[SpringBoot] - Spring Data JPA와 JPA

스프링부트는 JPA의 구현체 중에서 'Hibernate'라는 구현체를 이용한다.
Hibernate는 '오픈소스'로 ORM을 지원하는 프레임워크이다.
스프링부트로 프로젝트 생성 시에 추가한 'Spring Data JPA'는 Hibernate를 스프링부트에서 쉽게 사용할 수 있는 추가적인 API를 제공한다.
(스프링프레임워크 자체가 대부분의 다른 프레임워크와의 호환성을 위한 라이브러리를 제공한다.)
-
Spring Data JPA를 사용했을 때 다음과 같은 구성이 된다.
Spring Data JPA <--> Hibernate <--> JDBC <--> DB
엔티티 클래스와 JpaRepository
Spring Data JPA를 어떤 방식으로 사용하게 될까
Spring Data JPA가 개발에 필요한 것은 두 종류의 코드이다.
- JPA를 통해 관리하게 되는 객체(Entity Object)를 위한 엔티티 클래스
- 엔티티 객체들을 처리하는 기능을 가진 Repository
이 중 Repository는 Spring Data JPA에서 제공하는 인터페이스로 설계하는데 스프링 내부에서 자동으로 객체를 생성하고 실행하는 구조라 개발자 입장에서는 단순히 인터페이스를 정의하는 작업만으로 충분하다.
기존 Hibernate는 모든 코드를 구현하고 트랜잭션 처리가 필요했으나, Spring Data JPA는 자동으로 생성되는 코드를 이용하므로 단순 CRUD나 페이지 처리 등에 개발코드를 구현하지 않아도 된다.
엔티티 클래스 작성
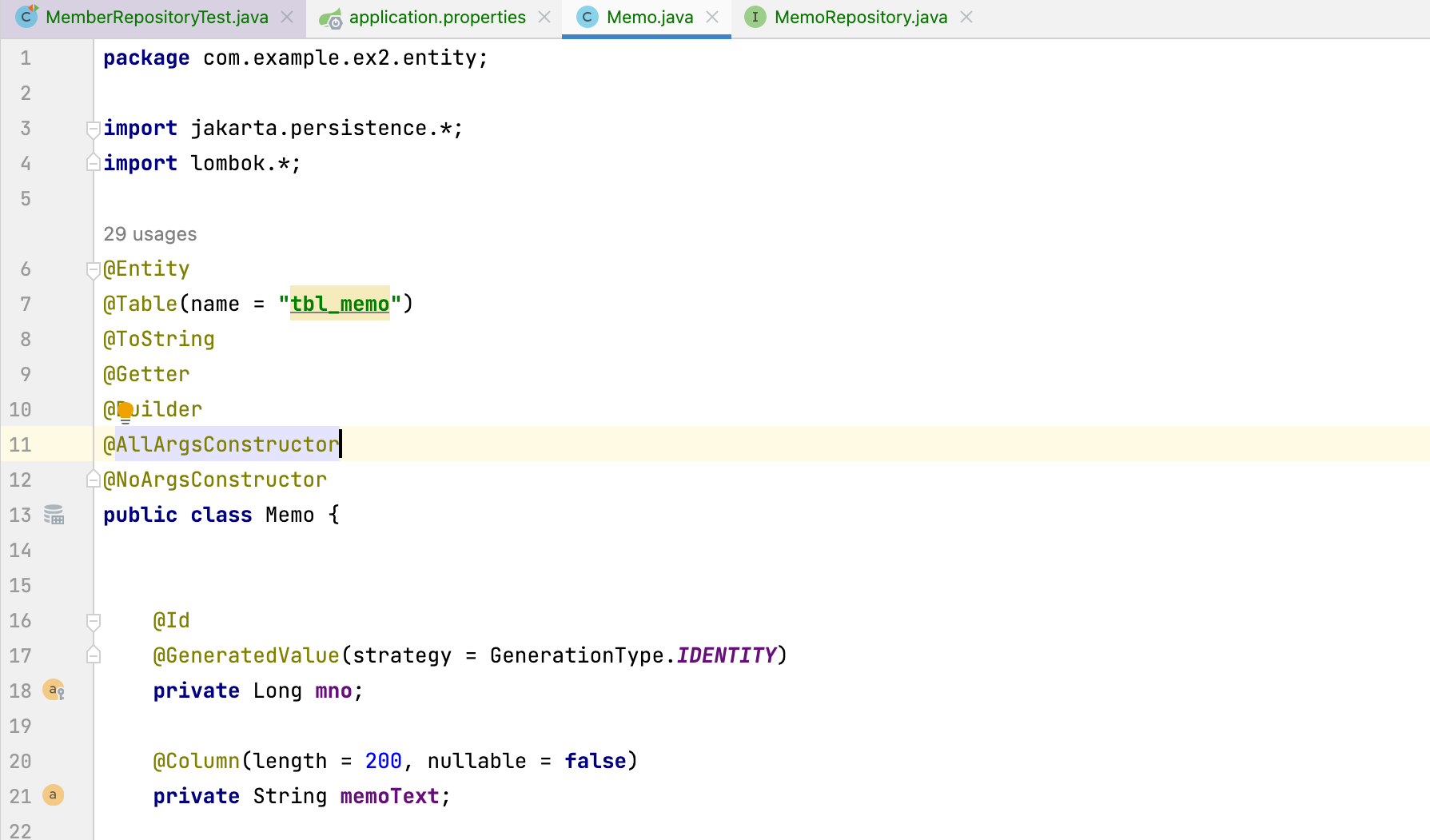
@Entity
- 엔티티 클래스는 Spring Data JPA에서는 반드시 @Entity라는 어노테이션을 추가해야 한다.
- 해당 클래스가 엔티티를 위한 클래스이며, 해당 클래스의 인스턴스들이 JPA로 관리되는 엔티티 객체임을 의미한다.
- 옵션에 따라서 자동으로 테이블 생성 가능하다.
- 클래스의 멤버 변수에 따라서 자동으로 칼럼도 생성된다.
@Table
- @Entity와 같이 사용할 수 있는 어노테이션이다.
- 데이터베이스 상에서 엔티티 클래스를 어떠한 테이블로 생성할 것인지에 대한 정보를 담기위한 어노테이션이다.
- 단순 테이블 이름뿐만 아니라 인덱스등을 생성하는 설정도 가능하다.
@Id와 @GeneratedValue
- @Entity가 붙은 클래스는 Primary Key(이하 PK)에 해당하는 특정 필드를 @Id로 지정해야 한다.
- @Id가 사용자가 입력한 값을 사용하는 게 아니라면 자동으로 생성되는 번호를 사용하기 위해서 @GeneratedValue라는 어노테이션을 사용한다.
- @GeneratedValue(strategy = GenerationType.IDENTITY) 부분은 PK를 자동으로 생성하고자 할 때 사용한다.(키생성전략)
키 생성 전략은 다음과 같다.
- AUTO(default) - JPA 구현체가 생성방식을 결정
- IDENTITY - 사용하는 DB가 키 생성을 결정, MySQL, MariaDB의 경우 auto increment 방식 이용, 오라클은 별도의 번호를 위한 별도의 테이블을 생성
- SEQUENCE - DB의 sequence를 이용해 키 생성, @SequenceGenerator와 같이 사용
- TABLE - 키 생성 전용 테이블을 생성해서 키 생성, @TableGenerator와 같이 사용
@Column
- 추가적인 필드(칼럼)이 필요한 경우에도 위 어노테이션을 사용한다.
- @Column을 이용해 다양한 속성을 지정한다.
- 주로 nullable, name, length 등을 이용해 DB의 칼럼에 필요한 정보를 제공한다.
- 속성 중에 columnDefinition을 이용해 기본값을 지정할 수 있다.
@Builder를 이용해서 객체를 생성할 수 있게 처리한다.
@Builder를 이용하기 위해서는 @AllArgsConstructor와 @NoArgsConstructor를 항상 같이 처리해야 컴파일 에러가 발생하지않는다.
@Column과 반대로 db 테이블에는 칼럼으로 생성되지 않는 경우에는 @Transient 어노테이션을 사용한다. 또한 @Column으로 기본 값을 지정하기 위해 columnDefinition을 이용하기도 한다.
@Column(columnDefinition = "varchar(255) default'Yes'")
Srping Data JPA를 위한 스프링 부트 설정
데이터베이스 설정과 엔티티 클래스 추가로 프로젝트 실행은 가능하다.
하지만 자동으로 테이블을 생성하거나 JPA를 이용할 때 발생하는 SQL 등을 확인하기 위해서는 약간 추가 설정이 필요하다.
프로젝트 내의 application.properties 파일에 아래의 내용을 추가한다.
spring.jpa.hibernate.ddl-auto=update
spring.jpa.hibernate.format_sql=true
spring.jpa.show-sql=true
추가된 항목은 크게 3가지로 다음과 같다.
- spring.jpa.hibernate.ddl-auto : 프로젝트 실행 시에 자동으로 DDL(create,
alter, drop등)을 생성할 것인지를 결정하는 설정이다. 설정값은 create, update,
create-drop, validate등이 있다. 왠만하면 로컬에서 개발할때만 사용하도록 한다.
(김영한 jpa강의 참고)
- spring.jpa.hibernate.format_sql : 실제 JPA의 구현체인 Hibernate가
동작하면서 발생하는 SQL을 포맷팅해서 출력해준다. SQL의 가독성을 높혀준다.
- spring.jpa.show-sql : JPA 처리 시에 발생하는 SQL을 보여줄 것인지를 결정한다.
SQL 보기옵션은 더 있다. 궁금하면 구글링하기로 한다. (trace, 주석보이기등)
