문제 상황
JMeter로 대기열 요청에 대해 1초 동안 스파이크 테스트를 진행한 결과, 2000건 이상부터 오류가 급격히 발생했습니다.
현재 프로젝트는 Docker 컨테이너 환경에서 3개의 서버를 두고, Nginx를 통해 요청을 분산하고 있는데, 문제를 분석해보니 Nginx를 거치지 않고 서버에 직접 스파이크 테스트를 진행했을 때는 오류가 발생하지 않는 것을 확인했습니다.
이를 통해, Nginx에서의 TCP 연결 관리 과정( 3-way handshake와 4-way handshake 종료 과정 )에서 다량의 TIME_WAIT가 발생하고, 이로 인해 오류가 발생한다고 판단했습니다.
오류가 발생한 요청에서는 NoHttpResponseException이 발생했는데, 다음과 같은 원인 때문입니다.
- Nginx가 백엔드 서버의 응답을 받기 전에 연결이 끊어진 경우
- Nginx의 타임아웃 시간 내에 서버가 응답을 반환하지 못한 경우
- Nginx와 백엔드 서버 간 TIME_WAIT 상태가 누적되어 연결 자원이 부족해져 새로운 연결을 할 수 없는 경우
- …
3, 4-way-handshaking으로 인한 성능 저하
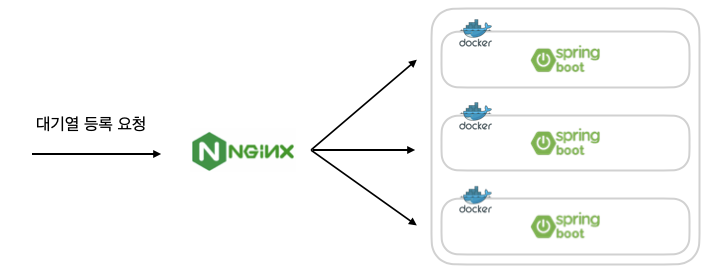
Nginx를 중간에 배치하여 로드 밸런싱을 적용할 경우, 성능 저하가 발생할 수 있습니다.
이는 클라이언트와 Nginx 간의 3-way handshake와 Nginx와 백엔드 서버 간의 3-way handshake가 각각 발생하여 총 두 번의 연결 과정이 필요하기 때문입니다.
또한 응답이 완료된 후에는 4-way handshake를 통한 연결 종료 과정도 두 번 발생하게 됩니다.
특히 대기열 요청과 같이 짧은 시간 동안 대량의 요청이 몰리는 스파이크 테스트 상황에서는 이러한 연결 과정이 네트워크 자원을 크게 소모하여 성능 저하가 발생할 수 있습니다.
추가적으로 빈번한 연결 종료로 인해 TIME_WAIT 상태의 소켓이 대량으로 발생하면, 제거되지 못한 소켓들이 로컬 포트를 점유하기 때문에 로컬 포트 고갈 현상이 발생할 수 있습니다.
로컬 포트가 고갈되면 새로운 TCP 연결을 맺을 수 없게 되기 때문에 결과적으로 새로운 요청이 거부되거나
NoHttpResponseException와 같은 오류가 발생할 수 있습니다.
해결 방안 ( keepalive 설정 추가 )
기존 nginx.conf 설정
events {}
http {
# Nginx 서버에서 받은 요청을 넘겨줄 서버를 정의하는 지시자 : upstream
upstream test_backend_cluster {
server test-queueing-back-1:8080;
server test-queueing-back-2:8080;
server test-queueing-back-3:8080;
}
server {
listen 90;
# 79포트로 요청이 오면 Nginx는 그 요청을 backend_cluster라는 이름의 서버 그룹으로 전달(proxy)
location / {
proxy_pass http://test_backend_cluster;
}
}
}keepalive 설정을 추가하자
events {}
http {
upstream test_backend_cluster {
server test-queueing-back-1:8080;
server test-queueing-back-2:8080;
server test-queueing-back-3:8080;
keepalive 100; // 각 대상마다 keepalive의 개수,
keepalive_timeout 30; // keepalive의 생존 시간 (sec)
}
server {
listen 90;
# 79포트로 요청이 오면 Nginx는 그 요청을 backend_cluster라는 이름의 서버 그룹으로 전달(proxy)
location / {
proxy_pass http://test_backend_cluster;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}
}Nginx upstream keepalive 풀 동작
keepalive [개수] : 워커 프로세스당 idle connection pool 크기 상한
⇒ 워커 프로세스마다 설정한 keepalive 개수 만큼의 커넥션을 풀에 저장할 수 있다는 뜻
워커 프로세스 : Nginx가 실제 요청을 처리하는 실행 단위
특정 워커 프로세스가 서버 1에 요청을 보낼 때, 그 워커의 풀에 서버 1과 이미 맺어진 idle connection이 있으면 그걸 꺼내 재사용하지만, idle connection이 없으면 새 연결 생성하고 이미 있는 연결이 사용 중이라면 추가 연결 생성 ( 풀에 있는 연결이 idle( 대기 중 ) 상태여야만 재사용 가능 )
⇒ 풀에 동일한 서버로 가는 연결이 여러 개 생길 수 있음
요청이 끝난 후 연결을 close 하지 않고 idle connection으로 풀에 되돌려 놓고, keepalive_timeout 동안 살아있다가 다음 요청에서 쓰이거나, 타임아웃이 지나면 close 됩니다.
HTTP는 연결을 맺고 데이터를 주고 받은 후 바로 연결을 끊어버리는 비연결성이라는 특징이 존재하는데, 이 때문에 실시간으로 클라이언트와 서버가 주고 받을 때 매번 3, 4-way handshaking 이 발생하는 문제가 있습니다.
Nginx의 Keepalive 설정을 해주면 불필요한 handshaking 과정을 줄일 수 있습니다.
keepalive : 클라이언트의 연결 요청을 처리한 후 바로 연결을 끊는것이 아니라, 일정 시간 대기하는 것
keepalive timeout 설정으로 대기시간을 지정해줄 수 있습니다.
keepalive를 설정해주면 클라이언트의 요청이 여러 번 있을때, 한번만 TCP 세션을 연결하고 Keepalive 시간동안 동일한 세션으로 데이터를 주고 받을 수 있게 됩니다.
현재 설정되어 있는 upstream 코드에서는 keepalive 설정이 없기 때문에 요청마다 nginx와 서버가 TCP 연결과 종료 과정을 거치기 때문에 불필요한 리소스 낭비와 응답속도 지연을 발생시킬 수 있습니다.
주의 사항
HTTP 버전은 1.1로 지정되어야하고, header는 빈 값으로 전달해야 합니다.
대기열 프로젝트에서의 keepalive 설정
keepalive는 서버와의 연결을 유지했다가 동일 서버 요청 시 재사용하는 방식입니다.
하지만, 대기열 시스템은 짧은 시간에 대량의 요청이 몰리는 구조이기 때문에 연결 재사용 가능성이 낮다고 판단해 설정하지 않았으며, 실제로 keepalive를 적용했을 때 응답 속도와 TPS 성능이 더 저하되는 것을 확인했습니다.
따라서 keepalive는 오히려 지속적인 요청이 이어지는 환경에서 더 적합하다고 판단했습니다
keepalive의 단점
Keepalive는 TCP 연결 재사용을 통해 성능을 향상시키지만, 다음과 같은 단점도 있습니다.
- 메모리 및 자원 소모 Nginx 프로세스들이 연결을 열어 둔 채로 대기하기 때문에, 연결된 클라이언트의 수만큼 메모리와 CPU 자원을 소모합니다. 특히 유휴 상태의 연결이 많을 경우, 서버의 자원 효율이 떨어질 수 있습니다.
- 연결 고갈 가능성 서버가 최대로 처리할 수 있는 연결 수는 제한적이기 때문에 유휴 상태의 Keep-Alive 연결이 너무 많아지면, 새로운 클라이언트가 접속을 시도할 때 연결을 맺지 못하는 상황이 발생할 수 있습니다.
따라서, keepalive_timeout을 설정하여 일정 시간 뒤 유후 상태인 connection을 자동으로 끊어 자원을 반환하도록 해야합니다.
워커 프로세스 설정
워커 프로세스
Nginx에서 실제로 네트워크 연결을 받아 처리하는 실행 단위로, Nginx는 보통 하나의 마스터 프로세스와 여러 개의 워커 프로세스로 구성되며, 클라이언트 요청의 대부분은 워커가 처리합니다.
동작 방식
- 마스터 프로세스 : 설정 파일 읽기, 워커 생성 및 종료, 그 외의 관리자 역할을 수행하며, 실제 요청 처리는 하지 않음
- 워커 프로세스 : 각 워커는 독립적인 프로세스이며 자체 이벤트 루프를 사용하여 수많은 요청을 동시에 처리합니다.
- 동시 연결 한계 : 워커 하나가 동시에 처리 가능한 연결 수는
worker_connections로 제한되고, 전체 동시 연결 수는worker_processes × worker_connections로 계산됩니다.
워커 프로세스 수와 요청 처리 수가 응답 속도에 미치는 영향
- 워커 수가 너무 적으면 특정 워커에 요청이 몰려 응답 지연이 발생합니다.
- 워커 수가 코어 수에 맞춰 적절하면 CPU 자원을 고르게 활용해 안정적인 응답 속도 유지합니다.
- 워커 수가 코어보다 많으면 컨텍스트 스위칭 오버헤드가 발생하여 응답 속도 저하될 수 있습니다.
따라서, CPU에 따라 적절히 워커 프로세스의 수와 worker_connections를 조정하는 것이 중요합니다.
Nginx 설정을 통한 최적화
docker container 안에서의 nginx 정보 조회
# nginx 버전 조회
$ nginx -v
# ps 명령을 사용해서 nginx의 상태 확인, ps 명령어가 없을 경우 apt-get 명령을 통해서 procps 를 설치
$ apt-get update
$ apt-get install -y procps
# nginx 상태 확인
$ ps -ef | grep nginx
---
# ps -ef | grep nginx
root 1 0 0 07:43 ? 00:00:00 nginx: master process nginx -g daemon off;
nginx 29 1 0 07:43 ? 00:00:00 nginx: worker process
root 231 39 0 07:44 pts/0 00:00:00 grep nginx
⇒ nginx에서 master 프로세스 1개, worker 프로세스 1개로 이루어진 것을 볼 수 있음1초에 2000건 이상의 요청이 발생했을 때 오류가 발생하여, 서버에 직접 요청을 보내 Nginx에 의한 문제 여부를 확인한 결과 실제로 Nginx 설정의 한계임을 확인했습니다.
확인 결과 워커 프로세스는 1개였고, 각 프로세스가 처리할 수 있는 요청 수도 기본값인 512로 설정되어 있었습니다. 이러한 설정은 짧은 시간에 대량의 요청이 발생하는 대기열 시스템 환경에서는 적절하지 않았습니다.
또한, keepalive는 동일 서버 요청 시 연결을 재사용하는 방식이지만, 대기열 시스템에서는 연결 재사용 가능성이 낮아 효과가 없었고, 실제 적용 시 응답 속도와 TPS 성능이 오히려 저하되었습니다.
따라서, keepalive는 단기간 대량의 트래픽보다는 지속적인 요청이 이어지는 환경에서 더 적합하다고 판단했습니다.
이에 따라 워커 프로세스 수와 요청 처리 수를 조정하는 방식으로만 문제를 개선했습니다
worker_processes auto; # 워커 프로세스의 수를 CPU 코어 개수만큼 할당
events {
worker_connections 1024; # 각 워커 프로세스 당 요청을 1024개 처리하도록 설정
}
http {
upstream test_backend_cluster {
server test-queueing-back-1:8080;
server test-queueing-back-2:8080;
server test-queueing-back-3:8080;
# keepalive 1000; # 각 대상마다 keepalive의 개수,
# keepalive_timeout 15; # keepalive의 생존 시간 (sec)
}
server {
listen 90;
# 79포트로 요청이 오면 Nginx는 그 요청을 backend_cluster라는 이름의 서버 그룹으로 전달(proxy)
location / {
proxy_pass http://test_backend_cluster;
# proxy_http_version 1.1;
# proxy_set_header Connection "";
}
}
}설정을 통해 워커 프로세스의 수를 auto 설정을 통해 CPU 코어 기준 10개로 조정하고, 각 워커 프로세스가 처리할 수 있는 최대 요청 수를 1024개로 설정하였습니다.
그 결과 목표치인 5000번의 요청을 1초에 보내는 테스트에서 오류율이 사라졌으며, 응답 속도가 약 20% 향상되고 TPS 또한 30% 개선되었습니다.
