지의 offset을 관리하고 Topic 내의 여러 파티션은 각각 1개의 Consumer에 의해 메시지가 소비되기 때문에 추적할 수 있습니다.
offset은 정수에 불과하기 때문에 데이터 크기가 작고, 따라서 주기적으로 저장해도 성능에 무리가 없습니다.
[ event consume 순서 불일치 문제 ]
하나의 토픽에 3개의 파티션이 존재한다고 할 때, 이벤트 들이 들어오면 여러 파티션에 분산되어 저장되고 여러 consumer가 이벤트가 들어온 순서에 맞지 않게 consume 하는 문제가 발생할 수 있습니다.
예를 들어, 주문 완료 이벤트가 들어온 후 주문 취소 이벤트가 들어왔을 때, 반대 순서로 consume 된다면 심각한 문제를 초래할 수 있습니다.
위 문제를 해결하는 방법 : event key를 설정
기본적으로 각 파티션은 항상 같은 consumer에 의해서만 consume 되고, 같은 event key를 설정한다면 항상 같은 파티션에 저장되므로 이벤트 consume 순서가 꼬이는 문제를 해결할 수 있습니다.
Kafka의 장애 내성과 고가용성 확보
Kafka는 장애 내성과 고가용성을 보장하기 위해 토픽의 각 파티션은 여러 브로커에 복제합니다. ( Replication )
예를 들어, Replication Factor = 3 이라면
| Partition | 역할 | Broker |
|---|---|---|
| topicA-0 | Leader | Broker 1 |
| topicA-0 | Follower | Broker 2 |
| topicA-0 | Follower | Broker 3 |
하나의 파티션을 여러 브로커에 복사본 형태로 저장합니다.
Leader Broker가 기본적으로 읽기와 쓰기 작업을 처리하며, Follower들은 Leader의 데이터를 복제합니다.
Leader Broker에 장애가 발생하면 자동 FailOver가 발생하여 이를 감지하고, Follower 중 하나를 새로운 Leader로 승격하여 서비스를 계속 유지할 수 있습니다.
Kafka의 성능
Kafka는 message를 저장하고, 캐싱할 때 filesystem을 사용합니다.
즉, Kafka는 데이터를 OS의 filesystem을 사용하여 디스크에 로그 파일 형태로 저장하고 관리합니다.
filesystem : 운영체제가 디스크를 관리하는 시스템 ( 데이터를 디스크에 저장하고, 읽고, 삭제하는 역할 )
( 파일과 디렉토리를 생성하여 데이터를 저장하고 관리 )
일반적인 디스크의 문제점
디스크에서 특정 데이터를 탐색할 때 발생하는 랜덤 I/O는 매우 느리므로, OS는 메모리의 여분을 디스크 캐시로 활용하여 성능을 보완합니다.
즉, 자주 접근하는 파일을 OS가 메모리에 저장하여 디스크 접근을 최소화합니다.
Kafka가 인메모리 캐시를 사용하지 않는 이유
Kafka는 JVM 기반으로 동작합니다.
-
객체 메모리 오버헤드 증가
JVM 내부에서 인메모리 캐시를 사용하면 JVM 객체는 객체 헤더 등으로 인해 실제 데이터보다 더 많은 메모리를 사용하기 떄문에 대량의 메세지를 객체로 만들어 캐싱하면 비효율적입니다.
-
GC 부담 증가
캐시에 데이터를 많이 생성할수록 JVM 힙이 커지고, 이에 따라 GC 시간이 길어지며 지연이 발생할 수도 있게됩니다.
따라서, Kafka는 JVM 내부에 캐시를 하지 않고, 모든 데이터를 파일 시스템에 로그 파일 형태로 기록합니다.
이렇게 하면, OS는 해당 파일을 페이지 캐시로 메모리에 올려두게 되어 캐시가 OS 메모리 영역에 있으므로 Kafka의 JVM 힙 크기는 작게 유지되어 GC 부담도 없고 메모리를 OS가 관리하므로 메모리 효율이 증가하며, OS 페이지 캐시는 Kafka가 재시작하더라도 유지되므로 성능이 유지됩니다.
즉, Kafka는 로그를 디스크에 순차적으로 기록하고, 이를 OS가 알아서 캐싱하는 구조를 가짐으로써 높은 처리량을 갖게 됩니다.
OS 페이지 캐시 : 운영체제가 디스크 파일을 메모리에 올려두어 빠르게 접근할 수 있게 해주는 기능
이러한 파일의 쓰기 작업은 대부분 페이지 캐시에서 먼저 이루어지고, 디스크에는 나중에 반영되므로 항상 최신 데이터를 읽습니다
Kafka의 read/write 성능
시간이 오래 걸리는 랜덤 I/O를 사용하지 않고, 순차 I/O 기반으로 처리합니다.
일반적인 메세지 큐 시스템은 메타데이터를 유지하기 때문에 B-Tree를 사용하므로 디스크에서 랜덤 탐색을 할 때 매우 느립니다.
하지만, Kafka는 메세지를 단순히 로그 파일 끝에 붙이기만 하는 순차 쓰기를 사용하고, 메세지 ID 대신 오프셋을 사용하므로 파일 크기와 상관 없이 특정 위치를 O(1) 시간 복잡도로 찾을 수 있습니다.
이를 통해 Kafka는 다른 메세지 큐 시스템과 달리 데이터가 쌓일수록 느려지는 것이 아니라 파일의 크기와 상관 없이 쓰기 읽기가 O(1) 속도를 가집니다.
또한, 이렇듯 빠른 속도를 가지기에 재처리하기에도 용이합니다.
[ Index vs offset ]
Index : 데이터를 빨리 찾기 위한 별도의 검색용 구조
Offset : Kafka 로그 파일에서 메시지가 위치한 파일 내부의 절대적인 실제 위치
Kafka 메세지 전달 방식
At most once - Messages may be lost but are never redelivered
At least once - Messages are never lost but may be redelivered
Exactly once - this is what people actually want, each message is delivered once and only once
At most once : 메시지는 유실될 수 있지만, 절대 다시 전달되지 않습니다.
At least once : 메시지는 절대 유실되지 않지만 다시 전달될 수 있습니다.
Exactly once : 메시지는 정확히 1번만 전달됩니다.
Kafka에서 메세지는 디스크의 로그 파일에 저장된 후, follower 레플리카까지 복제가 완료될 때 commit이 이루어집니다.
Kafka에서 메세지가 commit 되기 위해서는 ISR( In-Sync Replica ) 원칙을 따르며, 이는 모든 replica에 기록되어 확정적으로 영속된 데이터를 의미합니다.
메세지가 commit 된 이후에는 활성 상태의 복제본이 최소 1대의 Broker에 존재하는 한 데이터가 유실되지 않습니다.
Consumer는 committed 된 메시지만 읽을 수 있습니다.
이전에는 Producer가 메시지 커밋 응답을 받지 못한다면 메시지를 재전송할 수밖에 없었지만 ( At least once ), 멱등 전달을 통해 메세지가 중복으로 커밋되지 않게 하며 ( Exactly once ), Producer가 여러 토픽 파티션에 메세지를 전송할 때, 해당 메시지들을 트랜잭션처럼 묶어서 원자성을 보장하므로 Exactly once 의미를 가집니다.
즉, Kafka는 기본적으로 At least once로 재전송될 수 있지만, 멱등 처리와 트랜잭션 기능을 통해 Exactly once 방식으로 동작할 수 있습니다.
Kafka의 Replication
Kafka는 각 토픽 파티션들의 로그를 여러 Broker에 복제합니다.
이를 통해 특정 Broker에 장애가 발생하더라도 복제본을 통해 정상적인 서비스가 가능합니다.
각 파티션별로 1개의 Leader Broker와 나머지 Follower Broker 존재합니다.
⇒ Produce/Consume의 Write/Read 작업은 모두 Leader Broker에서 처리하며, 갱신되면 Follower에 적용됩니다.
Kafka의 Log 저장
-
Infinite Retension
영구적으로 모든 업데이트 로그를 저장하고 삭제하지 않습니다.
이 경우에 사용하지 않는 데이터들도 모두 저장되므로 저장 공간 문제가 생기고 실용적이지 않습니다.
-
Simple Retension ( 일정 기간만 저장 )
기간을 설정하여 로그를 저장하고 기간이 지나면 해당 로그를 삭제합니다.
Kafka는 들어온 메세지를 끝에 계속 붙여 넣는 방식인 Append-Only 구조를 사용하며, 기존 메시지를 수정하거나 덮어쓰지 않고, 새로운 메시지는 항상 새로운 레코드로 추가됩니다.
또한 simple retension 방식을 통해 메시지가 저장된 시간을 기준으로 retention 기간이 지나면 삭제합니다.
즉, Append-Only 구조 + simple retension 방식
Kafka Connect
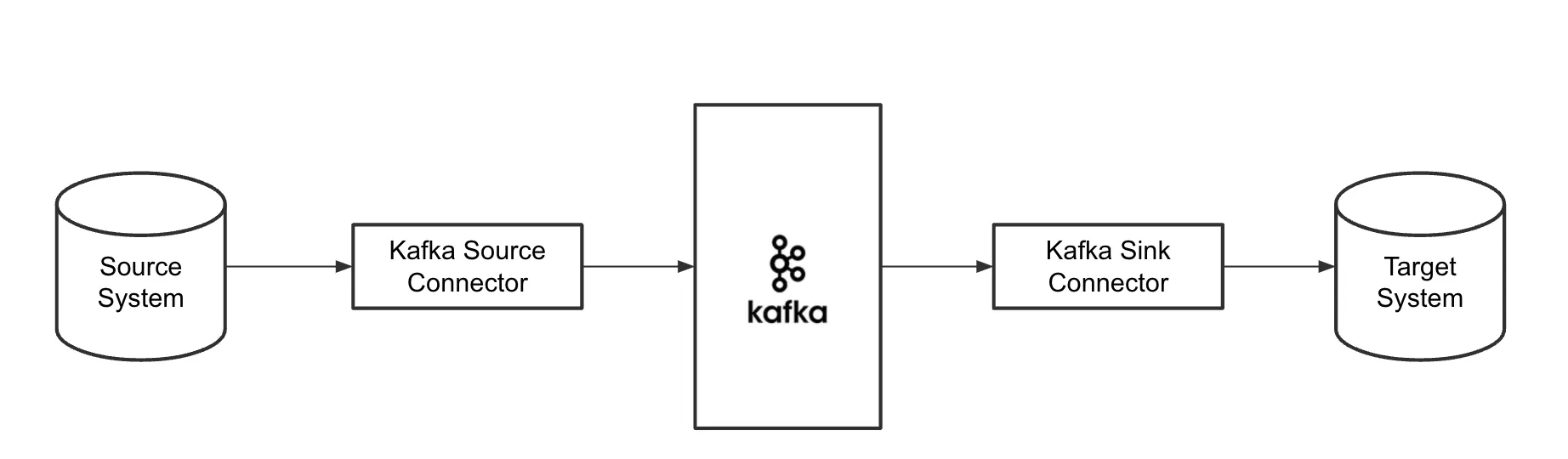
Kafka Connect는 Kafka Connector를 실행하는 프레임워크이자, 외부 시스템과 Kafka를 연결해주는 플랫폼
Kafka Cluster의 일부가 아니며, Kafka 외부에서 실행되는 독립적인 서비스입니다.
Kafka Connect의 구성 요소
-
Worker : Connector를 실행하고 관리하는 프로세스 ( Kafka Connect를 실제로 실행하는 서버 프로세스 )
-
Source Connector : 외부 시스템( DB 등 )에서 데이터를 읽어와 Kafka 토픽으로 Publish 합니다. ex ) Debezium
-
Sink Connector : Kafka 토픽에서 데이터를 구독하여 외부 시스템으로 Consume 합니다.
Kafka Connector
Kafka Connect에서 실제로 데이터를 가져오거나 보내는 동작을 수행하는 플러그인 ( 구현체 )
즉, 데이터를 어디서 가져오고 어디로 보낼지를 정의한 도구
CDC ( Change Data Capture )
데이터 소스에서 발생하는 변경 사항을 감지하고, 이벤트로 변환하여 다른 시스템으로 이벤트 스트림 형태로 전달하는 기술
이를 통해 데이터베이스의 변경 내용을 실시간으로 수신할 수 있으며, 이 데이터를 후속 처리 할 때 사용할 수 있습니다.
카프카 CDC
데이터베이스에서 변경 사항을 실시간으로 감지하여 Kafka 토픽에 이벤트 스트림 형태로 전달하는 방식
Kafka가 기본적으로 CDC 기능을 내장하지는 않고, Kafka + Kafka Connect + 특정 Connector로 구성하여 동작
카프카 CDC의 유형
[ Kafka CDC 쿼리 기반 ]
조건자를 포함하는 데이터베이스 쿼리를 사용하여 변경된 현재 데이터를 추출하는 방식
조건자는 소스에서 발생한 변경 사항을 식별하는데 도움이 되며, 증분 변경이 발생할 타임스탬프 또는 식별자 열을 기반
쿼리 기반 Kafka CDC는 Kafka Connect용 JDBC 커넥터를 통해 활성화됩니다.
[ Kafka CDC 로그 기반 ]
데이터베이스의 트랜잭션 로그를 사용하여 소스에서 발생하는 모든 변경 사항에 대한 세부 정보를 가져옵니다.
( 트랜잭션 로그는 모든 삽입, 삭제 및 업데이트를 기록 )
예를 들어, 두 개의 변경된 행이 데이터베이스에 커밋되면 트랜잭션 로그에 두 개의 항목이 생성되고, 이 항목들은 디코딩되고 두 개의 새로운 Kafka 이벤트를 생성됩니다.
로그 기반 Kafka CDC의 장점 : 행의 최신 데이터뿐만 아니라 변경 전 행의 상태도 기록하므로 과거 데이터를 사용할 수 있다는 것
Debezium
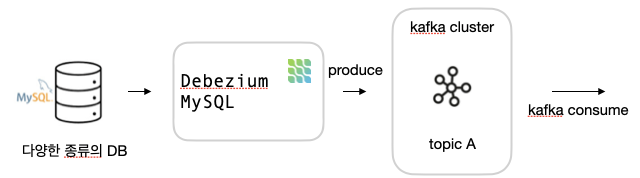
Debezium is a set of distributed services to capture changes in your databases so that your applications can see those changes and respond to them
애플리케이션에서 DB의 데이터 변경을 알 수 있도록 DB의 변경을 캡쳐하는 분산 서비스 ( CDC 라이브러리 )
Debezium은 Apache Kafka 기반으로 구축되어 DBMS별로 Kafka Connector와 호환되는 Connector들을 제공합니다.
해당 Connector가 DB의 변경 사항을 기록하고 감지하여 해당 데이터를 Kafka Topic으로 Event Streaming 합니다.
Debezium Connector의 동작 방식 - MySQL 기준
프로젝트에서 MySQL을 사용하였기에 MySQL Debezium Connector의 동작 방식을 살펴보겠습니다.
MySQL Debezium Connector는 MySQL 바이너리 로그를 기반으로 동작합니다.
설정한 특정 테이블에 대해 INSERT / UPDATE / DELETE 가 발생하면 MySQL은 이 변경사항을 binlog에 기록하고, Debezium MySQL Connector는 binlog를 읽어 이벤트로 변환하여 CDC 이벤트를 생성합니다.
Connector가 맨 처음 기동되면 기존 테이블 데이터를 한 번 스냅샷으로 읽어서 Kafka로 전송하고 binlog를 tailing하여 실시간 으로 변경 사항을 감지하여 Debezium 이벤트로 변환해 Kafka로 publish 합니다.
Debezium이 생성하는 이벤트는 변경 전, 후 데이터, 작업의 종류, 이벤트 발생 시각 등을 포함합니다.
Debezium의 재처리
Debezium → Kafka 전송 실패 시 Kafka Producer가 일정 시간동안 재시도를 수행합니다.
Debezium은 Kafka에 성공적으로 publish된 경우에만 offset을 기록하며, Debezium 재시작하면 offset이 기록된 지점부터 다시 binlog를 읽고 실패한 이벤트는 다시 produce됩니다.
이를 통해 Debezium의 CDC 모델은 at-least once 방식의 최소 1번 이상은 데이터가 전송되는 것을 보장합니다.
로그 기반 CDC를 활용하는 Debezium의 특징
-
Debezium은 데이터베이스 로그를 읽기 때문에 모든 데이터의 변경 사항을 추적할 수 있습니다.
-
Debezium이 다운되더라도 데이터베이스의 로그가 사라지지 않기 때문에 안전합니다.
-
Polling 기반 방식은 정해진 간격마다 DB를 직접 조회하여 변경 여부를 확인하기 때문에 변경을 빠르게 감지하려면 Polling interval을 줄여야 하고, 이로 인해 DB 부하 및 애플리케이션 CPU 사용량이 증가합니다.
반면, Debezium은 데이터베이스의 트랜잭션 로그( binlog )를 직접 읽는 로그 기반 CDC 방식을 사용하기 때문에 로그는 DB 내부에서 이미 생성되는 정보이므로 별도 조회 부담이 없고,변경이 아무리 빠르게 발생하더라도 CPU 부하는 거의 증가하지 않고 실시간 추적이 가능합니다.
-
Polling 방식은 현재 스냅샷만 비교하는 구조이기 때문에 삭제된 데이터를 직접적으로 감지하기 어렵습니다.
하지만, Debezium은 DB 로그에서 삭제된 이벤트도 읽기 때문에 삭제된 레코드의 키나 변경 시점 등도 정확히 이벤트로 전달할 수 있습니다.
Transactional Outbox Pattern
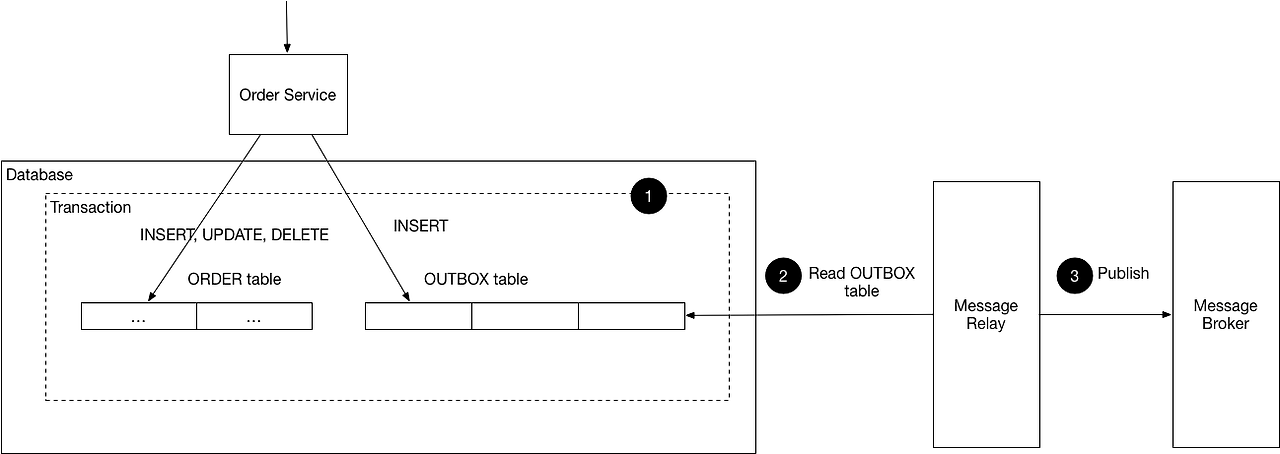
Transactional Outbox 패턴은 비즈니스 테이블의 변경 작업과, 그 변경 내용을 기록하는 Outbox 테이블에 이벤트를 저장하는 작업을 하나의 트랜잭션으로 처리하여, DB 변경과 이벤트 생성이 원자적으로 일어나도록 보장하는 패턴입니다.
애플애케이션은 DB에 데이터를 변경할 때, 동시에 별도로 만든 Outbox 테이블에 이벤트 기록을 함께 저장하며, 이 두 작업은 같은 데이터베이스 트랜잭션 안에서 실행되므로 정합성이 보장됩니다.
( 한 트랜잭션 안에서 변경되는 모든 테이블과 Outbox 테이블을 함께 묶습니다. )
서비스에서는 일반적으로 비즈니스 로직 수행 과정에서 DB에 데이터를 삽입·수정·삭제하고, 그 결과를 외부 시스템으로 메시지로 전송하는 작업을 함께 처리합니다.
메시징 시스템 기반 아키텍처에서는 이러한 동작이 매우 흔하지만, DB 업데이트와 메시지 전송이 서로 다른 시스템에서 수행되기 때문에 두 작업을 원자적으로 보장하지 않으면 정합성 문제가 발생할 수 있습니다.
예를 들어, DB 업데이트는 성공했지만 메시지 전송이 실패하면, 해당 이벤트는 외부 시스템에 전달되지 않아 데이터 불일치나 메시지 유실로 이어질 수 있으며, 이는 시스템 전체에 심각한 오류를 초래할 수 있습니다.
이러한 문제를 해결하기 위해 등장한 것이 Transactional Outbox Pattern입니다. 이 패턴은 DB 업데이트와 이벤트 기록( Outbox 저장 )을 하나의 트랜잭션으로 묶어 처리함으로써, 메시지 전송과 관련된 정합성을 보완하고 안전한 이벤트 발행 기반을 제공합니다.
Transactional Outbox Pattern
DB 업데이트와 message 전송을 원자적으로 수행하기 위한 방법
-
이벤트 내용을 저장하는 전용 테이블인 Outbox Table 생성
-
이벤트 정보를 Outbox 테이블에 한 행으로 기록합니다.
-
DB Update와 Outbox Insert를 1개의 DB 트랜잭션으로 묶어서 수행합니다.
ex )
orders테이블 UPDATE →outbox테이블 INSERT 하여 이 두 작업을 단일 DB 트랜잭션으로 묶어 수행합니다.트랜잭션이 성공하면 두 작업이 모두 반영되고, 실패하면 둘 다 롤백됩니다.
즉, Transactional Outbox Pattern은 비즈니스 데이터 변경과 이벤트 기록( Outbox 저장 )을 동일한 DB 트랜잭션에서 처리함으로써, DB 업데이트와 전송해야 할 이벤트의 정보에 대한 정합성을 보장합니다.
이벤트 전달에 실패할 경우 Outbox 테이블을 통해 재시도를 가능하게 합니다.
왜 Outbox 테이블을 따로 둘까
비즈니스 테이블과 이벤트 발행 행위를 분리하기 위함입니다.
만약 비즈니스 테이블에 이벤트 발행 로직을 섞으면 비즈니스 테이블에 이벤트 정보인 event flag, event payload 등을 추가해야 하기에 스키마가 오염되고, 유지보수성이 떨어지게 되므로 비즈니스 테이블은 비즈니스 데이터만, Outbox 테이블은 이벤트를위한 저장소로 사용하기 위해 분리하는 것입니다.
Outbox 테이블에 포함해야 할 정보
-
event_id : 발행할 이벤트를 식별하기 위한 UUID 또는 PK
-
aggregate 관련 : 발생한 도메인 type과 id 저장, 어느 Aggregate인지, 어떤 리소스인지 식별하기 위해 사용
-
metadata : Kafka Message의 헤더에 담을 추가 정보( 메타데이터 )
-
payload : Kafka Message의 Payload( Value )에 담을 정보
-
created_at : 이벤트 발생 일시
Outbox 테이블은 하나만 두고 여러 테이블에서 발생한 이벤트를 모두 저장합니다.
어떤 테이블에서 발생한 이벤트인지를 어떻게 구분하기 위해 Outbox 테이블에 aggregate 관련 필드를 사용하여 이벤트가 어떤 비즈니스 테이블에서 나왔는지 식별합니다.
[ Debezium에서 특정 테이블의 이벤트를 식별하는 방법 ]
Debezium은 Outbox 테이블 전체를 읽고 필요한 이벤트만 필터링하는 방식을 사용합니다.
즉, Outbox 테이블 안에서 특정 이벤트만 읽도록 Debezium 레벨에서 필터링하는 것이 불가능 합니다.
Transactional Outbox Pattern의 장점
이렇게 Transactional Outbox Pattern을 사용한다면, Outbox 테이블이 메시지 전달 실패나 재시도가 필요한 이벤트를 담는 역할까지 수행하기 때문에, Kafka DLQ 같은 별도의 Dead-Letter Queue를 꼭 만들지 않아도 되며, DB Update와 메세지 발행( Outbox Insert )이 하나의 트랜잭션으로 묶이기 때문에 데이터 정합성 문제가 해결됩니다.
[ 일반적인 메시징 환경에서 Dead-Letter Queue는 필요할까 ]
메시지를 Kafka 같은 브로커에 보낼 때, 전송이 실패하거나 컨슈머가 처리를 실패하면 문제 있는 메시지를 따로 모아두는 공간이필요하며 이를 Dead-Letter Queue라고 합니다.
이를 통해, 메시징 시스템에서 실패한 메시지를 정상 메시지 흐름과 분리하여 안전하게 보관하고, 이후 재처리하거나 분석하여 실패 원인을 파악할 수도록 합니다.
Transactional Outbox Pattern에서 고려할 점
[ Outbox Table에 쌓이는 메세지를 처리할 방법 ]
-
쌓이는 메세지를 남겨놓기
-
발행 후 지우기
이벤트 유실 시 서비스에 큰 영향을 줄 수 있다면, 발행 직후 바로 삭제하지 말고 일정 기간 보관한 뒤 삭제하도록 설정하는 것이 더욱 안전할 것 같습니다.
[ Outbox Table에서 message를 읽는 방식 ]
-
Polling
Outbox Table를 주기적으로 Polling하여 메시지를 읽는 방식으로, Polling할 주기를 설정하여 Outbox Table의 발행되지 않은 메시지를 읽어서 발행합니다.
이때, Polling 시 발행되지 않은 메세지를 식별하기 위해서는 상태 값 필드를 추가하거나, 발행한 메세지를 삭제해야합니다.
이 방식은 구현이 간단하나, 주기적으로 접근하거나 변경 사항이 없음에도 DB에 접근하여 부하를 줄 수 있는 단점이 있습니다
-
Transaction Log Tailing
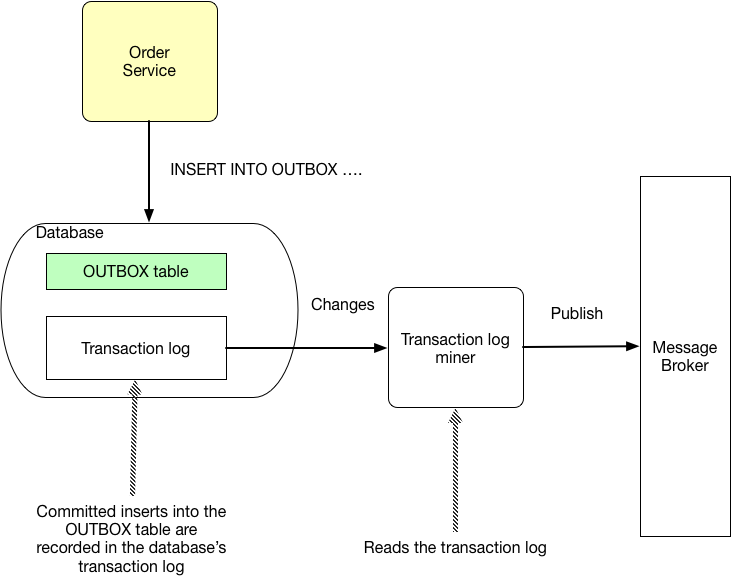
해당 방식은 Application 단에서 DB를 조회한 결과로 메시지를 Read하는 것이 아닌, DB단에서 생성되는 Transaction Log를 추적하고 데이터 변경을 감지하여 Read하는 CDC 방식입니다
일반적으로 CDC를 직접 구현하는 것은 힘들기 때문에 이를 구현한 Debezium과 같은 오픈 소스를 사용합니다.
Transactional Outbox Pattern과 MySQL Debezium Connector을 사용하는 구조
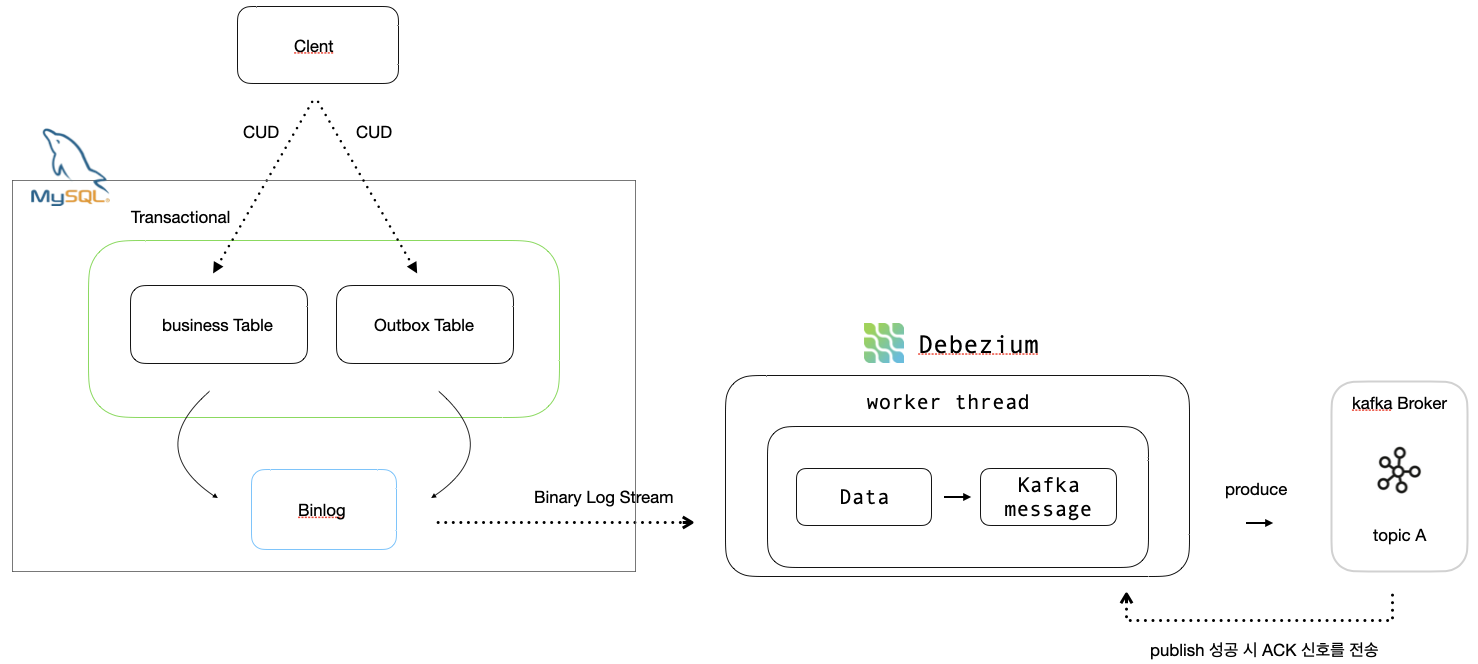
[ Transactional Outbox + Debezium 구조 ]
Transactional Outbox 패턴과 Debezium을 함께 사용하면, DB 변경과 이벤트 생성은 하나의 트랜잭션으로 원자성을 보장하고( Outbox ), Outbox 테이블의 이벤트를 메시지 브로커로 전달( Debezium )할 수 있기 때문에 DB 상태와 이벤트 전달 간의 정합성을 맞출 수 있습니다.
Outbox 테이블 변경을 binlog에서 감지하여 Kafka로 publish하고, publish 실패 시 Debezium이 자동으로 재시도하므로 이벤트 유실이 없습니다.
이를 통해 DB 상태와 Kafka 이벤트 스트림 사이의 정합성을 유지할 수 있습니다.
